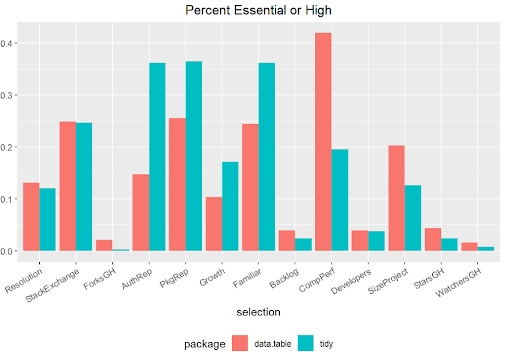
Let’s take a look at what the respondents designated as Essential or High Priority reasons for selecting either data.table or tidy packages. Both user types appear to utilize Stack Exchange as a technical reference, and both keep an eye on how issues are resolved with a package. Tidy users value the reputation of the author and the package, and they appreciate the familiarity they experience when using tidy because of other packages they use. The data.table users are very concerned with computing performance. (Note – The shortened labels below correspond to the order of the tiles above.)
 We wondered if data.table users were in roles that required the ability to manipulate very large data sets in memory, taking advantage of data.table’s ability to quickly update columns by reference. Did the role of the respondent predispose their package selection?
We wondered if data.table users were in roles that required the ability to manipulate very large data sets in memory, taking advantage of data.table’s ability to quickly update columns by reference. Did the role of the respondent predispose their package selection?
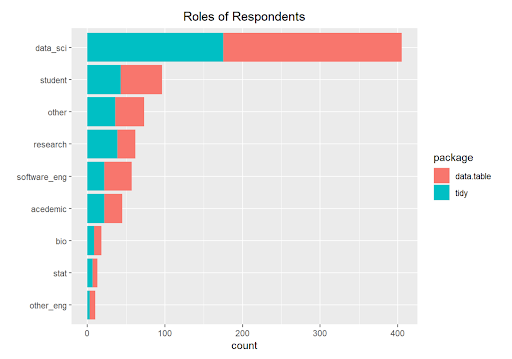 Nope. Look’s like the preference for data.table or tidy is not related to the role of the user. I do prefer Coca-cola over Pepsi, but maybe I prefer Coke because I was born in the capital of Coke. I am guessing that “exposure” may also be a determining factor when selecting R libraries. In the next installment, we move beyond visualizations, and we will build a logistic model to predict the probability that a user will select data.table or tidy. Dust off your log odds!
Nope. Look’s like the preference for data.table or tidy is not related to the role of the user. I do prefer Coca-cola over Pepsi, but maybe I prefer Coke because I was born in the capital of Coke. I am guessing that “exposure” may also be a determining factor when selecting R libraries. In the next installment, we move beyond visualizations, and we will build a logistic model to predict the probability that a user will select data.table or tidy. Dust off your log odds!
Link to bitbucket is dead
Many thanks, fixed
data.table is a, more or less, independent implementation of enhancements to read datasets in R. On the other hand, tidy is a series of R packages that work well with each other, but use common syntax / design that is compatible within the tidyverse and confounds other users.
Absolutely correct, the comparison was made not with the tidyverse but with tidyr and two other packages that most closely resemble the functionality provided by data.table.
Fun stuff, thanks!