Join our workshop on AI Use Cases for R Enthusiasts, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: AI Use Cases for R Enthusiasts
Date: Thursday, May 9th, 18:00 – 20:00 CEST (Rome, Berlin, Paris timezone)
Speaker: Dr. Albert Rapp is a mathematician with a fascination for the blend of Data Analytics, Web Development, and Visualization. He applies his expertise as a business analyst, focusing on AI, cloud computing, and data analysis. Outside of his professional pursuits, Albert enjoys engaging with the community by sharing his insights and knowledge on platforms like LinkedIn, YouTube, and through his video courses.
Description: Everyone is talking about AI. And for good reasons: It’s a powerful tool that can enhance your productivity as a programmer as well as help you with automated data processing tasks. In this workshop, I share R-specific and general AI tools and workflows that I use for my programming, blogging and video projects. By the end of this session, participants will be equipped with fresh ideas and practical strategies for using AI in their own endeavors.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting listhere. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!
After some years as a Stata user, I found myself in a new position where the tools available were SQL and SPSS. I was impressed by the power of SQL, but I was unhappy with going back to SPSS after five years with Stata.
Luckily, I got the go-ahead from my leaders at the department to start testing out R as a tool to supplement SQL in data handling.
This was in the beginning of 2020, and by March we were having a social gathering at our workplace. A Bingo night! Which turned out to be the last social event before the pandemic lockdown.
What better opportunity to learn a new programming language than to program some bingo cards! I learnt a lot from this little project.
It uses the packages grid and gridExtra to prepare and embellish the cards.
The function BingoCard draws the cards and is called from the function Bingo3. When Bingo3 is called it runs BingoCard the number of times necessary to create the requested number of sheets and stores the result as a pdf inside a folder defined at the beginning of the script.
All steps could have been added together in a single function. For instance, a more complete function could have included input for the color scheme of the cards, the number of cards on each sheet and more advanced features for where to store the results.
Still, this worked quite well, and was an excellent way of learning since it was both so much fun and gave me the opportunity to talk enthusiastically about R during Bingo Night.
library(gridExtra)
library(grid)
##################################################################
# Be sure to have a folder where results are stored
##################################################################
CardFolder <- "BingoCards"
if (!dir.exists(CardFolder)) {dir.create(CardFolder)}
##################################################################
# Create a theme to use for the cards
##################################################################
thema <- ttheme_minimal(
base_size = 24, padding = unit(c(6, 6), "mm"),
core=list(bg_params = list(fill = rainbow(5),
alpha = 0.5,
col="black"),
fg_params=list(fontface="plain",col="darkblue")),
colhead=list(fg_params=list(col="darkblue")),
rowhead=list(fg_params=list(col="white")))
##################################################################
## Define the function BingoCard
##################################################################
BingoCard <- function() {
B <- sample(1:15, 5, replace=FALSE)
I <- sample(16:30, 5, replace=FALSE)
N <- sample(31:45, 5, replace=FALSE)
G <- sample(46:60, 5, replace=FALSE)
O <- sample(61:75, 5, replace=FALSE)
BingoCard <- as.data.frame(cbind(B,I,N,G,O))
BingoCard[3,"N"]<-"X"
a <- tableGrob(BingoCard, theme = thema)
return(a)
}
##################################################################
## Define the function Bingo3
## The function has two arguments
## By default, 1 sheet with 3 cards is stored in the CardFolder
## The default name is "bingocards.pdf"
## This function calls the BingoCard function
##################################################################
Bingo3 <- function(NumberOfSheets=1, SaveFileName="bingocards") {
myplots <- list()
N <- NumberOfSheets*3
for (i in 1 : N ) {
a1 <- BingoCard()
myplots[[i]] <- a1
}
ml <- marrangeGrob(myplots, nrow=3, ncol=1,top="")
save_here <- paste0(CardFolder,"/",SaveFileName,".pdf")
ggplot2::ggsave(save_here, ml, device = "pdf", width = 210,
height = 297, units = "mm")
}
##################################################################
## Run Bingo3 with default values
##################################################################
Bingo3()
##################################################################
## Run Bingo3 with custom values
##################################################################
Bingo3(NumberOfSheets = 30, SaveFileName = "30_BingoCards")
In previous article, I introduced method to share shiny application in static web page (github page)
At the core of this method is a technology called WASM, which is a way to load and utilize R and Shiny-related libraries and files that have been converted for use in a web browser. The main problem with wasm is that it is difficult to configure, even for R developers.
Of course, there was a way called shinylive, but unfortunately it was only available in python at the time.
Fortunately, after a few months, there is an R package that solves this configuration problem, and I will introduce how to use it to add a shiny application to a static page.
shinylive
shinylive is R package to utilize wasm above shiny. and now it has both Python and R version, and in this article will be based on the R version.
shinylive is responsible for generating HTML, Javascript, CSS, and other elements needed to create web pages, as well as wasm-related files for using shiny.
You can see examples created with shinylive at this link.
Install shinylive
While shinylive is available on CRAN, it is recommended to use the latest version from github as it may be updated from time to time, with the most recent release being 0.1.1. Additionally, pak is the recently recommended R package for installing R packages in posit, and can replace existing functions like install.packages() and remotes::install_github().
You can think of shinylive as adding a wasm to an existing shiny application, which means you need to create a shiny application first.
For the example, we’ll use the code provided by shiny package (which you can also see by typing shiny::runExample("01_hello") in the Rstudio console).
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
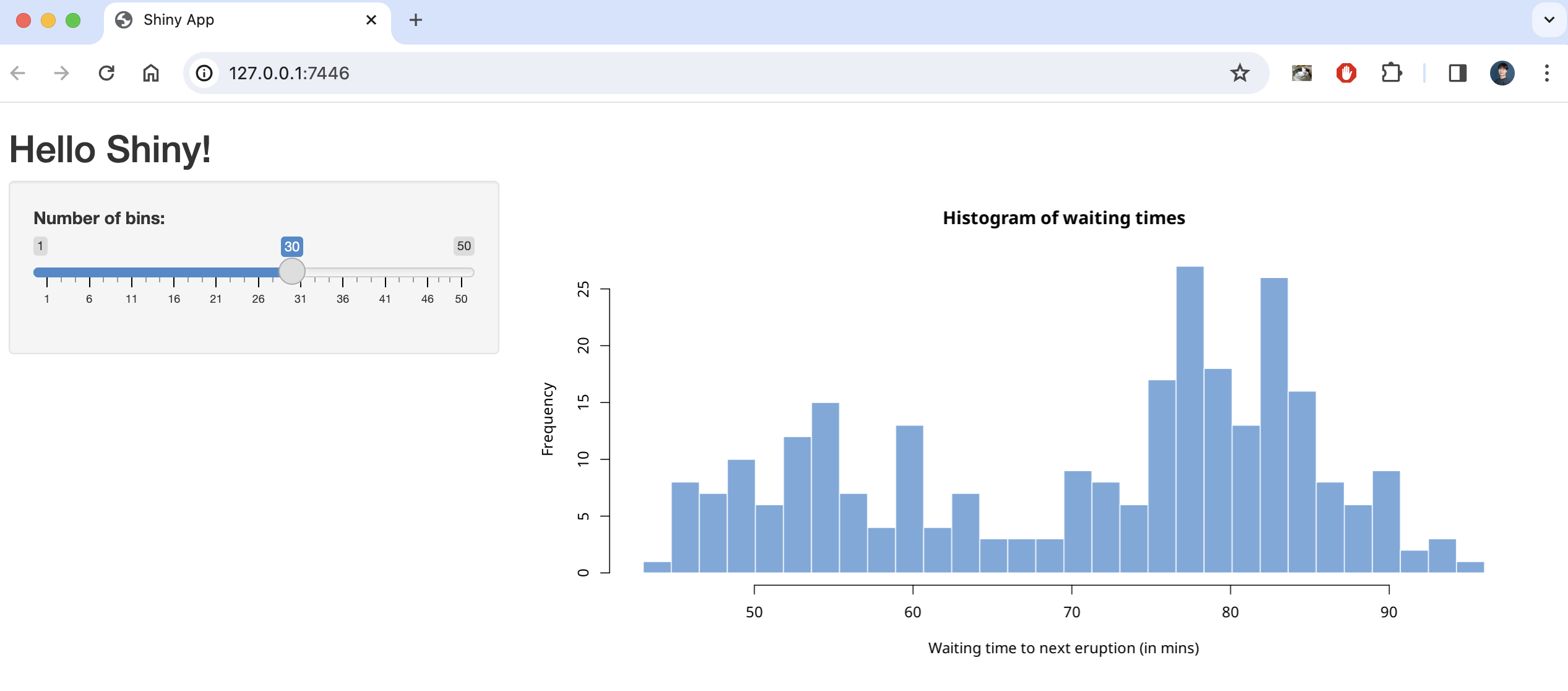
This code creates a simple shiny application that creates a number of histograms in response to the user’s input, as shown below.
There are two ways to create a static page with this code using shinylive, one is to create it as a separate webpage (like previous article) and the other is to embed it as internal content on a quarto blog page .
First, here’s how to create a separate webpage.
shinylive via web page
To serve shiny on a separate static webpage, you’ll need to convert your app.R to a webpage using the shinylive package you installed earlier.
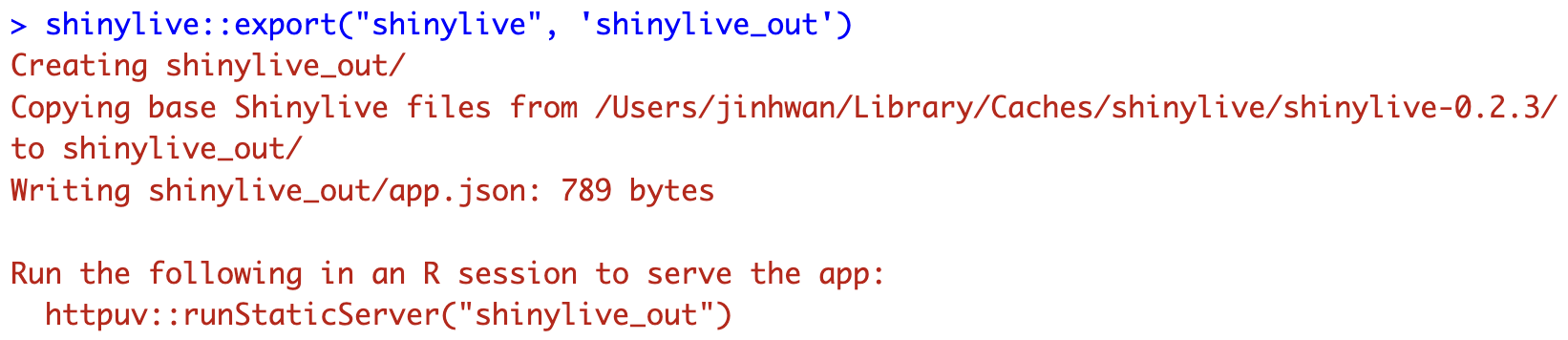
Based on creating a folder named shinylive in my Documents(~/Documents) and saving `app.R` inside it, here’s an example of how the export function would look like shinylive::export('~/Documents/shinylive', '~/Documents/shinylive_out')
When you run this code, it will create a new folder called shinylive_out in the same location as shinylive, (i.e. in My Documents), and inside it, it will generate the converted wasm version of shiny code using the shinylive package.
If you check the contents of this shinylive_out folder, you can see that it contains the webr, service worker, etc. mentioned in the previous post.
More specifically, the export function is responsible for adding the files from the local PC’s shinylive package assets, i.e. the library files related to shiny, to the out directory on the local PC currently running R studio.
Now, if you create a github page or something based on the contents of this folder, you can serve a static webpage that provides shiny, and you can preview the result with the command below.
To add a shiny application to a quarto blog, you need to use a separate extension. The quarto extension is a separate package that extends the functionality of quarto, similar to using R packages to add functionality to basic R.
First, we need to add the quarto extension by running the following code in the terminal (not a console) of Rstudio.
quarto add quarto-ext/shinylive
You don’t need to create a separate file to plant shiny in your quarto blog, you can use a code block called {shinylive-r}. Additionally, you need to set shinylive in the yaml of your index.qmd.
filters:
- shinylive
Then, in the {shinylive-r} block, write the contents of the app.R we created earlier.
#| standalone: true
#| viewerHeight: 800
library(shiny)
ui <- fluidPage(
titlePanel("Hello Shiny!"),
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "bins",
label = "Number of bins:",
min = 1,
max = 50,
value = 30
)
),
mainPanel(
plotOutput(outputId = "distPlot")
)
)
)
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x,
breaks = bins, col = "#75AADB", border = "white",
xlab = "Waiting time to next eruption (in mins)",
main = "Histogram of waiting times"
)
})
}
shinyApp(ui = ui, server = server)
after add this in quarto blog, you may see working shiny application.
shinylive is a feature that utilizes wasm to run shiny on static pages, such as GitHub pages or quarto blogs, and is available as an R package and quarto extension, respectively.
Of course, since it is less than a year old, not all features are available, and since it uses static pages, there are disadvantages compared to utilizing a separate shiny server.
However, it is very popular for introducing shiny usage and simple statistical analysis, and you can practice it right on the website without installing R, and more features are expected to be added in the future.
The code used in blog (previous example link) can be found at the link.
Join our workshop on Introduction to Causal Machine Learning estimators in R, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: Introduction to Causal Machine Learning estimators in R
Date: Thursday, April 11th, 18:00 – 20:00 CET (Rome, Berlin, Paris timezone)
Speaker: Michael Knaus is Assistant Professor of “Data Science in Economics” at the University of Tübingen. He is working at the intersection of causal inference and machine learning for policy evaluation and recommendation.
Description: You want to learn about Double Machine Learning and/or Causal Forests for causal effect estimation but are hesitant to start because of the heavy formulas involved? Or you are already using them and curious to (better) understand what happens under the hood? In this course, we take a code first, formulas second approach. You will see how to manually replicate the output of the powerful DoubleML and grf packages using at most five lines of code and nothing more than OLS. After seeing that everything boils down to simple recipes, the involved formulas will look more friendly. The course establishes therefore how things work and gives references to further understand why things work.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting listhere. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!
WhatsApp is one of the most heavily used mobile instant messaging applications around the world. It is especially popular for everyday communication with friends and family and most users communicate on a daily or a weekly basis through the app. Interestingly, it is possible for WhatsApp users to extract a log file from each of their chats. This log file contains all textual communication in the chat that was not manually deleted or is not too far in the past.
This logging of digital communication is on the one hand interesting for researchers seeking to investigate interpersonal communication, social relationships, and linguistics, and can on the other hand also be interesting for individuals seeking to learn more about their own chatting behavior (or their social relationships).
The WhatsR R-package enables users to transform exported WhatsApp chat logs into a usable data frame object with one row per sent message and multiple variables of interest. In this blog post, I will demonstrate how the package can be used to process and visualize chat log files.
Installing the Package The package can either be installed via CRAN or via GitHub for the most up-to-date version. I recommend to install the GitHub version for the most recent features and bugfixes.
# from CRAN
# install.packages("WhatsR")
# from GitHub
devtools::install_github("gesiscss/WhatsR")
The package also needs to be attached before it can be used. For creating nicer plots, I recommend to also install and attach the patchwork package.
Obtaining a Chat Log You can export one of your own chat logs from your phone to your email address as explained in this tutorial. If you do this, I recommend to use the “without media” export option as this allows you to export more messages.
If you don’t want to use one of your own chat logs, you can create an artificial chat log with the same structure as a real one but with made up text using the WhatsR package!
## creating chat log for demonstration purposes
# setting seed for reproducibility
set.seed(1234)
# simulating chat log
# (and saving it automatically as a .txt file in the working directory)
create_chatlog(n_messages = 20000,
n_chatters = 5,
n_emoji = 5000,
n_diff_emoji = 50,
n_links = 999,
n_locations = 500,
n_smilies = 2500,
n_diff_smilies = 10,
n_media = 999,
n_sdp = 300,
startdate = "01.01.2019",
enddate = "31.12.2023",
language = "english",
time_format = "24h",
os = "android",
path = getwd(),
chatname = "Simulated_WhatsR_chatlog")
Parsing Chat Log File Once you have a chat log on your device, you can use the WhatsR package to import the chat log and parse it into a usable data frame structure.
data <- parse_chat("Simulated_WhatsR_chatlog.txt", verbose = TRUE)
Checking the parsed Chat Log You should now have a data frame object with one row per sent message and 19 variables with information extracted from the individual messages. For a detailed overview what each column contains and how it is computed, you can check the related open source publication for the package. We also add a tabular overview here.
## Checking the chat log
dim(data)
colnames(data)
Column Name
Description
DateTime
Timestamp for date and time the message was sent. Formatted as yyyy-mm-dd hh:mm:ss
Sender
Name of the sender of the message as saved in the contact list of the exporting phone or telephone number. Messages inserted by WhatsApp into the chat are coded with “WhatsApp System Message”
Message
Text of user-generated messages with all information contained in the exported chat log
Flat
Simplified version of the message with emojis, numbers, punctuation, and URLs removed. Better suited for some text mining or machine learning tasks
TokVec
Tokenized version of the Flat column. Instead of one text string, each cell contains a list of individual words. Better suited for some text mining or machine learning tasks
URL
A list of all URLs or domains contained in the message body
Media
A list of all media attachment filenames contained in the message body
Location
A list of all shared location URLs or indicators in the message body, or indicators for shared live locations
Emoji
A list of all emoji glyphs contained in the message body
EmojiDescriptions
A list of all emojis as textual representations contained in the message body
Smilies
A list of all smileys contained in the message body
SystemMessage
Messages that are inserted by WhatsApp into the conversation and not generated by users
TokCount
Amount of user-generated tokens per message
TimeOrder
Order of messages as per the timestamps on the exporting phone
DisplayOrder
Order of messages as they appear in the exported chat log
Checking Descriptives of Chat Logs Now, you can have a first look at the overall statistics of the chat log. You can check the number of messages, sent tokens, number of chat participants, date of first message, date of last message, the timespan of the chat, and the number of emoji, smilies, links, media files, as well as locations in the chat log.
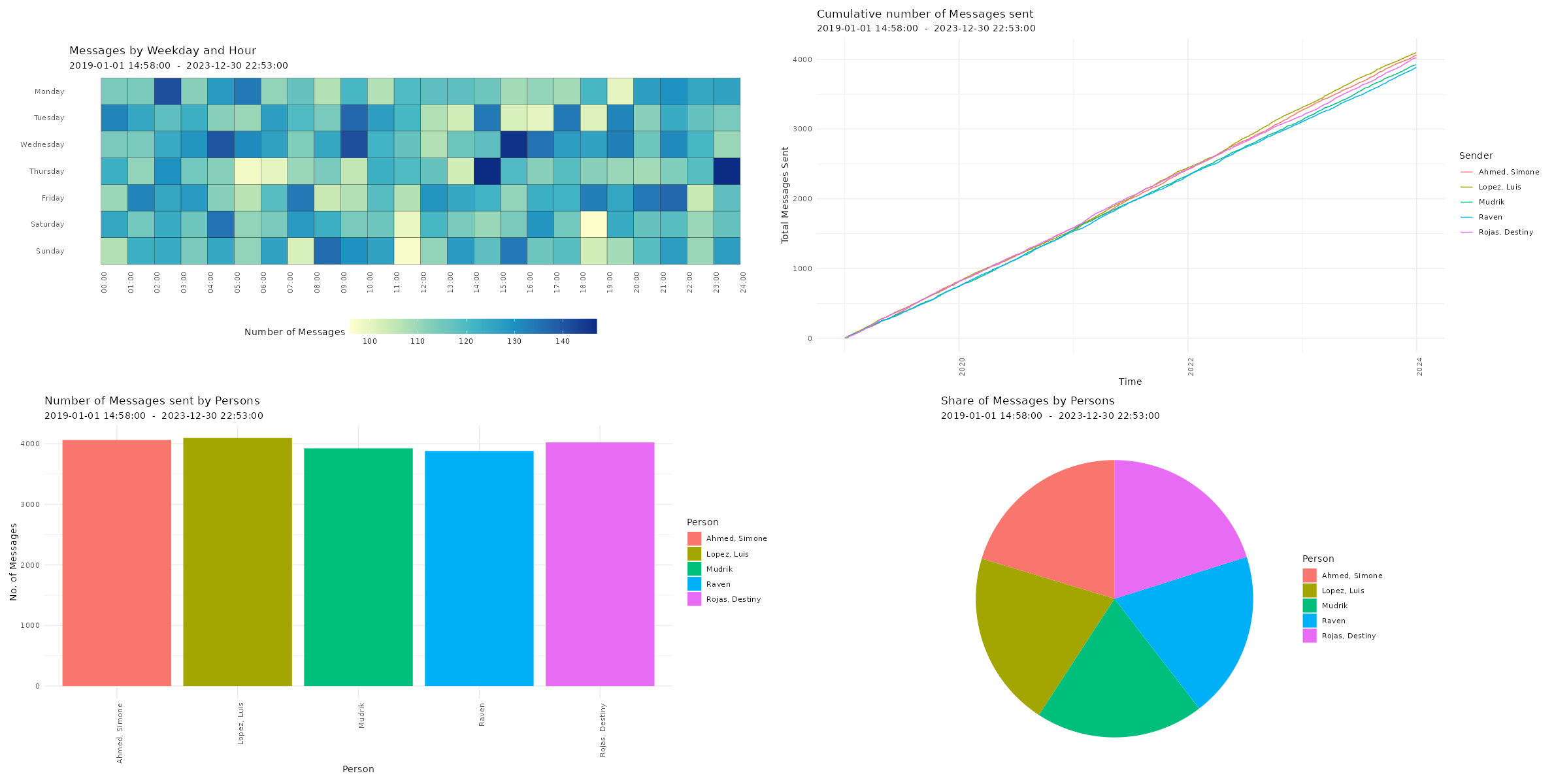
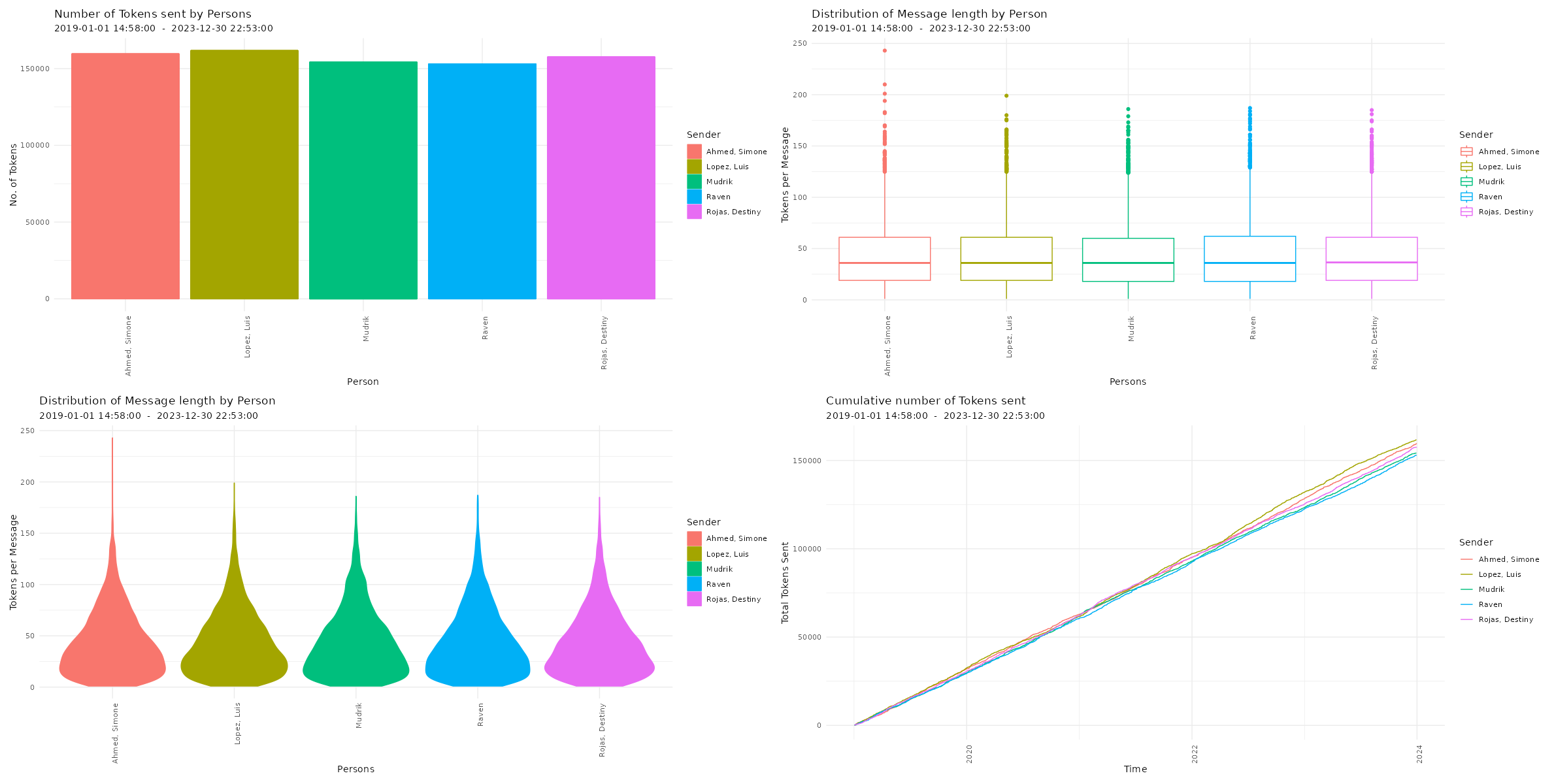
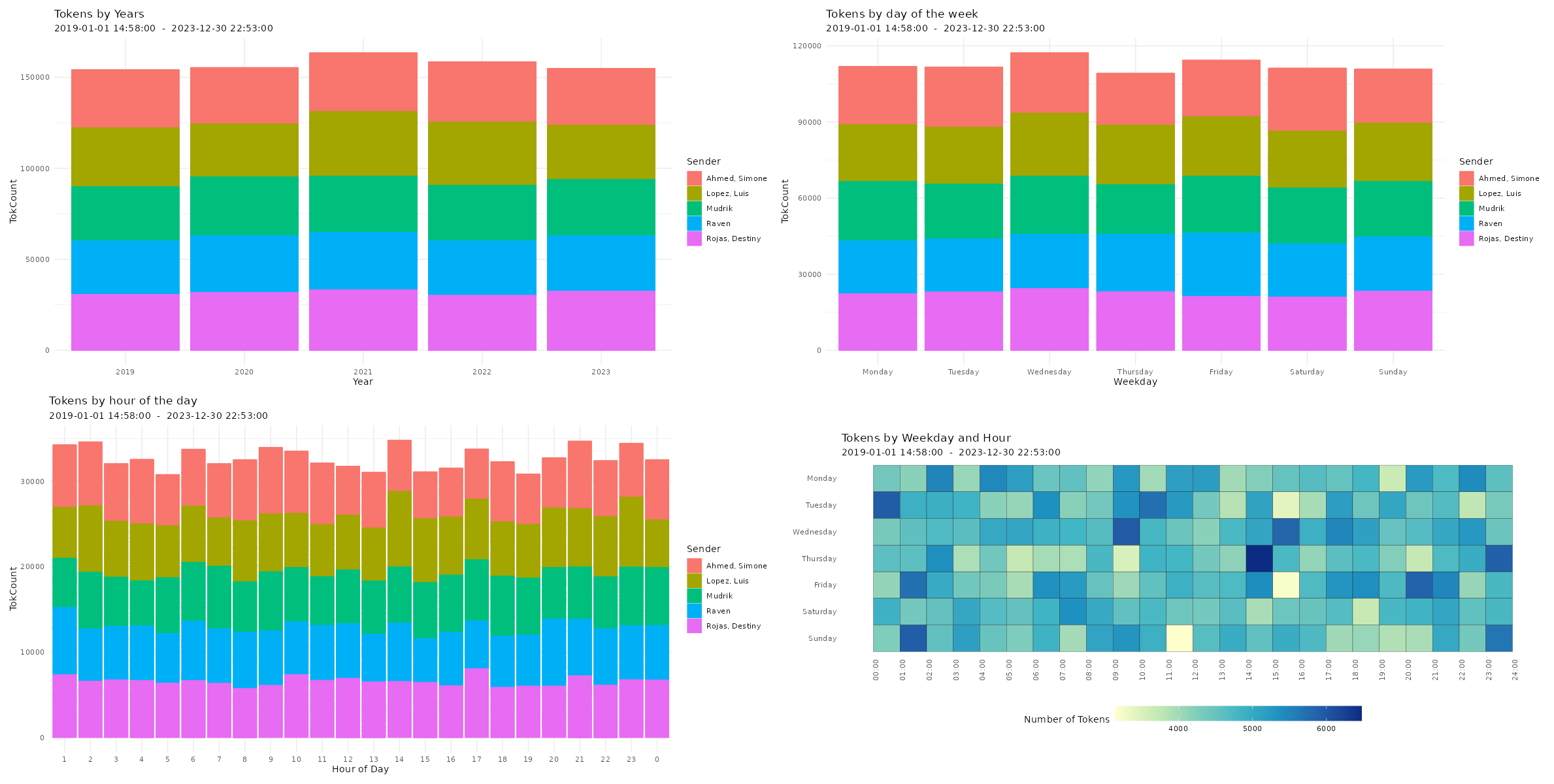
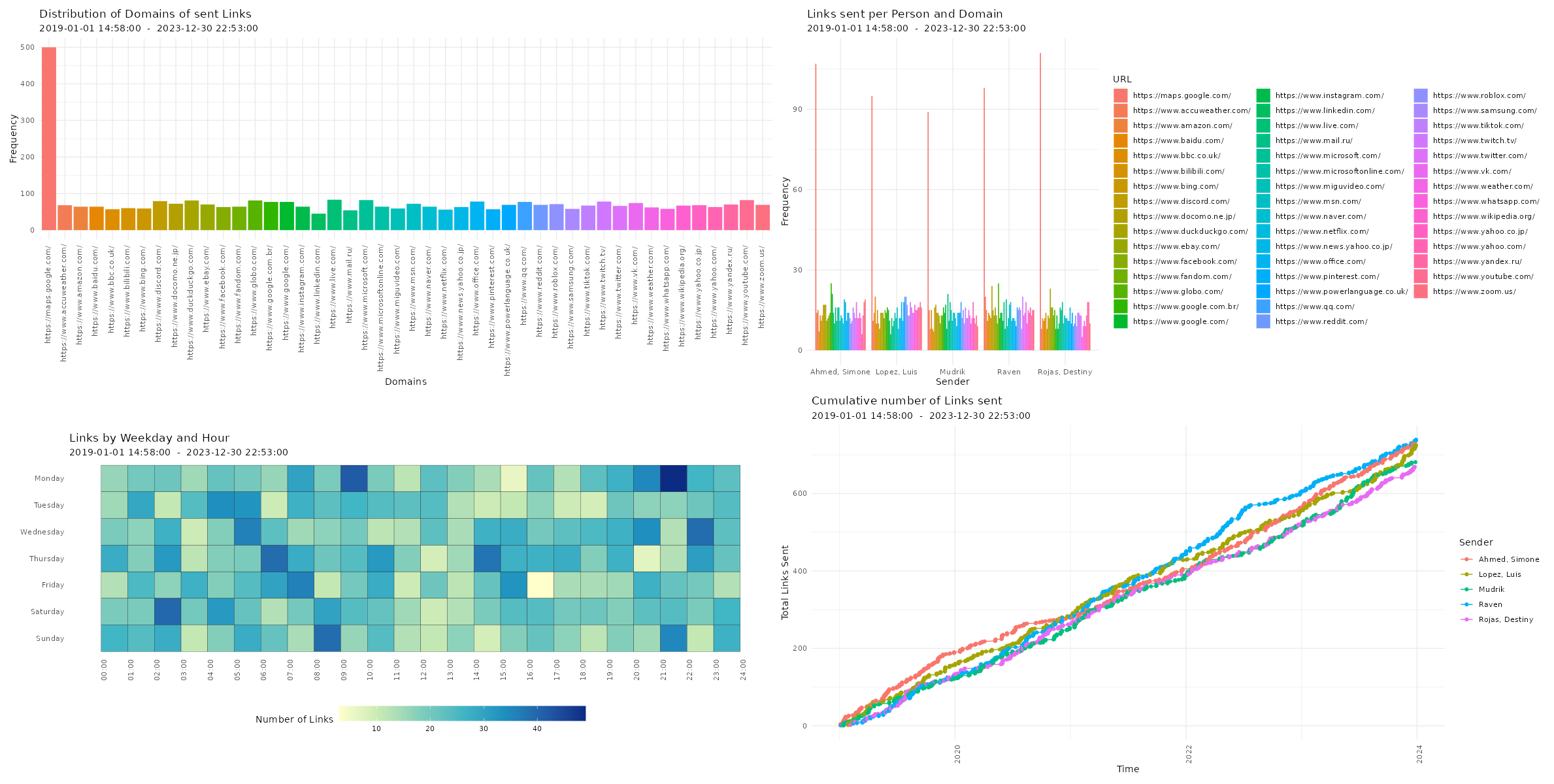
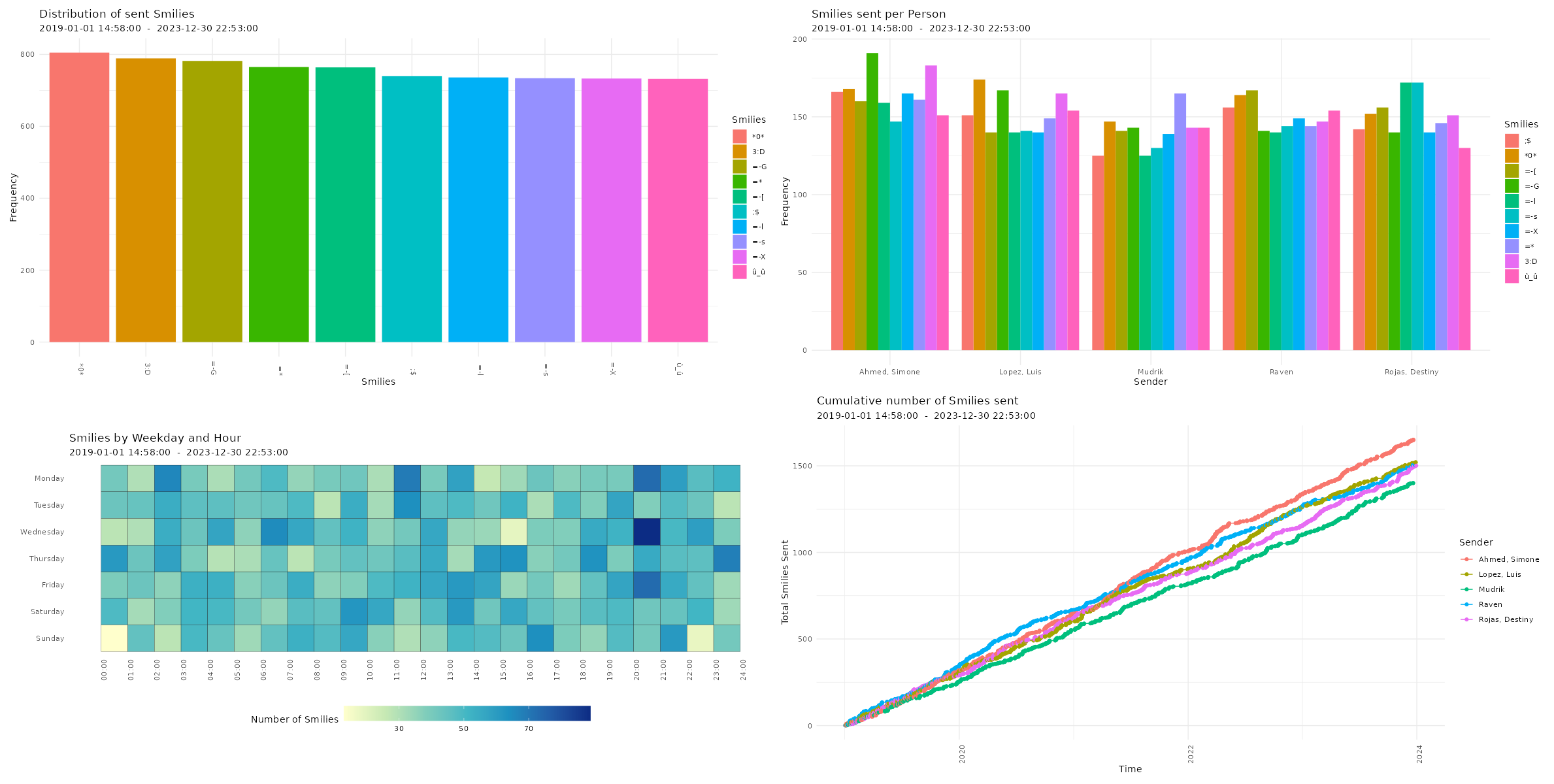
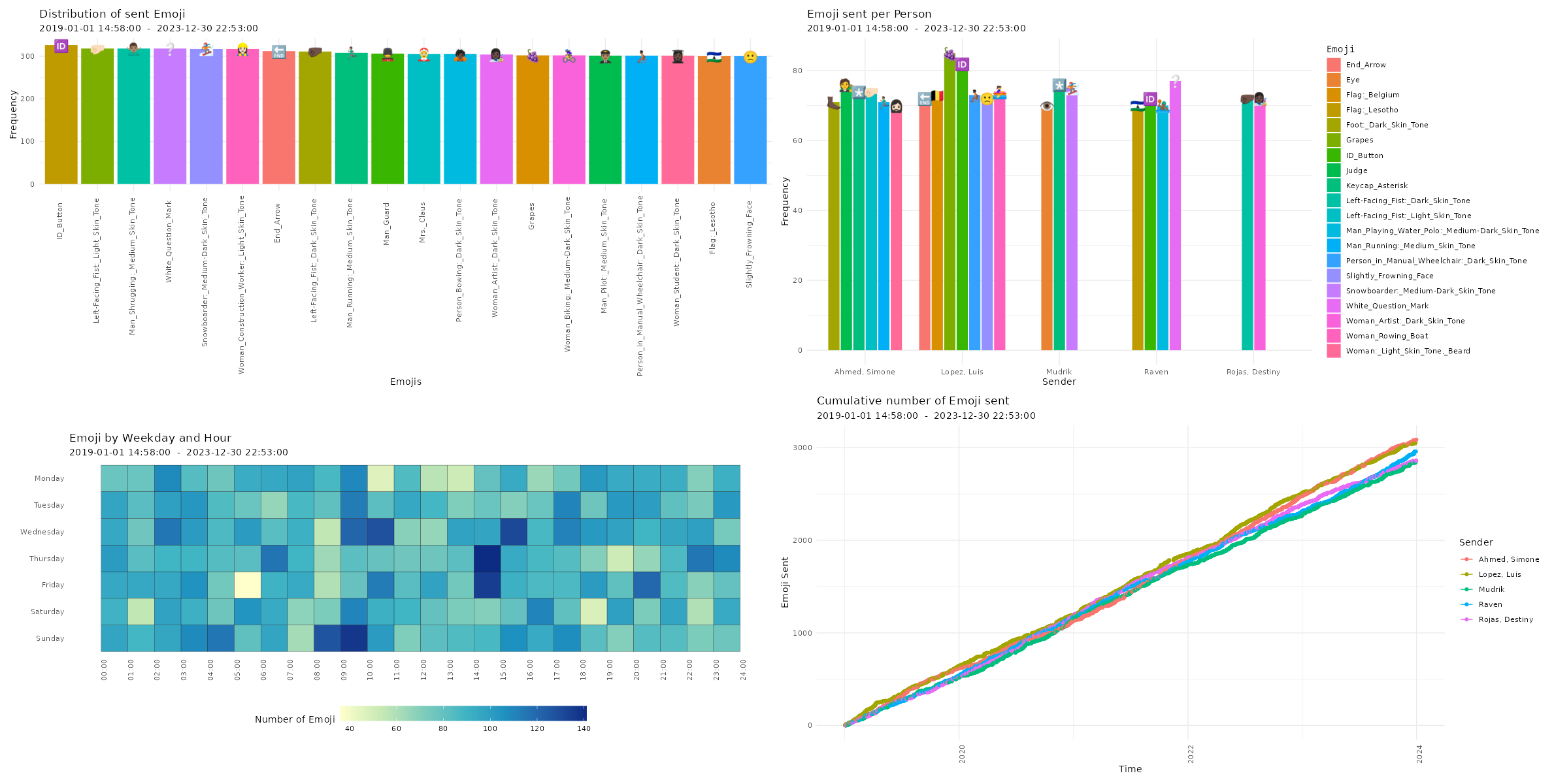
Visualizing Chat Logs The chat characteristics can now be visualized using the custom functions from the WhatsR package. These functions are basically wrappers to ggplot2 with some options for customizing the plots. Most plots have multiple ways of visualizing the data. For the visualizations, we can exclude the WhatsApp System Messages using ‘exclude_sm= TRUE’. Lets try it out:
Four different ways of visualizing the amount of sent emoji in a WhatsApp chat log. Click image to zoom in. Distribution of reaction times
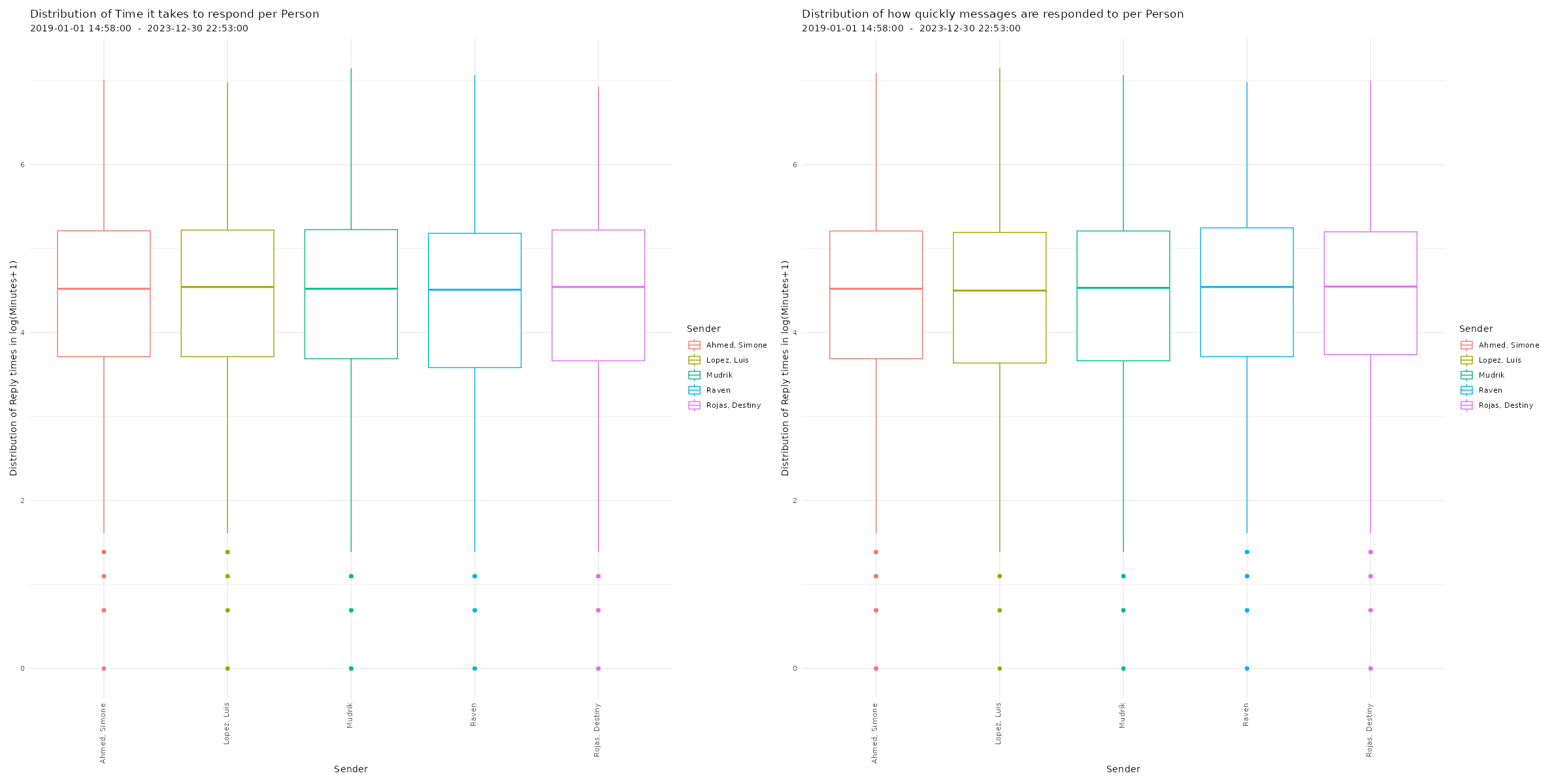
# Plotting distribution of reaction times
p26 <- plot_replytimes(data,
type = "replytime",
exclude_sm = TRUE)
p27 <- plot_replytimes(data,
type = "reactiontime",
exclude_sm = TRUE)
# Printing plots with patchwork package
free(p26) | free(p27)
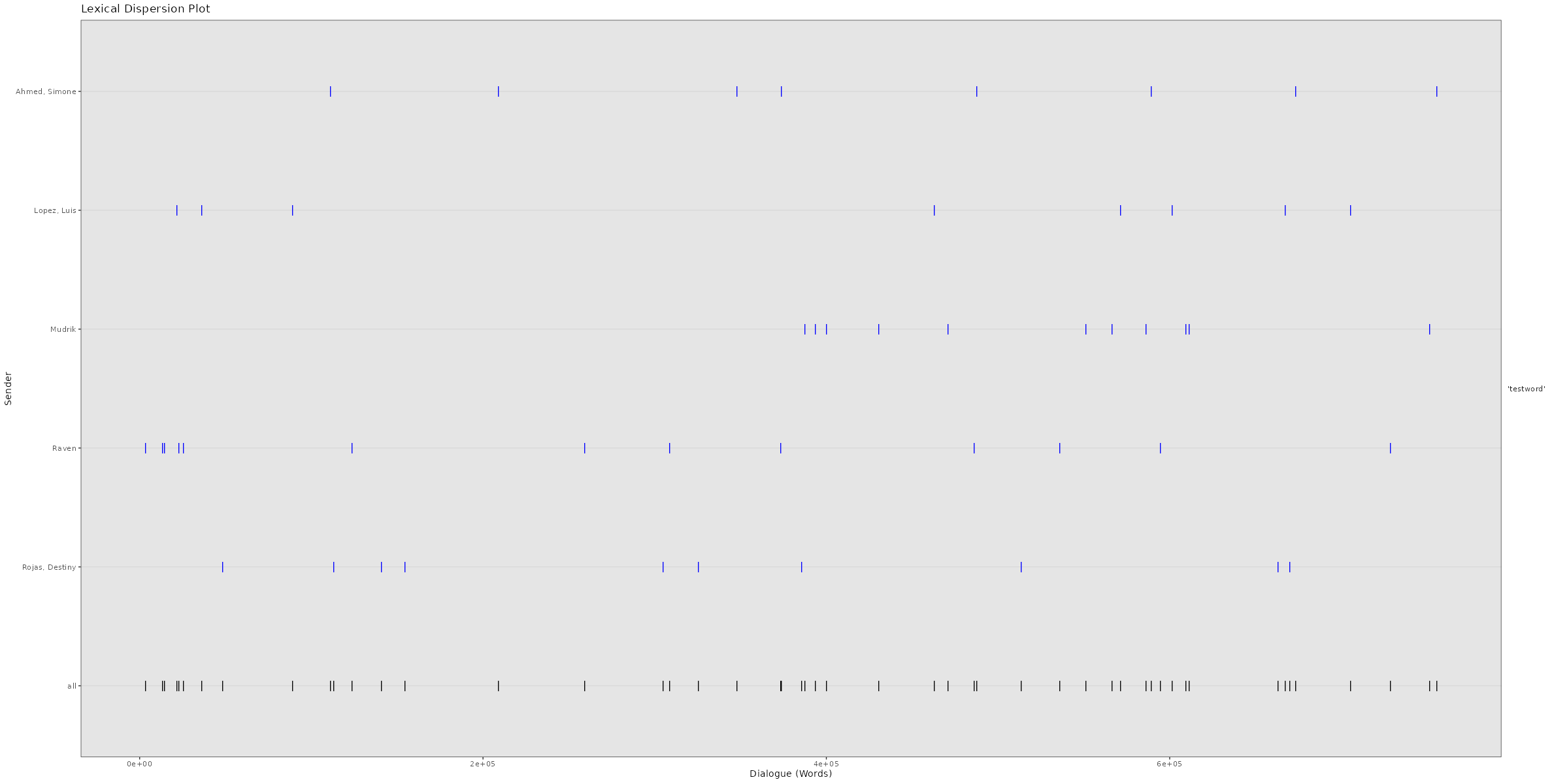
Average response times and times it takes to answer to messages for each individual chat participant in a WhatsApp chat log. Click image to zoom in. Lexical Dispersion A lexical dispersion plot is a visualization of where specific words occur within a text corpus. Because the simulated chat log in this example is using lorem ipsum text where all words occur similarly often, we add the string “testword” to a random subsample of messages. For visualizing real chat logs, this would of course not be necessary.
# Adding "testword" to random subset of messages for demonstration # purposes
set.seed(12345)
word_additions <- sample(dim(data)[1],50)
data$TokVec[word_additions]
sapply(data$TokVec[word_additions],function(x){c(x,"testword")})
data$Flat[word_additions] <- sapply(data$Flat[word_additions],
function(x){x <- paste(x,"testword");return(x)})
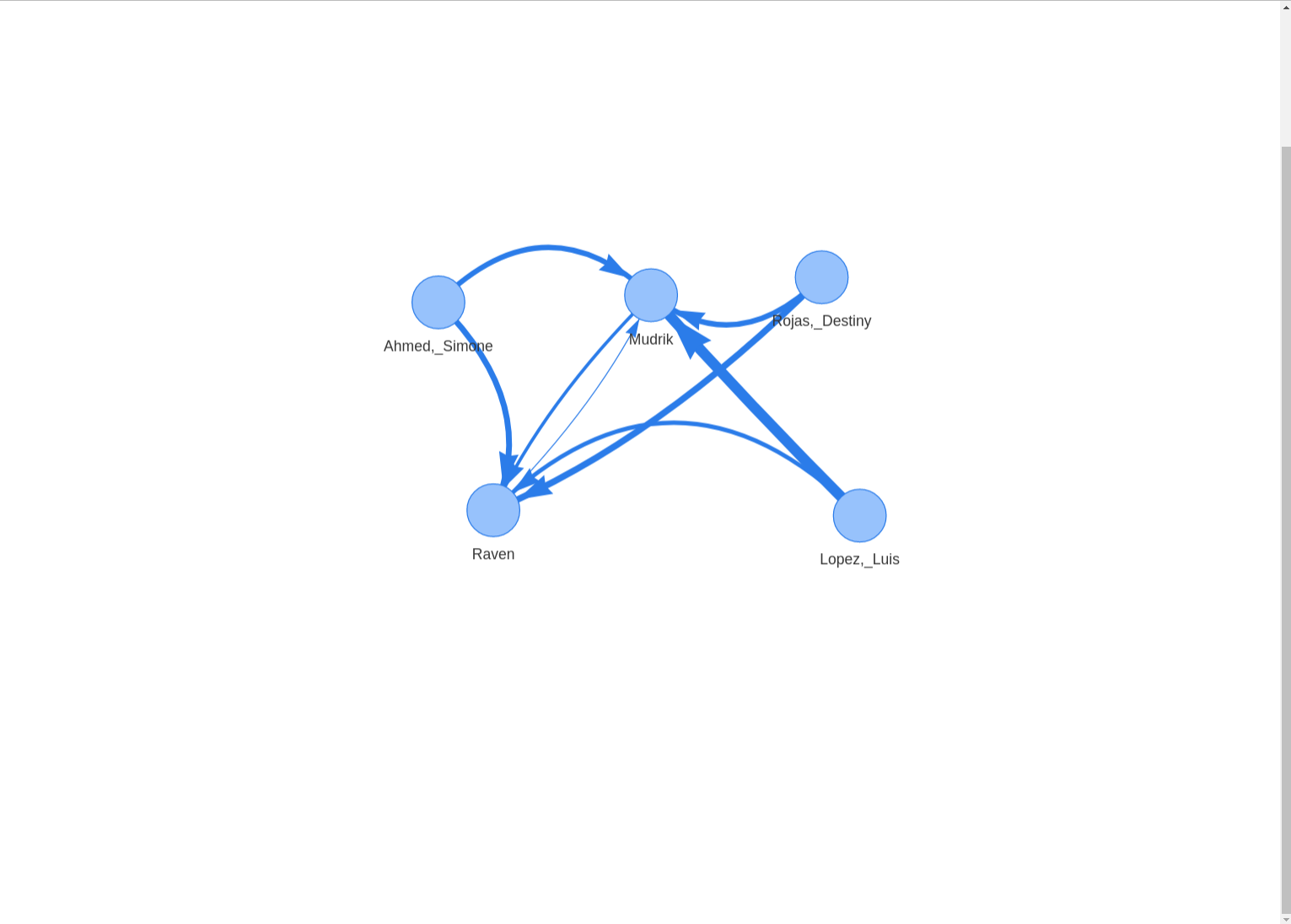
Network graph showing how often each chat participant directly responded to the previous messages (a subsequent message is counted as a “response” here). Click image to zoom in.
Issues and long-term availability.
Unfortunately, WhatsApp chat logs are a moving target when it comes to plotting and visualization. The structure of exported WhatsApp chat logs keeps changing from time to time. On top of that, the structure of chat logs is different for chats exported from different operating systems (Android & iOS) and for different time (am/pm vs. 24h format) and language (e.g. English & German) settings on the exporting phone. When the structure changes, the WhatsR package can be limited in its functionality or become completely dysfunctional until it is updated and tested. Should you encounter any issues, all reports on the GitHub issues page are welcome. Should you want to contribute to improving on or maintaining the package, pull requests and collaborations are also welcome!
Join our workshop on Creating R packages for data analysis and reproducible research, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: Creating R packages for data analysis and reproducible research
Date: Thursday, February 29th, 18:00 – 20:00 CET (Rome, Berlin, Paris timezone)
Speaker: Fred Boehm is a biostatistics and translational medicine researcher living in Michigan, USA. His research focuses on statistical questions that arise in human genetics studies and their applications to clinical medicine and public health. He has extensive teaching experience as a statistics lecturer at the University of Wisconsin-Madison (https://www.wisc.edu) and as a workshop instructor for The Carpentries (https://carpentries.org/index.html). He enjoys spending time with his nieces and nephews and his two dogs. He also blogs (occasionally) at https://fboehm.us/blog/.
Description: Participants will learn to use functions from several packages, including `devtools` and `rrtools`, in the R ecosystem, while learning and adhering to practices to promote reproducible research. Participants will learn to create their own R packages for software development or data analysis. We will also motivate the need to follow reproducible research practices and will discuss strategies and open source tools.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting listhere. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!
Join our workshop onModeling Non-Linear Relationships: An Introduction to Gaussian Process Regression in R and Stan, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: Modeling Non-Linear Relationships: An Introduction to Gaussian Process Regression in R and Stan
Date: Thursday, February 13th, 18:00 – 20:00 CET (Rome, Berlin, Paris timezone)
Speaker: Jan Failenschmid is a Ph.D. candidate in Psychological Research Methods and Statistics at Tilburg University, Netherlands. His research focusses on studying and developing methods for modeling and analyzing non-linear trends and dynamics in psychological time-series and intensive longitudinal data. Given the scarcity of established theories about non-linear associations in Psychology, his work focusses mainly on non-parametric statistical techniques like Gaussian Processes, which make it possible to learn complex non-linear relationships from data while providing interpretable insights.
Description: This workshop will provide an introduction to Gaussian Process regression, a flexible and powerful Bayesian non-parametric technique, for modeling non-linear relationships in R and Stan. The Workshop will start by providing a brief introduction to Bayesian statistics, including the principles underlying Bayesian inference and its implementation in Stan. Building on this foundation, we will delve into Gaussian Processes, exploring their conceptual framework and practical applications. The final part of the workshop will feature hands-on examples illustrating different applications to the kinds of data found in the social and behavioral sciences.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
Please note that the registration confirmation email will be sent 1 day before the workshop.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting listhere. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!
Excitement is building as we approach ShinyConf 2024, organized by Appsilon. We are thrilled to announce the Call for Speakers. This is a unique opportunity for experts, industry leaders, and enthusiasts to disseminate their knowledge, insights, and expertise to a diverse and engaged audience.
Why Speak at ShinyConf?
Becoming a speaker at ShinyConf is not just about sharing your expertise; it’s about enriching the community, networking with peers, and contributing to the growth and innovation in your field. It’s an experience that extends beyond the conference, fostering a sense of camaraderie and collaboration among professionals.
Conference Tracks
ShinyConf 2024 features several tracks, each tailored to different aspects of our industry. Our track chairs, experts in their respective fields, will guide these sessions.
Shiny Innovation Hub – Led by Jakub Nowicki, Lab Lead at Appsilon, this track focuses on the latest developments and creative applications within the R Shiny framework. We’re looking for talks on advanced Shiny programming techniques, case studies, and how Shiny drives data communication advancements.
Shiny in Enterprise – Chaired by Maria Grycuk, Senior Delivery Manager at Appsilon. This track delves into R Shiny’s role in shaping business outcomes, including case studies, benefits and challenges in enterprise environments, and integration strategies.
Shiny in Life Sciences – Guided by Eric Nantz, a Statistician/Developer/Podcaster. This track focuses on R Shiny’s application in data science and life sciences, including interactive visualization, drug discovery, and clinical research.
Shiny for Good – Overseen by Jon Harmon, Data Science Leader and Expert R Programmer. This track highlights R Shiny’s impact on social good, community initiatives, and strategies for engaging diverse communities.
Submission Guidelines
Topics of Interest: Tailored to each track, ranging from advanced programming techniques to real-world applications in life sciences, social good and enterprise.
Submission Types:
Talks (20 min)
Shiny app showcases (5 min)
Tutorials (40 min)
Who Can Apply: Open to both seasoned and new speakers. Unsure about your idea? Submit it anyway!
Join us at the Shiny Conf as a speaker and shine! We look forward to receiving your submissions and creating an inspiring and educational event together.
Follow us on social media (LinkedIn and Twitter) for updates. Registration opens this month! Contact us at [email protected] for any queries.
Useful Links
Join our community, Shiny 4 All, to keep up with the latest updates
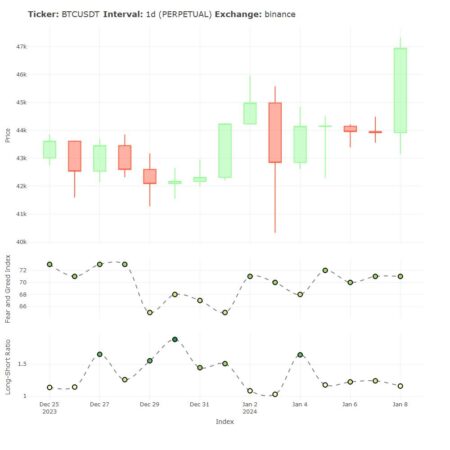
Navigating the volatile world of cryptocurrencies requires a keen understanding of market sentiment. This blog post explores some of the essential tools and techniques for analyzing the mood of the crypto market, using the cryptoQuotes-package.
The Cryptocurrency Fear and Greed Index in R
The Fear and Greed Index is a market sentiment tool that measures investor emotions, ranging from 0 (extreme fear) to 100 (extreme greed). It analyzes data like volatility, market momentum, and social media trends to indicate potential overvaluation or undervaluation of cryptocurrencies. This index helps investors identify potential buying or selling opportunities by gauging the market’s emotional extremes.
This index can be retrieved by using the cryptoQuotes::getFGIndex()-function, which returns the daily index within a specified time-frame,
## Fear and Greed Index
## from the last 14 days
tail(
FGI <- cryptoQuotes::getFGIndex(
from = Sys.Date() - 14
)
)
#> FGI
#> 2024-01-03 70
#> 2024-01-04 68
#> 2024-01-05 72
#> 2024-01-06 70
#> 2024-01-07 71
#> 2024-01-08 71
The Long-Short Ratio of a Cryptocurrency Pair in R
The Long-Short Ratio is a financial metric indicating market sentiment by comparing the number of long positions (bets on price increases) against short positions (bets on price decreases) for an asset. A higher ratio signals bullish sentiment, while a lower ratio suggests bearish sentiment, guiding traders in making informed decisions.
The Long-Short Ratio can be retrieved by using the cryptoQuotes::getLSRatio()-function, which returns the ratio within a specified time-frame and granularity. Below is an example using the Daily Long-Short Ratio on Bitcoin (BTC),
## Long-Short Ratio
## from the last 14 days
tail(
LSR <- cryptoQuotes::getLSRatio(
ticker = "BTCUSDT",
interval = '1d',
from = Sys.Date() - 14
)
)
#> Long Short LSRatio
#> 2024-01-03 0.5069 0.4931 1.0280
#> 2024-01-04 0.6219 0.3781 1.6448
#> 2024-01-05 0.5401 0.4599 1.1744
#> 2024-01-06 0.5499 0.4501 1.2217
#> 2024-01-07 0.5533 0.4467 1.2386
#> 2024-01-08 0.5364 0.4636 1.1570
Putting it all together
Even though cryptoQuotes::getLSRatio() is an asset-specific sentiment indicator, and cryptoQuotes::getFGIndex() is a general sentiment indicator, there is much information to be gathered by combining this information.
This information can be visualized by using the the various charting-functions in the cryptoQuotes-package,
## get the BTCUSDT
## pair from the last 14 days
BTCUSDT <- cryptoQuotes::getQuote(
ticker = "BTCUSDT",
interval = "1d",
from = Sys.Date() - 14
)
Note: The latest price may vary depending on time of publication relative to the rendering time of the document. This document were rendered at 2024-01-08 23:30 CET
Join our workshop on Factor Analysis in R, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: Factor Analysis in R
Date: Thursday, February 1st, 18:00 – 20:00 CET (Rome, Berlin, Paris timezone)
Speaker: Gagan Atreya is a quantitative social scientist and data science consultant based in Los Angeles, California. He has graduate degrees in Experimental Psychology and Quantitative Political Science from The College of William & Mary in Virginia and The University of Minnesota respectively. He has multiple years of experience in data analysis and visualization in the social sciences – both as a researcher and a consultant with faculty and researchers around the world. You can find him in Bluesky at @gaganatreya.bsky.social.
Description:This workshop will go through the basics of Exploratory and Confirmatory Factor Analysis in the R programming language. Factor Analysis is a valuable statistical technique widely used in Psychology, Economics, Political Science, and related disciplines that allows us to uncover the underlying structure of our data by reducing it to coherent factors. The workshop will heavily (but not exclusively) utilize the “psych” and “lavaan” packages in R. Although open to everyone, a beginner level familiarity with R and some background/interest in survey data analysis will be ideal to make the most out of this workshop.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting listhere. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!