Simple Data Science (R) covers the fundamentals of data science and machine learning. The book is beginner-friendly and has detailed code examples. It is available at scribd.
By Beth Milhollin, Russell Zaretzki, and Audris Mockus
Coke vs. Pepsi is an age-old rivalry, but I am from Atlanta, so it’s Coke for me. Coca-Cola, to be exact. But I am relatively new to R, so when it comes to data.table vs. tidy, I am open to input from experienced users. A group of researchers at the University of Tennessee recently sent out a survey to R users identified by their commits to repositories, such as GitHub. The results of the full survey can be seen here. The project contributors were identified as “data.table” users or “tidy” users by their inclusion of these R libraries in their projects. Both libraries are an answer to some of the limitations associated with the basic R data frame. In the first installment of this series (found here) we used the survey data to calculate the Net Promoter Score for data.table and tidy.
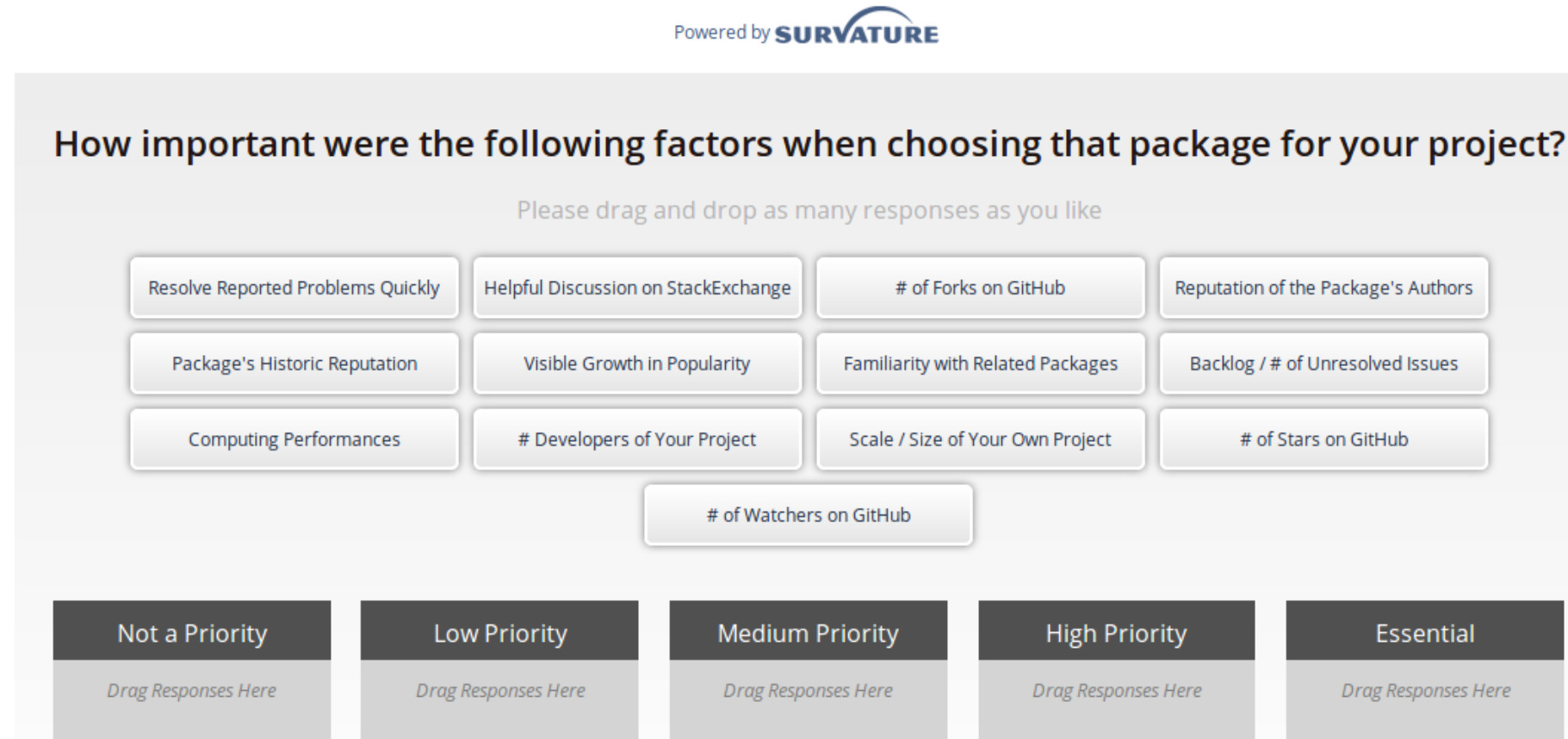
To recap, the Net Promoter Score (NPS) is a measure of consumer enthusiasm for a product or service based on a single survey question – “How likely are you to recommend the brand to your friends or colleagues, using a scale from 0 to 10?” Detractors of the product will respond with a 0-6, while promoters of the product will offer up a 9 or 10. A passive user will answer with a score of 7 or 8. To calculate the NPS, subtract the percentage of detractors from the percentage of promoters. When the percentage of promoters exceeds the percentage of detractors, there is potential to expand market share as the negative chatter is drowned out by the accolades.We were surprised when our survey results indicated data.table had an NPS of 28.6, while tidy’s NPS was double, at 59.4. Why are tidy user’s so much more enthusiastic? What do tidy-lovers “love” about their dataframe enhancement choice? Fortunately, a few of the other survey questions may offer some insights.The survey question shown below asks the respondents how important 13 common factors were when selecting their package. Respondents select a factor-tile, such as “Package’s Historic Reputation”, and drag it to the box that presents the priority that user places on that factor. A user can select/drag as many or as few tiles as they choose.
In my daily work I often have to transform a long table to a wide matrix so accommodate some function. At some stage in my life I came across the reshape2 package, and I have been with that philosophy ever since – I find it makes data wrangling easy and straight forward. I particularly like the tidyverse philosophy where data should be in a long table, where one row is an observation, and a column a parameter. It just makes sense.
However, I quite often have to transform the data into another format, a wide matrix especially for functions of the vegan package, and one day I wondering how to do that in the fastest way.
The code to create the test sets and benchmark the functions is in section ‘Settings and script’ at the end of this document.
I created several data sets that mimic the data I usually work with in terms of size and values. The data sets have 2 to 10 groups, where each group can have up to 50000, 100000, 150000, or 200000 samples. The methods xtabs() from base R, dcast() from data.table, dMcast() from Matrix.utils, and spread() from tidyr were benchmarked using microbenchmark() from the package microbenchmark. Each method was evaluated 10 times on the same data set, which was repeated for 10 randomly generated data sets.
After the 10 x 10 repetitions of casting from long to wide it is clear the spread() is the worst. This is clear when we focus on the size (figure 1). Figure 1. Runtime for 100 repetitions of data sets of different size and complexity.
And the complexity (figure 2). Figure 2. Runtime for 100 repetitions of data sets of different complexity and size.
Close up on the top three methods
Casting from a long table to a wide matrix is clearly slowest with spread(), where as the remaining look somewhat similar. A direct comparison of the methods show a similarity in their performance, with dMcast() from the package Matrix.utils being better — especially with the large and more complex tables (figure 3). Figure 3. Direct comparison of set size.
I am aware, that it might be to much to assume linearity, between the computation times at different set sizes, but I do believe it captures the point – dMcast() and dcast() are similar, with advantage to dMcast() for large data sets with large number of groups. It does, however, look like dcast() scales better with the complexity (figure 4). Figure 4. Direct comparison of number groups.