labourR is a new package that performs occupations coding for multilingual free-form text (e.g. a job title) using the ESCO hierarchical classification model.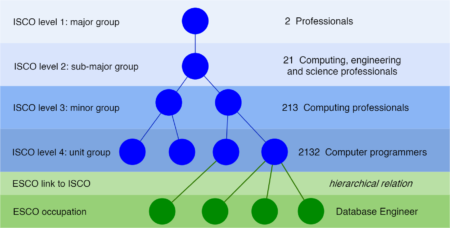
The initial motivation was to retrieve the work experience history from a Curriculum Vitae generated from the Europass online CV editor. Document vectorization is performed using the ESCO model and a fuzzy match is allowed with various string distance metrics.
The
labourR package:- Allows classifying multilingual free-text using the ESCO-ISCO hierarchy of occupations.
- Computations are fully vectorized and memory efficient.
- Includes facilities to assist research in information mining of labour market data.
Installation
You can install the released version of labourR from CRAN with,install.packages("labourR")
library(labourR) corpus <- data.frame( id = 1:3, text = c("Data Scientist", "Junior Architect Engineer", "Cashier at McDonald's") )
num_leaves specifies the number of ESCO occupations used to perform a plurality vote,classify_occupation(corpus = corpus, isco_level = 3, lang = "en", num_leaves = 5) #> id iscoGroup preferredLabel #> 1: 1 251 Software and applications developers and analysts #> 2: 2 214 Engineering professionals (excluding electrotechnology) #> 3: 3 523 Cashiers and ticket clerksFor further information browse the vignettes.