author: “Genrikh Ananiev”
Problem description
Under business conditions, narrowly specialized tasks often come across, which require a special approach because they do not fit into the standard data processing flow and constructing models. One of these tasks is the classification of new products in master data management process (MDM).
- Stop words.
- Tochenization
- Stemming
- Reducing document-terms matrices
- Training the model
devtools::install_github(repo = 'https://github.com/edvardoss/abbrevTexts') library(abbrevTexts) library(tidytext) # text proccessing library(dplyr) # data processing library(stringr) # data processing library(SnowballC) # traditional stemming approach library(tm) #need only for tidytext internal purpose
The package includes 2 data sets on the names of wines: the original names of wines from external data sources – “rawProducts” and the unified names of wines written in the standards for maintaining the company’s master data – “standardProducts”. The rawProducts table has many spelling variations of the same product, these variations are reduced to one product in standardProducts through a many-to-one relationship on the “standartId” key column. PS Variations in the “rawProducts” table are generated programmatically, but with the maximum possible similarity to how product names come from external various sources in my experience (although somewhere I may have overdone it)
data(rawProducts, package = 'abbrevTexts') head(rawProducts)
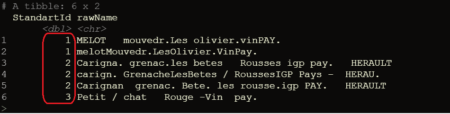
data(standardProducts, package = 'abbrevTexts') head(standardProducts)

Train and test split
set.seed(1234) trainSample <- sample(x = seq(nrow(rawProducts)),size = .9*nrow(rawProducts)) testSample <- setdiff(seq(nrow(rawProducts)),trainSample) testSampleCreate dataframes for ‘no stemming mode’ and ‘traditional stemming mode’
df <- rawProducts %>% mutate(prodId=row_number(),
rawName=str_replace_all(rawName,pattern = '\\.','. ')) %>%
unnest_tokens(output = word,input = rawName) %>% count(StandartId,prodId,word)
df.noStem <- df %>% bind_tf_idf(term = word,document = prodId,n = n)
df.SnowballStem <- df %>% mutate(wordStm=SnowballC::wordStem(word)) %>%
bind_tf_idf(term = wordStm,document = prodId,n = n)
Create document terms matrixdtm.noStem <- df.noStem %>% cast_dtm(document = prodId,term = word,value = tf_idf) %>% data.matrix() dtm.SnowballStem <- df.SnowballStem %>% cast_dtm(document = prodId,term = wordStm,value = tf_idf) %>% data.matrix()Create knn model for ‘no stemming mode’ and calculate accuracy
knn.noStem <- class::knn1(train = dtm.noStem[trainSample,],
test = dtm.noStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.noStem==rawProducts$StandartId[testSample])
Accuracy is: 0.4761905 (47%)Create knn model for ‘stemming mode’ and calculate accuracy
knn.SnowballStem <- class::knn1(train = dtm.SnowballStem[trainSample,],
test = dtm.SnowballStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.SnowballStem==rawProducts$StandartId[testSample])
Accuracy is: 0.5 (50%)abbrevTexts primer
Below is an example on the same data but using the functions from abbrevTexts package
Separating words by case
df <- rawProducts %>% mutate(prodId=row_number(),
rawNameSplitted= makeSeparatedWords(rawName)) %>%
unnest_tokens(output = word,input = rawNameSplitted)
print(df)
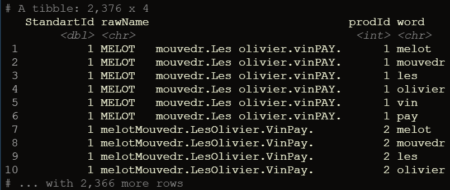
As you can see, the tokenization of the text was carried out correctly: not only transitions from upper and lower case when writing together are taken into account, but also punctuation marks between words written together without spaces are taken into account.
Creating a stemming dictionary based on a training sample of words
After a long search among different stemming implementations, I came to the conclusion that traditional methods based on the rules of the language are not suitable for such specific tasks, so I had to look for my own approach. As a result, I came to the most optimal solution, which was reduced to unsupervised learning, which is not sensitive to the text language or the degree of reduction of the available words in the training sample.
The function takes a vector of words as input, the minimum word length for the training sample and the minimum fraction for considering the child word as an abbreviation of the parent word and then does the following:
1. Discarding words with a length less than the set threshold
2. Discarding words consisting of numbers
3. Sort the words in descending order of their length
4. For each word in the list:
4.1 Filter out words that are less than the length of the current word and greater than or equal to the length of the current word multiplied by the minimum fraction
4.2 Select from the list of filtered words those that are the beginning of the current word
Let’s say that we fix min.share = 0.7
At this intermediate stage (4.2), we get a parent-child table where such examples can be found:

Note that each line meets the condition that the length of the child’s word is not shorter than 70% of the length of the parent’s word.
However, there may be found pairs that can not be considered as abbreviations of words because in them different parents are reduced to one child, for example:

My function for such cases leaves only one pair.
Let’s go back to the example with unambiguous abbreviations of words
But if you look a little more closely, we see that there is a common word ‘bodeg’ for these 2 pairs and this word allows you to connect these pairs into one chain of abbreviations without violating our initial conditions on the length of a word to consider it an abbreviation of another word:
bodegas->bodeg->bode
So we come to a table of the form:

Such chains can be of arbitrary length and it is possible to assemble from the found pairs into such chains recursively. Thus we come to the 5th stage of determining the final child for each participant of the constructed chain of abbreviations of words
5. Recursively iterating through the found pairs to determine the final (terminal) child for all members of chains
6. Return the abbreviation dictionary
The makeAbbrStemDict function is automatically paralleled by several threads loading all the processor cores, so it is advisable to take this point into account for large volumes of texts.
abrDict <- makeAbbrStemDict(term.vec = df$word,min.len = 3,min.share = .6) head(abrDict) # We can see parent word, intermediate results and total result (terminal child)
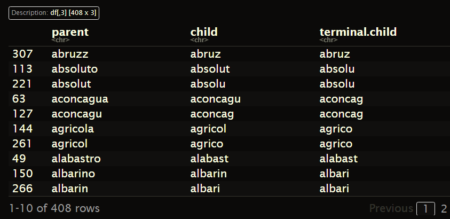
The output of the stemming dictionary in the form of a table is also convenient because it is possible to selectively and in a simple way in the “dplyr” paradigm to delete some of the stemming lines.
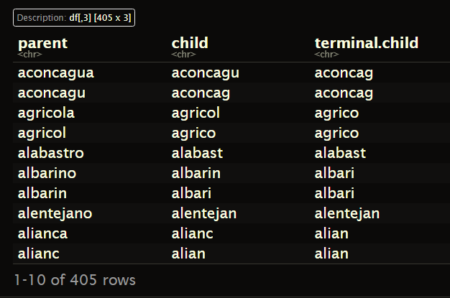
Lets say that we wont to exclude parent word “abruzz” and terminal child group “absolu” from stemming dictionary:
abrDict.reduced <- abrDict %>% filter(parent!='abruzz',terminal.child!='absolu') print(abrDict.reduced)
Compare the simplicity and clarity of this solution with what is offered in stackoverflow:
Text-mining with the tm-package – word stemming
Stem using abbreviate dictionary
df.AbbrStem <- df %>% left_join(abrDict %>% select(parent,terminal.child),by = c('word'='parent')) %>%
mutate(wordAbbrStem=coalesce(terminal.child,word)) %>% select(-terminal.child)
print(df.AbbrStem)
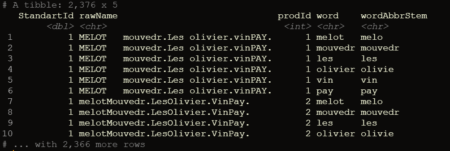
TF-IDF for stemmed words
df.AbbrStem <- df.AbbrStem %>% count(StandartId,prodId,wordAbbrStem) %>% bind_tf_idf(term = wordAbbrStem,document = prodId,n = n) print(df.AbbrStem)
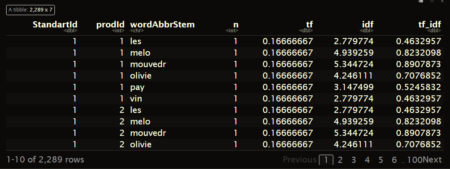
Create document terms matrix
dtm.AbbrStem <- df.AbbrStem %>% cast_dtm(document = prodId,term = wordAbbrStem,value = tf_idf) %>% data.matrix()Create knn model for ‘abbrevTexts mode’ and calculate accuracy
knn.AbbrStem <- class::knn1(train = dtm.AbbrStem[trainSample,],
test = dtm.AbbrStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.AbbrStem==rawProducts$StandartId[testSample])
Accuracy for “abbrevTexts”: 0.8333333 (83%)As you can see , we have received significant improvements in the quality of classification in the test sample.
Tidytext is a convenient package for a small courpus of texts, but in the case of a large courpus of texts, the “AbbrevTexts” package is also perfectly suitable for preprocessing and normalization and usually gives better accuracy in such specific tasks compared to the traditional approach
edvardoss/abbrevTexts: Functions that will make life less sad when working with abbreviated text for multiclassification tasks (github.com)