A Simple Method for Purging Mediation Effects among Independent Variables
Mediation can occur when one independent variable swamps the effect of another, suggesting high correlation between the two variables. Though there are some great packages for mediation analysis out there, the simple intuition of its need is often ambiguous, especially for younger graduate students. Thus, in this blog post, it is my goal to introduce an intuitive overview of mediation and offer a simple method for “purging” variables of mediation effects for their simultaneous use in multivariate analysis. The purging process detailed in this blog is available in my recently released R package, purging, which is available on CRAN or at my GitHub.
Let’s consider a couple practical examples from “real life” research contexts. First, suppose we are interested in whether committee membership relating to a specific issue domain influences the likelihood of sponsoring related issue-specific legislation. However, in the American context as representational responsibilities permeate legislative behavior, district characteristics in similar employment-related industries likely influence self-selection onto the issue-specific committees in the first place, which we also suggest should influence likelihood of related-issue bill sponsorship. Therefore, in this context, we have a mediation model, where employment/industry (indirect) -> committee membership (direct) -> sponsorship. Thus, we would want to purge committee membership of the effects of employment/industry in the district to observe the “pure” effect of committee membership on the likelihood of related sponsorship. This example is from my paper recently published in American Politics Research.
Or consider a second example in a different realm. Let’s say we had a model where women’s level of labor force participation determines their level of contraceptive use, and that the effect of female labor force participation on fertility is indirect, essentially filtered through its impact on contraceptive use. Once we control for contraceptive use, the direct effect of labor force participation may go away. In other words, the effect of labor force participation on fertility is likely indirect, and filtered through contraceptive use, which means the variables are also highly correlated. This second example was borrowed from Scott Basinger’s and Patrick Shea’s (University of Houston) graduate statistics labs, which originally gave me the idea of expanding this out to develop an R package dedicated to addressing this issue in a variety of contexts and for several functional forms.
These two examples offer simple ways of thinking about mediation effects (e.g., labor force (indirect) -> contraception (direct) -> fertility). If we run into this problem, a simple solution is “purging”. The steps to purge are to, first, regress the direct variable (in the second case, “contraceptive use”) on the indirect variable (in the second case, “labor force participation”). Then, store those residuals, which is the direct effect of contraception after accounting for the indirect effect of labor force participation. Then, we add the stored residuals as their own “purged variable” in the updated specification. Essentially, this purging process allows for a new direct variable that is uncorrelated with the indirect variable. When we do this, we will see that each variable is explaining unique variance in the DV of interest (you can double check this several ways, such as comparing correlation coefficients (which we will do below) or by comparing R^2 across specifications).
An Applied Example
With the intuition behind mediation and the purging solution in mind, let’s walk through a simple example using some fake data. For an example based on the second case described above using real data from the United Nations Human Development Programme, see the code file, purging example.R, at my GitHub repository.
# First, install the MASS package for the "mvrnorm" function
install.packages("MASS")
library(MASS)
# Second, install the purging package directly from CRAN for the "purge.lm" function
install.packages("purging")
library(purging)
# Set some paramters to guide our simulation
n = 5000
rho = 0.9
# Create some fake data
d = mvrnorm(n = n, mu = c(0, 0), Sigma = matrix(c(1, rho, rho, 1), nrow = 2), empirical = TRUE)
# Store each correlated variable as its own object
X = d[, 1]
Y = d[, 2]
# Create a dataframe of your two variables
d = data.frame(X, Y)
# Verify the correlation between these two normally distributed variables is what we set (rho = 0.9)
cor(d$X, d$Y)
plot(d$X, d$Y)
In addition to the correlation coefficient between the two variables being exactly as we specified (0.90), see this positive correlation between the two random variables in the plot below.
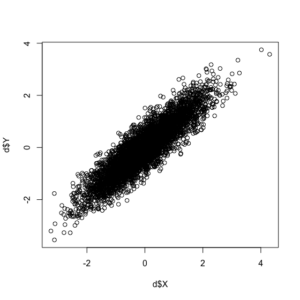
Now, with our correlated data created, we can call the “purge.lm” command, given that our data are continuous. Note: the package supports a variety of functional forms for continuous (linear), binary (logit and probit), and event count data (Poisson and negative binomial).
The idea behind the package is to generate the new direct-impact variable to be used in the analysis, purged of the effects of the indirect variable. To do so, simply input the name of the data frame first, followed by the name of the direct variable in quotes, and then the indirect variable also in quotes in the function. Calling the function will generate a new object (i.e., the direct variable), which can then be added to a data frame using the $ operator, with the following line of code:
df$purged.var <- purged.varLet’s now see the purge command in action using our fake data.
# Purge the "direct" variable, Y, of the mediation effects of X # (direct/indirect selection will depend on your model specification) purge.lm(d, "Y", "X") # df, "direct", "indirect" # You will get an automatic suggestion message to store the values in the df purged = purge.lm(d, "Y", "X") # Store as its own object d$purged = purged # Attach to df # Finally, check the correlation and the plot to see the effects purged from the original "Y" (direct) variable cor(d$X, d$purged) plot(d$X, d$purged)
Note the correlation between the original indirect (X) variable and the new direct (Y) variable, purged of the effects of X, is -9.211365e-17, or essentially non-existent. For additional corroboration, let’s see the updated correlation plot between the X and purged-Y variables.
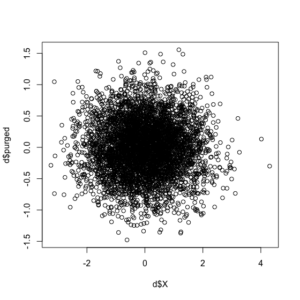
The purge command did as expected, with the correlation between the two variables essentially gone. You can download the package and documentation at CRAN. If you have any questions or find any bugs requiring fixing, please feel free to contact me. As this procedure was first developed and implemented (using the binary/logit iteration discussed above in the first example) in a now-published paper, please cite use of the package as: Waggoner, Philip D. 2018. “Do Constituents Influence Issue-Specific Bill Sponsorship?” American Politics Research, <https://doi.org/10.1177/1532673X18759644>
As a final note, once the intuition is mastered, be sure to check out the great work on mediation from many folks, including Kosuke Imai (Princeton), Luke Keele (Georgetown), and several others. See Imai’s mediation site as a sound starting place with code, papers, and more.
Thanks and enjoy!
One thought on “Introducing purging: An R package for addressing mediation effects”