
Introduction
To reason rigorously under uncertainty we need to invoke the language of probability (Zhang et al. 2020). Any model that falls short of providing quantification of the uncertainty attached to its outcome is likely to yield an incomplete and potentially misleading picture. While this is an irrevocable consensus in statistics, a common misconception, albeit a very persistent one, is that machine learning models usually lack proper ways of quantifying uncertainty. Despite the fact that the two terms exist in parallel and are used interchangeably, the perception that machine learning and statistics imply a non-overlapping set of techniques remains lively, both among practitioners and academics. This is vividly portrayed by the provocatively (and potentially tongue-in-cheek) statement of Brian D. Ripley that ‘machine learning is statistics minus any checking of models and assumptions‘ that he made during the useR! 2004, Vienna conference that served to illustrate the difference between machine learning and statistics.
In fact, the relationship between statistics and machine learning is artificially complicated by such statements and is unfortunate at best, as it implies a profound and qualitative distinction between the two disciplines (Januschowski et al. 2020). The paper by Breiman (2001) is a noticeable exception, as it proposes to differentiate the two based on scientific culture, rather than on methods alone. While the approaches discussed in Breiman (2001) are an admissible partitioning of the space of how to analyse and model data, more recent advances have gradually made this distinction less clear-cut. In fact, the current research trend in both statistics and machine learning gravitates towards bringing both disciplines closer together. In an era of increasing necessity that the output of prediction models needs to be turned into explainable and reliable insights, this is an exceedingly promising and encouraging development, as both disciplines have much to learn from each other. Along with Januschowski et al. (2020), we argue that it is more constructive to seek common ground than it is to introduce artificial boundaries.
In order to further closing the gap between the two cultures, we propose a new framework of the eminent XGBoost that predicts the entire conditional distribution of a univariate response variable. We term our model XGBoostLSS, as it combines the accuracy and speed of XGBoost with the flexibility and interpretability of GAMLSS that allow for the estimation and prediction of the entire conditional distribution. In particular, XGBoostLSS models all moments of a parametric distribution (i.e., mean, location, scale and shape [LSS]) instead of the conditional mean only. XGBoostLSS allows the user to choose from a wide range of continuous, discrete and mixed discrete-continuous distributions to better adapt to the data at hand, as well as to provide predictive distributions, from which prediction intervals and quantiles can be derived.
Applications
In the following, we present both a simulation study and a real-world example that demonstrate the functionality of XGBoostLSS.
Simulation
We start with a simulated a data set that exhibits heteroskedasticity, where the interest lies in predicting the 5% and 95% quantiles. Points outside the 5% and 95% quantile are coloured in red, with the black dashed lines depicting the actual 5% and 95% quantiles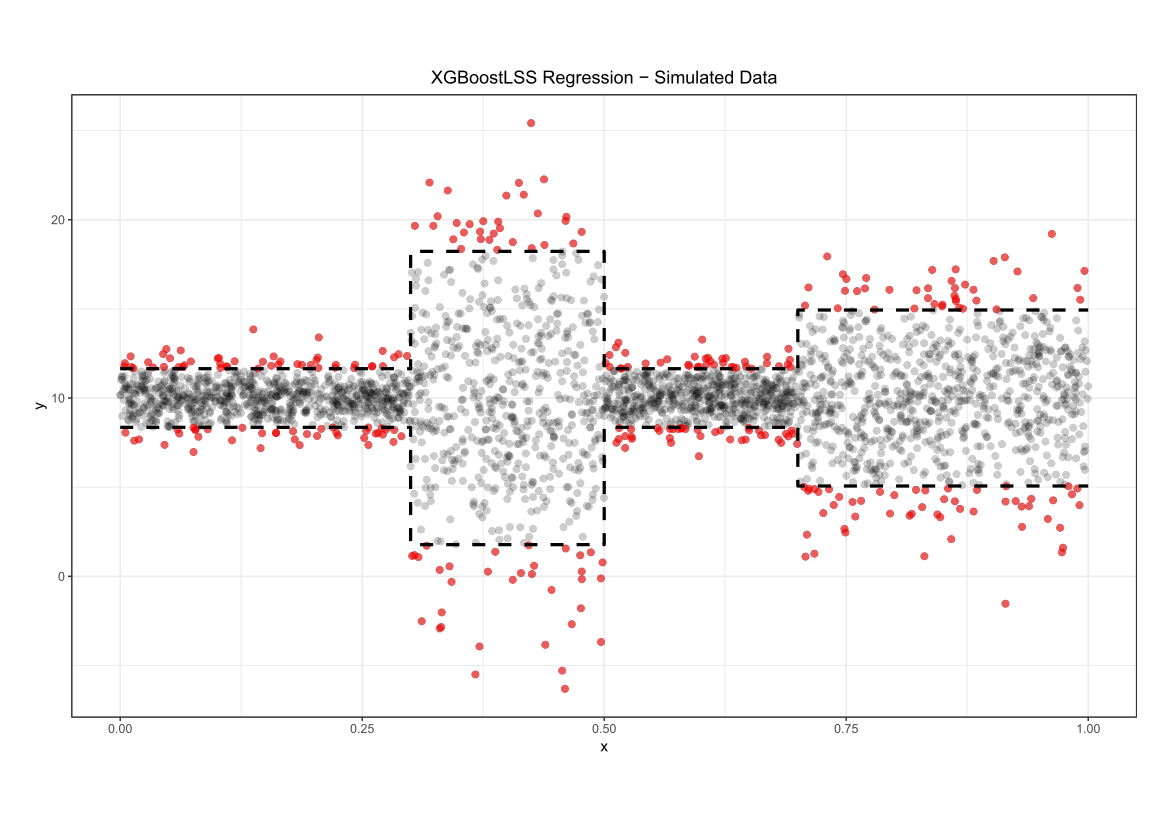
Let’s fit the XGBoostLSS model to the data. In general, the syntax is similar to the original XGBoost implementation. However, the user has to make a distributional assumption by specifying a family in the function call. As the data has been generated by a Normal distribution, we use the Normal as a function input. The user also has the option of providing a list of hyper-parameters that are used for training the surrogate regression model to find an optimized set of parameters. As our model allows to model the entire conditional distribution, we obtain prediction intervals and quantiles of interest directly from the predicted quantile function. Once the model is trained, we can predict all parameter of the distribution. The following Figure shows the predictions of XGBoostLSS for the 5% and 95% quantile in blue.
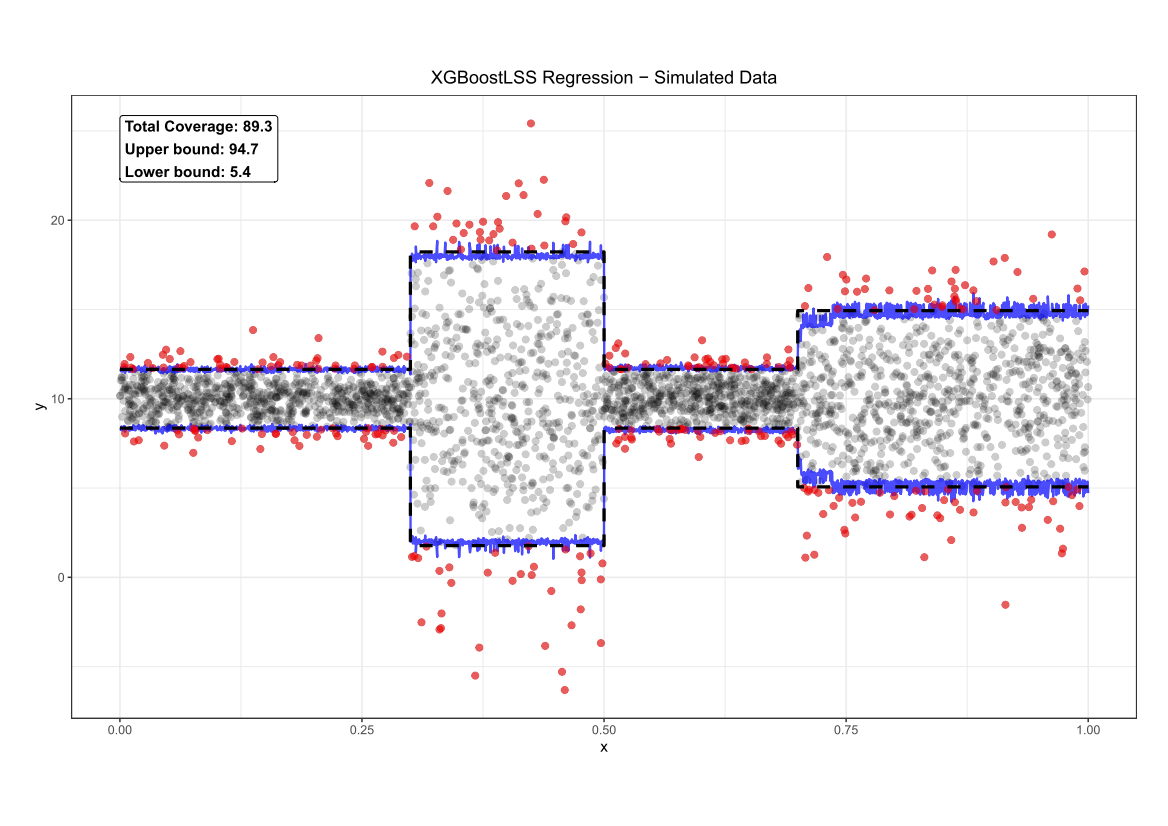 Comparing the coverage of the intervals with the nominal level of 90% shows that XGBoostLSS does not only correctly model the heteroskedasticity in the data, but it also provides an accurate forecast for the 5% and 95% quantiles. The flexibility of XGBoostLSS also comes from its ability to provide attribute importance, as well as partial dependence plots, for all of the distributional parameters. In the following we only investigate the effect on the conditional variance.
Comparing the coverage of the intervals with the nominal level of 90% shows that XGBoostLSS does not only correctly model the heteroskedasticity in the data, but it also provides an accurate forecast for the 5% and 95% quantiles. The flexibility of XGBoostLSS also comes from its ability to provide attribute importance, as well as partial dependence plots, for all of the distributional parameters. In the following we only investigate the effect on the conditional variance. 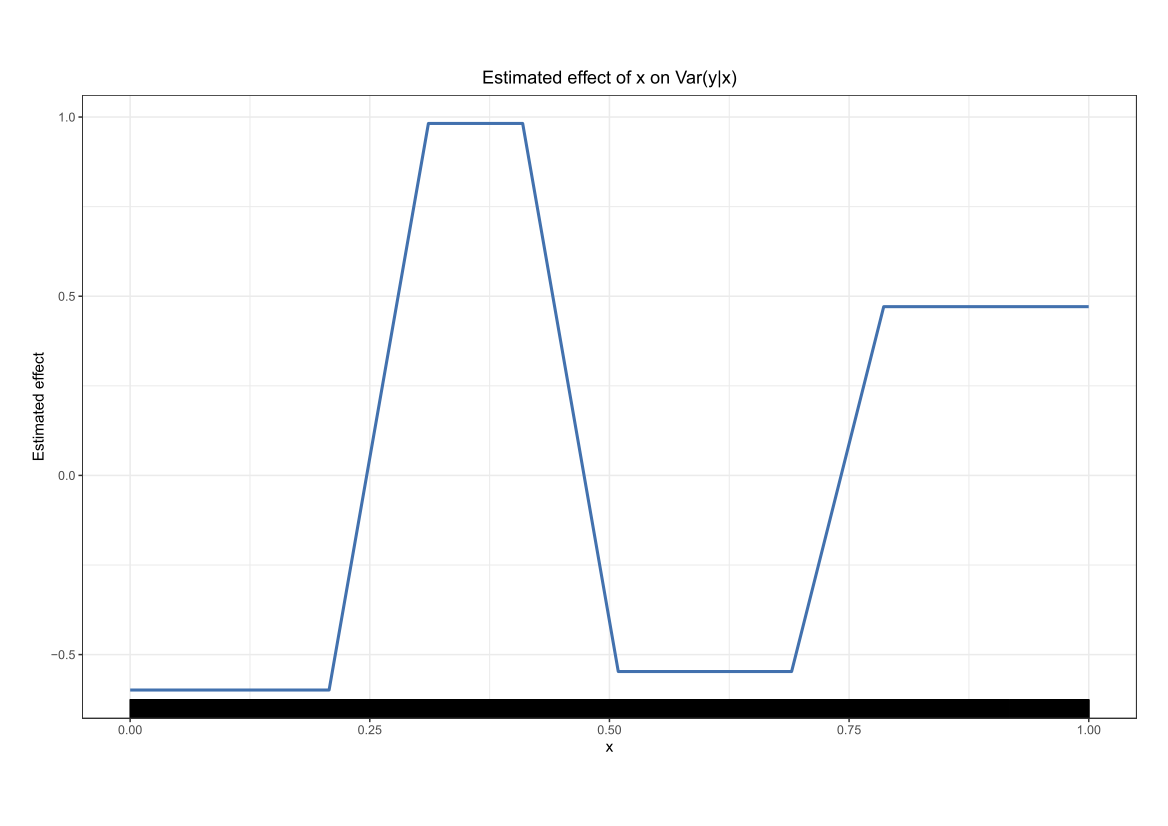
Munich Rent
Considering there is an active discussion around imposing a freeze in German cities on rents, we have chosen to re-visit the famous Munich Rent data set commonly used in the GAMLSS literature, as Munich is among the most expensive cities in Germany when it comes to living costs. As our dependent variable, we select Net rent per square meter in EUR.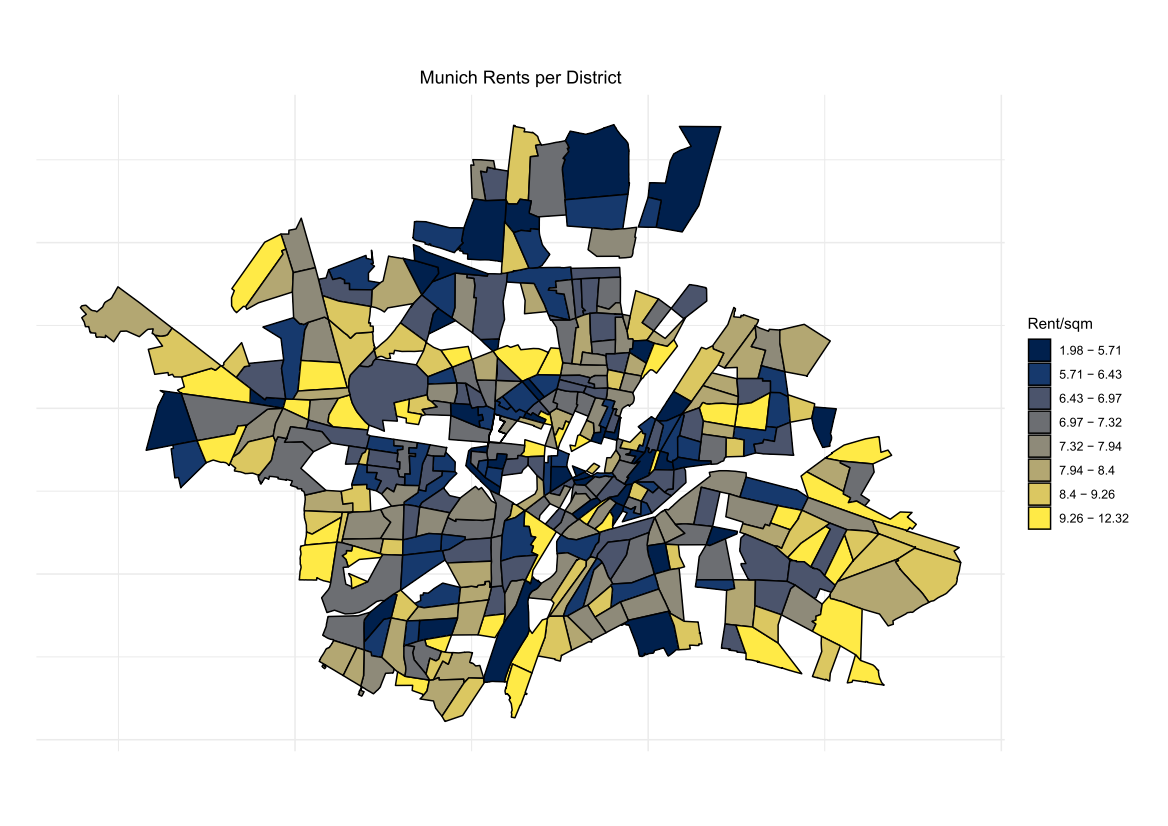
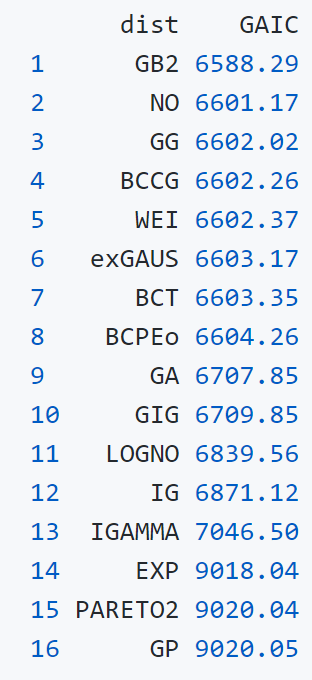
Even though the Generalized Beta Type 2 to provide the best approximation to the data, we use the more parsimonious Normal distribution, as it has only two distributional parameters, compared to 4 of the Generalized Beta Type 2.
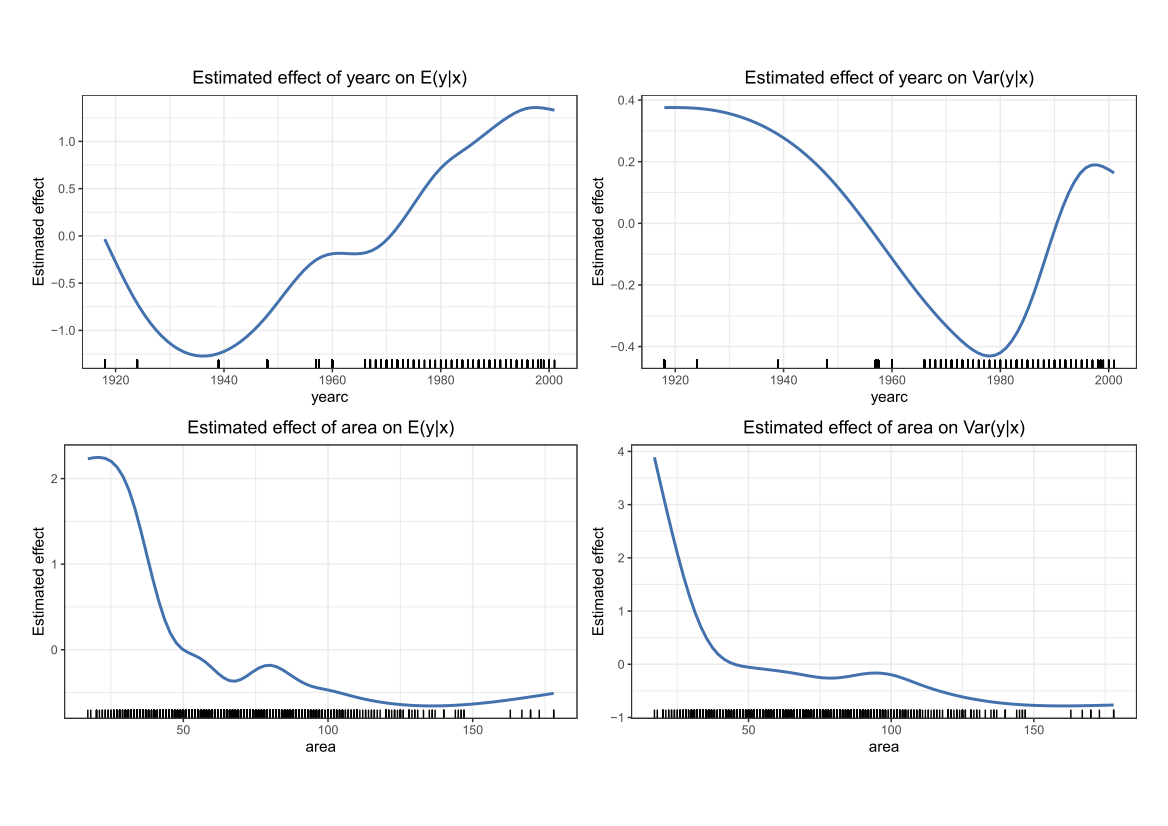
Now that we have specified the distribution, we fit XGBoostLSS to the data. Again, we use Bayesian Optimization for finding an optimal set of hyper-parameters. Looking at the estimated effects presented in the following Figure indicates that newer flats are on average more expensive, with the variance first decreasing and increasing again for flats built around 1980 and later. Also, as expected, rents per square meter decrease with an increasing size of the apartment.
The diagnostics for XGBoostLSS are based on quantile residuals of the fitted model and are shown in the following Figure.
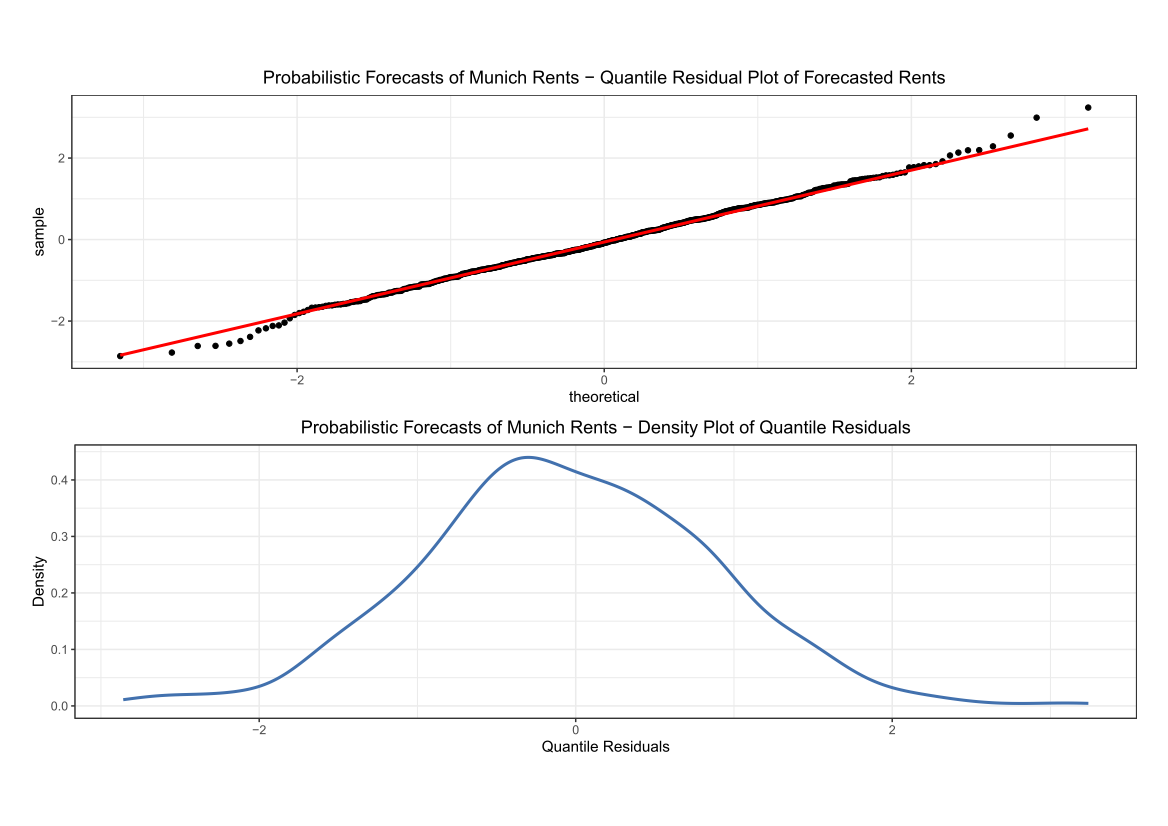
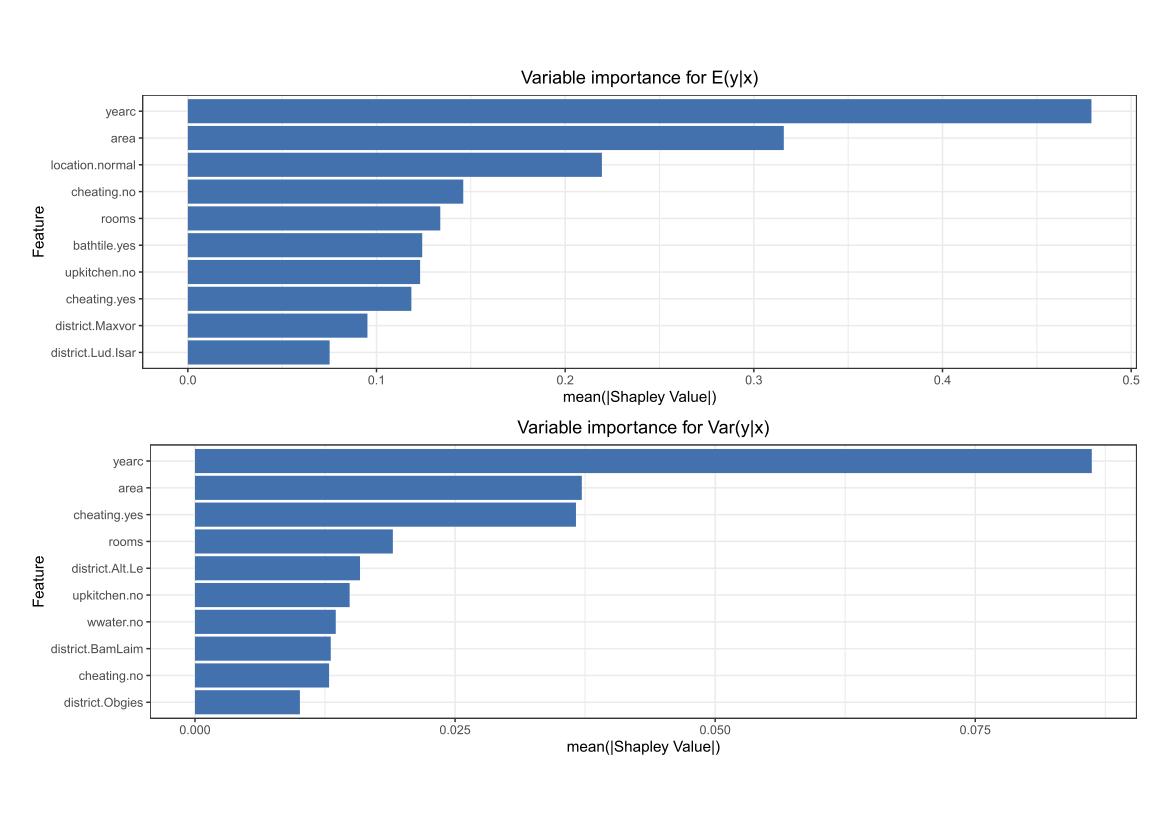
Despite some slight under-fitting in the tails of the distribution, XGBoostLSS provides a well calibrated forecast and confirms that our model is a good approximation to the data. XGBoostLSS also allows to investigate feature importance for all distributional parameters. Looking at the top 10 features with the highest Shapley values for both the conditional mean and variance indicates that both yearc and area are considered as being the most important variables.
Besides the global attribute importance, the user might also be interested in local attribute importance for each single prediction individually. This allows to answer questions like ‘How did the feature values of a single data point affect its prediction?‘ For illustration purposes, we select the first predicted rent of the test data set and present the local attribute importance for the conditional mean.
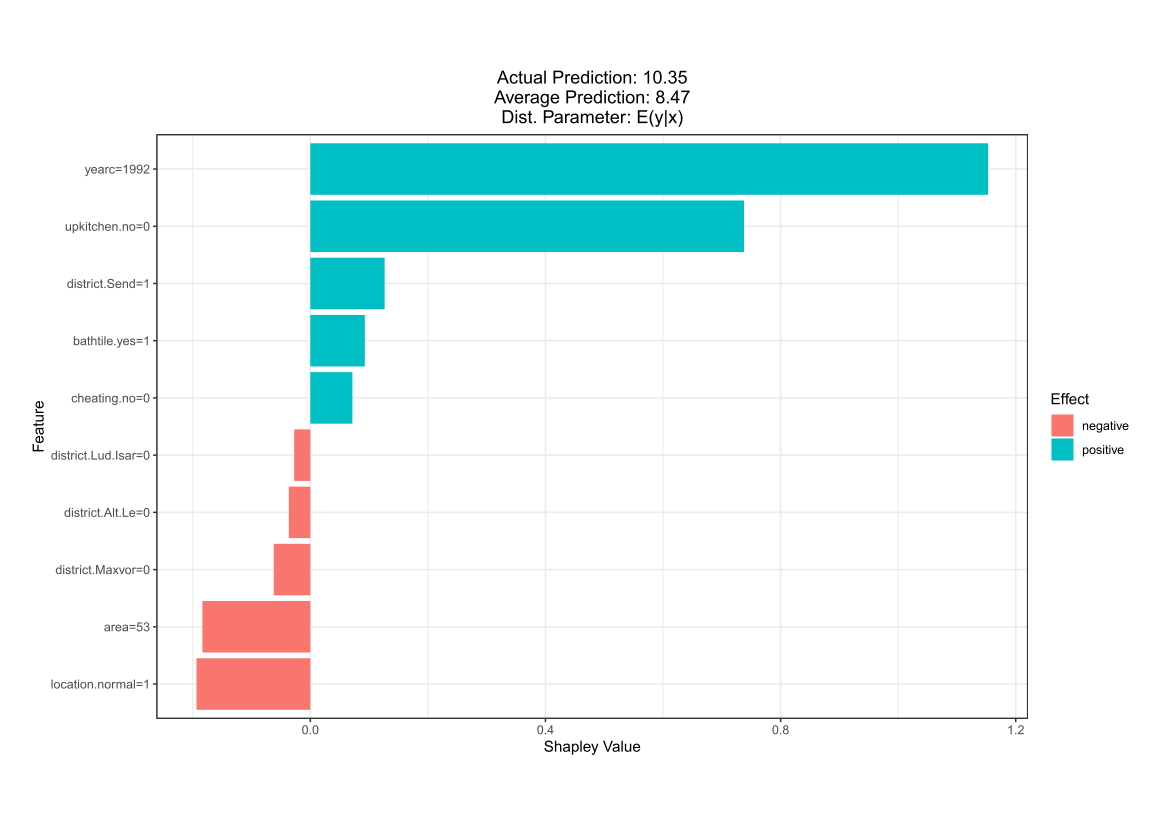
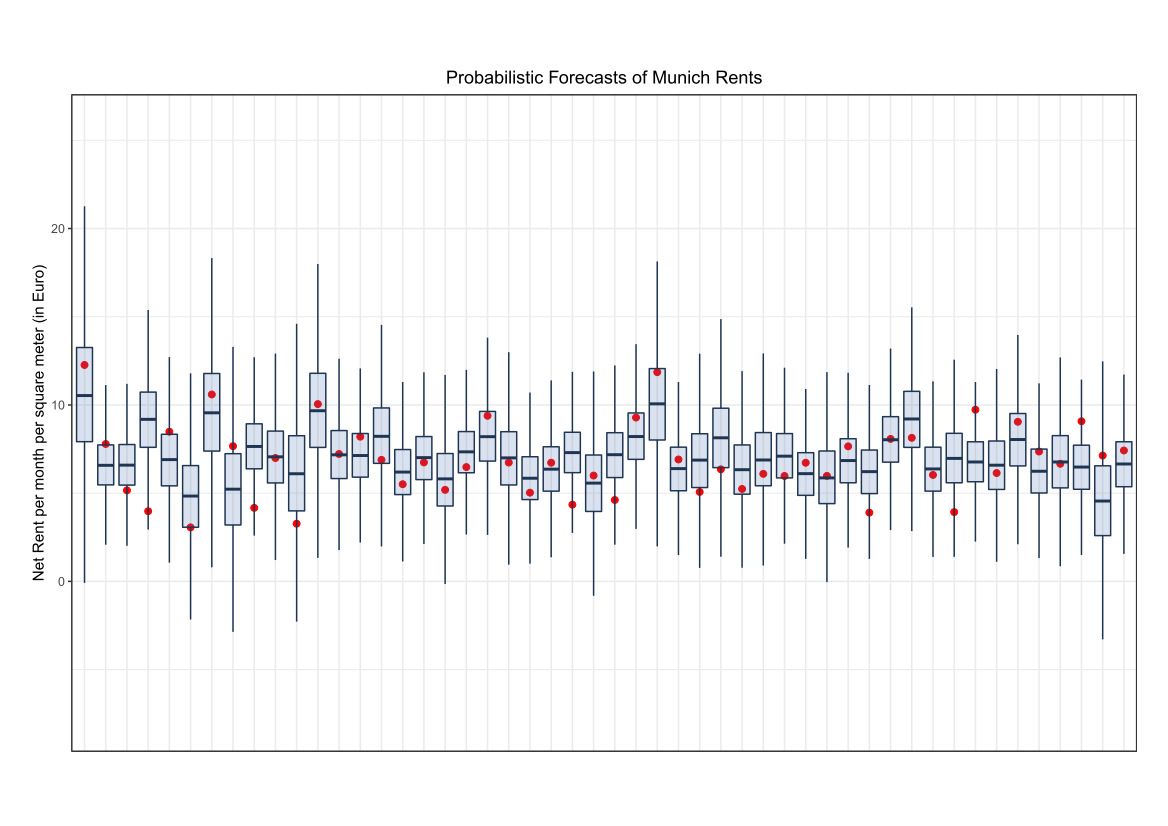
As we have modelled all parameters of the Normal distribution, XGBoostLSS provides a probabilistic forecast, from which any quantity of interest can be derived. Th following Figure shows a random subset of 50 predictions only for ease of readability. The red dots show the actual out of sample rents, while the boxplots visualize the predicted distributions.
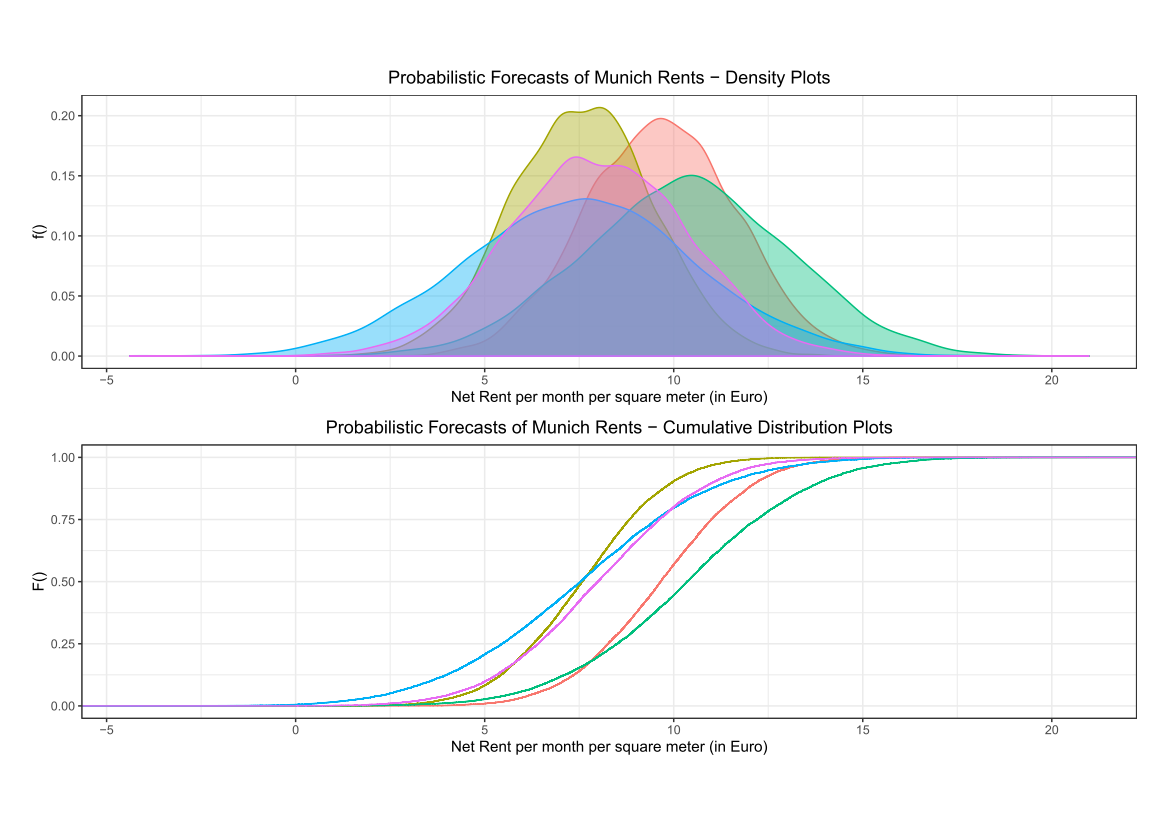
We can also plot a subset of the forecasted densities and cumulative distributions.
Comparison to other approaches
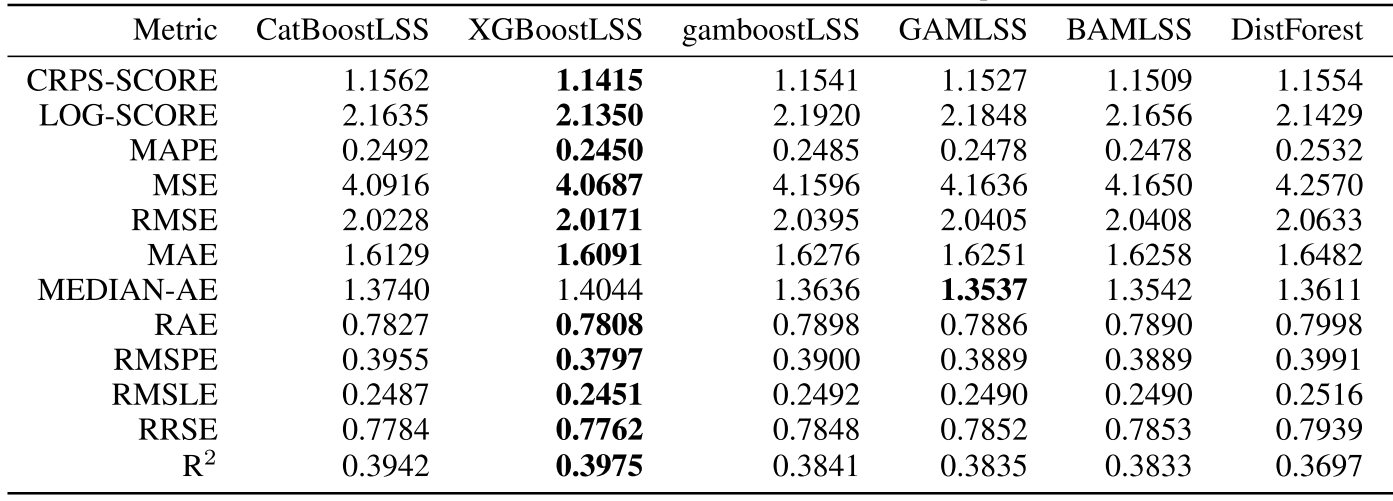
All measures, except the Median Absolute Error, show that XGBoostLSS provides more accurate forecasts than existing implementations.
Software Implementation
In its current implementation, XGBoostLSS is available in R and made publicly available soon on the Git-repo StatMixedML/XGBoostLSS. Extensions to Julia and Python are also planned. I am currently also working on an extension of CatBoost to allow for probabilistic forecasting. You may find it on the Git-repo StatMixedML/CatBoostLSS. Please note that due to time some restrictions, the public release of the package(s) may be somewhat delayed.
Reference Paper
März, Alexander (2019) “XGBoostLSS – An extension of XGBoost to probabilistic forecasting”.
März, Alexander (2020) “CatBoostLSS – An extension of CatBoost to probabilistic forecasting”.
One thought on “XGBoostLSS – An extension of XGBoost to probabilistic forecasting”