
Installation
CRANinstall.packages('slickR')devtools::install_github('metrumresearchgroup/slickR')Examples
There are many options within the slick carousel, to get started with the basics we will show a few examples in the rest of the post. If you want to try out any of the examples you can go to this site where they are rendered and can be tested out.
library(svglite)
library(lattice)
library(ggplot2)
library(rvest)
library(reshape2)
library(dplyr)
library(htmlwidgets)
library(slickR)
Images
Some web scraping for the images example….#NBA Team Logos
nbaTeams=c("ATL","BOS","BKN","CHA","CHI","CLE","DAL","DEN","DET","GSW",
"HOU","IND","LAC","LAL","MEM","MIA","MIL","MIN","NOP","NYK",
"OKC","ORL","PHI","PHX","POR","SAC","SAS","TOR","UTA","WAS")
teamImg=sprintf("https://i.cdn.turner.com/nba/nba/.element/img/4.0/global/logos/512x512/bg.white/svg/%s.svg",nbaTeams)
#Player Images
a1=read_html('http://www.espn.com/nba/depth')%>%html_nodes(css = '#my-teams-table a')
a2=a1%>%html_attr('href')
a3=a1%>%html_text()
team_table=read_html('http://www.espn.com/nba/depth')%>%html_table()
team_table=team_table[[1]][-c(1,2),]
playerTable=team_table%>%melt(,id='X1')%>%arrange(X1,variable)
playerName=a2[grepl('[0-9]',a2)]
playerId=do.call('rbind',lapply(strsplit(playerName,'[/]'),function(x) x[c(8,9)]))
playerId=playerId[playerId[,1]!='phi',]
playerTable$img=sprintf('http://a.espncdn.com/combiner/i?img=/i/headshots/nba/players/full/%s.png&w=350&h=254',playerId[,1])Simple carousel
Let’s start easy: show the team logos one at a time with dots underneathslickR(obj = teamImg,slideId = 'ex1',height = 100,width='100%')
Grouped Images
There are players on each team, so lets group the starting five together and have each dot correspond with a team:slickR(
obj = playerTable$img,
slideId = c('ex2'),
slickOpts = list(
initialSlide = 0,
slidesToShow = 5,
slidesToScroll = 5,
focusOnSelect = T,
dots = T
),
height = 100,width='100%'
)
Replacing the dots
Sometimes the dots won’t be informative enough so we can switch them with an HTML object, such as text or other images. We can pass to the customPaging argument javascript code using thehtmlwidgets::JS function.
Replace dots with text
cP1=JS("function(slick,index) {return '<a>'+(index+1)+'</a>';}")
slickR(
obj = playerTable$img,
slideId = 'ex3',
dotObj = teamImg,
slickOpts = list(
initialSlide = 0,
slidesToShow = 5,
slidesToScroll = 5,
focusOnSelect = T,
dots = T,
customPaging = cP1
),
height=100,width='100%'
)
Replace dots with Images
cP2=JS("function(slick,index) {return '<a><img src= ' + dotObj[index] + ' width=100% height=100%></a>';}")
#Replace dots with Images
s1 <- slickR(
obj = playerTable$img,
dotObj = teamImg,
slickOpts = list(
initialSlide = 0,
slidesToShow = 5,
slidesToScroll = 5,
focusOnSelect = T,
dots = T,
customPaging = cP2
),height = 100,width='100%'
)
#Putting it all together in one slickR call
s2 <- htmltools::tags$script(
sprintf("var dotObj = %s",
jsonlite::toJSON(teamImg))
)
htmltools::browsable(htmltools::tagList(s2, s1))
Plots
To place plots directly into slickR we use svglite to convert a plot into svg code using xmlSVG and then convert it into a character objectplotsToSVG=list(
#Standard Plot
xmlSVG({plot(1:10)},standalone=TRUE),
#lattice xyplot
xmlSVG({print(xyplot(x~x,data.frame(x=1:10),type="l"))},standalone=TRUE),
#ggplot
xmlSVG({show(ggplot(iris,aes(x=Sepal.Length,y=Sepal.Width,colour=Species))+
geom_point())},standalone=TRUE),
#lattice dotplot
xmlSVG({print(dotplot(variety ~ yield | site , data = barley, groups = year,
key = simpleKey(levels(barley$year), space = "right"),
xlab = "Barley Yield (bushels/acre) ",
aspect=0.5, layout = c(1,6), ylab=NULL))
},standalone=TRUE)
)
#make the plot self contained SVG to pass into slickR
s.in=sapply(plotsToSVG,function(sv){paste0("data:image/svg+xml;utf8,",as.character(sv))})slickR(s.in,slideId = 'ex4',slickOpts = list(dots=T), height = 200,width = '100%')
Synching Carousels
There are instances when you have many outputs at once and do not want to go through all, so you can combine two carousels one for viewing and one for searching.slickR(rep(s.in,each=5),slideId = c('ex5up','ex5down'),
slideIdx = list(1:20,1:20),
synchSlides = c('ex5up','ex5down'),
slideType = rep('img',4),
slickOpts = list(list(slidesToShow=1,slidesToScroll=1),
list(dots=F,slidesToScroll=1,slidesToShow=5,
centerMode=T,focusOnSelect=T)
),
height=100,width = '100%'
)
Iframes
Since the carousel can accept any html element we can place iframes in the carousel. There are times when you may want to put in different DOMs rather than an image in slick. Using slideType you can specify which DOM is used in the slides. For example let’s put the help Rd files from ggplot2 into a slider using the helper function getHelp. (Dont forget to open the output to a browser to view the iframe contents).geom_filenames=ls("package:ggplot2",pattern = '^geom')
slickR(unlist(lapply(geom_filenames,getHelp,pkg = 'ggplot2')),slideId = 'ex6',slideType = 'iframe',height = '400px',width='100%',slickOpts = list(dots=T,slidesToShow=2,slidesToScroll=2))
htmlwidgets
Finally, we can really leverage R and place self contained htmlwidgets in iframes (like leaflets and plotly) and use them in a carousel. This solves a problem of how to run many htmlwidgets at once outside of Shiny.library(leaflet)
library(plotly)
l <- leaflet() %>% addTiles()
htmlwidgets::saveWidget(l,'leaflet.html')
p <- iris%>%ggplot(aes(x=Sepal.Length,y=Sepal.Width))+geom_point()
pL= ggplotly(p)
htmlwidgets::saveWidget(pL,'ggplotly.html')
slickR(c(rep(paste0(readLines('leaflet.html'),collapse='\n'),4),
rep(paste0(readLines('ggplotly.html'),collapse='\n'),4)),
slideId = c('leaf','plot'),
slideIdx = list(1:4,5:8),
slideType = rep('iframe',2),
slickOpts = list(list(dots=T,slidesToShow=2,slidesToScroll=2),
list(dots=T,slidesToShow=2,slidesToScroll=2)),
height='200px',width='100%')Jonathan Sidi joined Metrum Research Group in 2016 after working for several years on problems in applied statistics, financial stress testing and economic forecasting in both industrial and academic settings. To learn more about additional open-source software packages developed by Metrum Research Group please visit the Metrum website. Contact: For questions and comments, feel free to email me at: [email protected] or open an issue for bug fixes or enhancements at github.
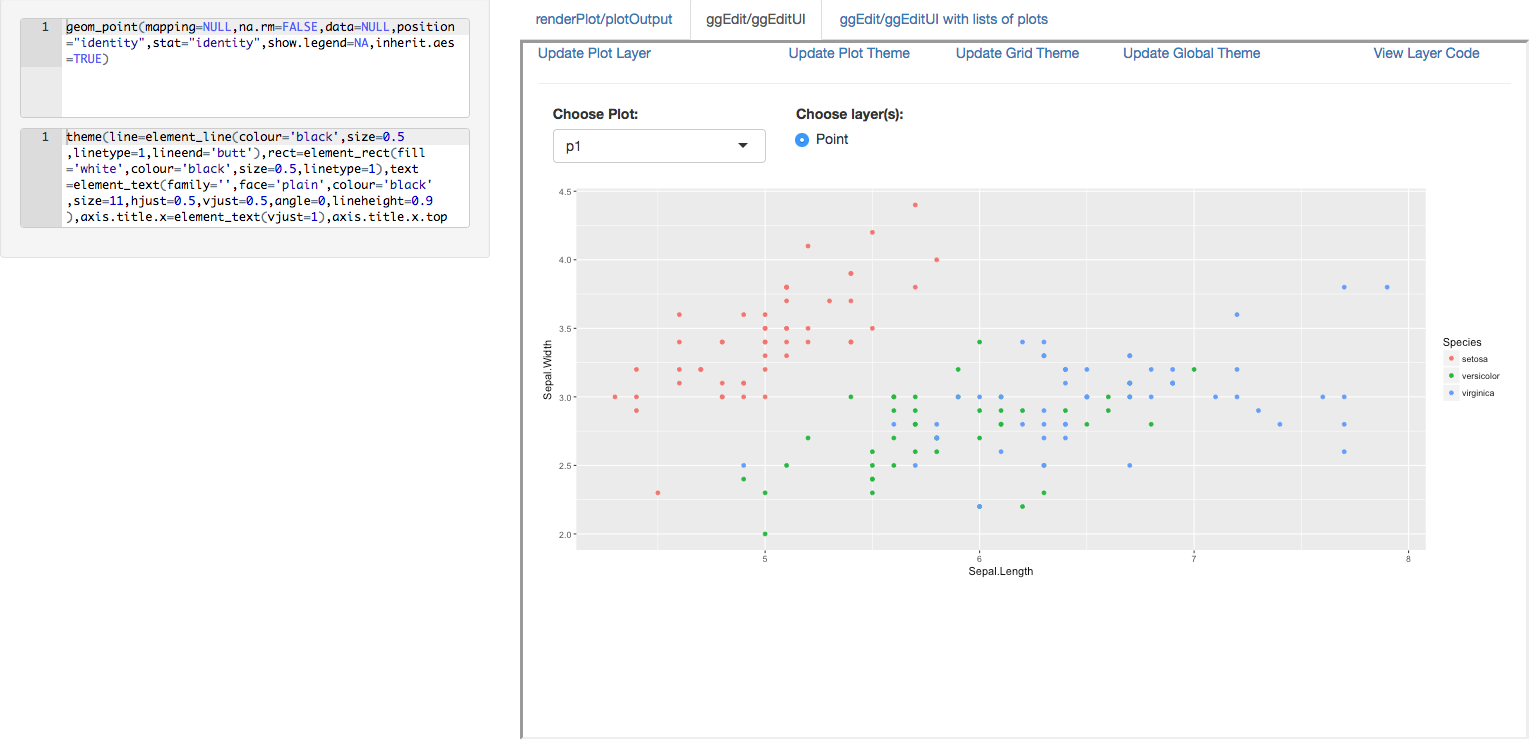 We are pleased to announce the release of the ggedit package on
We are pleased to announce the release of the ggedit package on 
 The collection of example flight data in json format available in
The collection of example flight data in json format available in 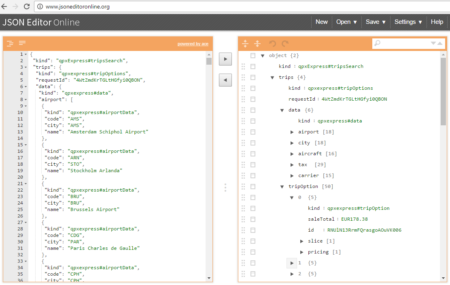 However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions:
However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions: