
Mathematics and Programming for Machine Learning with R -Chapter 2 Logic
Have a look at the FREE attached pdf of Chapter 2 on Logic and R from my recently published textbook,
Mathematics and Programming for Machine Learning with R: From the Ground Up, by William B. Claster (Author)
~430 pages, over 400 exercises.Mathematics and Programming for Machine Learning with R -Chapter 2 Logic
We discuss how to code machine learning algorithms in R but start from scratch. The first 4 chapters cover Logic, Sets, Probability, Functions. I am sharing Chapter 2 here on Logic and R here and will also probably release chapters 9 and 10 on Math for Neural Networks shortly. The text is on sale at Amazon here:
https://www.amazon.com/Mathematics-Programming-Machine-Learning-R-dp-0367507854/dp/0367507854/ref=mt_other?_encoding=UTF8&me=&qid=1623663440
I will try to add an errata page as well.
Tag: #R
Tutorial: Cleaning and filtering data from Qualtrics surveys, and creating new variables from existing data
Hi fellow R users (and Qualtrics users),
As many Qualtrics surveys produce really similar output datasets, I created a tutorial with the most common steps to clean and filter data from datasets directly downloaded from Qualtrics.
You will also find some useful codes to handle data such as creating new variables in the dataframe from existing variables with functions and logical operators.
The tutorial is presented in the format of a downloadable R code with explanations and annotations of each step. You will also find a raw Qualtrics dataset to work with.
Link to the tutorial: https://github.com/angelajw/QualtricsDataCleaning
This dataset comes from a Qualtrics survey with an experiment format (control and treatment conditions), but the codes can be applicable to non-experimental datasets as well, as many cleaning steps are the same.
As many Qualtrics surveys produce really similar output datasets, I created a tutorial with the most common steps to clean and filter data from datasets directly downloaded from Qualtrics.
You will also find some useful codes to handle data such as creating new variables in the dataframe from existing variables with functions and logical operators.
The tutorial is presented in the format of a downloadable R code with explanations and annotations of each step. You will also find a raw Qualtrics dataset to work with.
Link to the tutorial: https://github.com/angelajw/QualtricsDataCleaning
This dataset comes from a Qualtrics survey with an experiment format (control and treatment conditions), but the codes can be applicable to non-experimental datasets as well, as many cleaning steps are the same.
Isovists using uniform ray casting in R
Isovists are polygons of visible areas from a point. They remove views that are blocked by objects, typically buildings. They can be used to understanding the existing impact of, or where to place urban design features that can change people’s behaviour (e.g. advertising boards, security cameras or trees). Here I present a custom function that creates a visibility polygon (isovist) using a uniform ray casting “physical” algorithm in R.
First we load the required packages (use
First we load the required packages (use
install.packages() first if these are not already installed in R):library(sf)
library(dplyr)
library(ggplot2)
Data generation
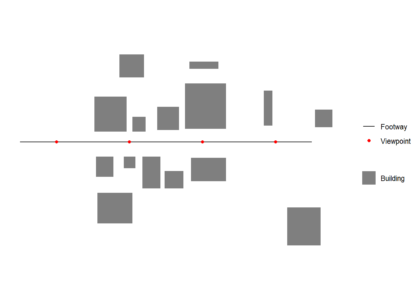
First we create and plot an example footway with viewpoints and set of buildings which block views. All data used should be in the same Coordinate Reference System (CRS). We generate one viewpoint every 50 m (note density here is a function of the st_crs() units, in this case meters)library(sf)
footway <- st_sfc(st_linestring(rbind(c(-50,0),c(150,0))))
st_crs(footway) = 3035
viewpoints <- st_line_sample(footway, density = 1/50)
viewpoints <- st_cast(viewpoints,"POINT")
buildings <- rbind(c(1,7,1),c(1,31,1),c(23,31,1),c(23,7,1),c(1,7,1),
c(2,-24,2),c(2,-10,2),c(14,-10,2),c(14,-24,2),c(2,-24,2),
c(21,-18,3),c(21,-10,3),c(29,-10,3),c(29,-18,3),c(21,-18,3),
c(27,7,4),c(27,17,4),c(36,17,4),c(36,7,4),c(27,7,4),
c(18,44,5), c(18,60,5),c(35,60,5),c(35,44,5),c(18,44,5),
c(49,-32,6),c(49,-20,6),c(62,-20,6),c(62,-32,6),c(49,-32,6),
c(34,-32,7),c(34,-10,7),c(46,-10,7),c(46,-32,7),c(34,-32,7),
c(63,9,8),c(63,40,8),c(91,40,8),c(91,9,8),c(63,9,8),
c(133,-71,9),c(133,-45,9),c(156,-45,9),c(156,-71,9),c(133,-71,9),
c(152,10,10),c(152,22,10),c(164,22,10),c(164,10,10),c(152,10,10),
c(44,8,11),c(44,24,11),c(59,24,11),c(59,8,11),c(44,8,11),
c(3,-56,12),c(3,-35,12),c(27,-35,12),c(27,-56,12),c(3,-56,12),
c(117,11,13),c(117,35,13),c(123,35,13),c(123,11,13),c(117,11,13),
c(66,50,14),c(66,55,14),c(86,55,14),c(86,50,14),c(66,50,14),
c(67,-27,15),c(67,-11,15),c(91,-11,15),c(91,-27,15),c(67,-27,15))
buildings <- lapply( split( buildings[,1:2], buildings[,3] ), matrix, ncol=2)
buildings <- lapply(X = 1:length(buildings), FUN = function(x) {
st_polygon(buildings[x])
})
buildings <- st_sfc(buildings)
st_crs(buildings) = 3035
# plot raw data
ggplot() +
geom_sf(data = buildings,colour = "transparent",aes(fill = 'Building')) +
geom_sf(data = footway, aes(color = 'Footway')) +
geom_sf(data = viewpoints, aes(color = 'Viewpoint')) +
scale_fill_manual(values = c("Building" = "grey50"),
guide = guide_legend(override.aes = list(linetype = c("blank"),
nshape = c(NA)))) +
scale_color_manual(values = c("Footway" = "black",
"Viewpoint" = "red",
"Visible area" = "red"),
labels = c("Footway", "Viewpoint","Visible area"))+
guides(color = guide_legend(
order = 1,
override.aes = list(
color = c("black","red"),
fill = c("transparent","transparent"),
linetype = c("solid","blank"),
shape = c(NA,16))))+
theme_minimal()+
coord_sf(datum = NA)+
theme(legend.title=element_blank())
Isovist function
Function inputs
Buildings should be cast to"POLYGON" if they are not already
buildings <- st_cast(buildings,"POLYGON")
Creating the function
A few parameters can be set before running the function.rayno is the number of observer view angles from the viewpoint. More rays are more precise, but decrease processing speed.raydist is the maximum view distance. The function takessfc_POLYGON type and sfc_POINT objects as inputs for buildings abd the viewpoint respectively.
If points have a variable view distance the function can be modified by creating a vector of view distance of length(viewpoints) here and then selecting raydist[x] in st_buffer below.
Each ray is intersected with building data within its raycast distance, creating one or more ray line segments. The ray line segment closest to the viewpoint is then extracted, and the furthest away vertex of this line segement is taken as a boundary vertex for the isovist. The boundary vertices are joined in a clockwise direction to create an isovist.st_isovist <- function(
buildings,
viewpoint,
# Defaults
rayno = 20,
raydist = 100) {
# Warning messages
if(!class(buildings)[1]=="sfc_POLYGON") stop('Buildings must be sfc_POLYGON')
if(!class(viewpoint)[1]=="sfc_POINT") stop('Viewpoint must be sf object')
rayends <- st_buffer(viewpoint,dist = raydist,nQuadSegs = (rayno-1)/4)
rayvertices <- st_cast(rayends,"POINT")
# Buildings in raydist
buildintersections <- st_intersects(buildings,rayends,sparse = FALSE)
# If no buildings block max view, return view
if (!TRUE %in% buildintersections){
isovist <- rayends
}
# Calculate isovist if buildings block view from viewpoint
if (TRUE %in% buildintersections){
rays <- lapply(X = 1:length(rayvertices), FUN = function(x) {
pair <- st_combine(c(rayvertices[x],viewpoint))
line <- st_cast(pair, "LINESTRING")
return(line)
})
rays <- do.call(c,rays)
rays <- st_sf(geometry = rays,
id = 1:length(rays))
buildsinmaxview <- buildings[buildintersections]
buildsinmaxview <- st_union(buildsinmaxview)
raysioutsidebuilding <- st_difference(rays,buildsinmaxview)
# Getting each ray segement closest to viewpoint
multilines <- dplyr::filter(raysioutsidebuilding, st_is(geometry, c("MULTILINESTRING")))
singlelines <- dplyr::filter(raysioutsidebuilding, st_is(geometry, c("LINESTRING")))
multilines <- st_cast(multilines,"MULTIPOINT")
multilines <- st_cast(multilines,"POINT")
singlelines <- st_cast(singlelines,"POINT")
# Getting furthest vertex of ray segement closest to view point
singlelines <- singlelines %>%
group_by(id) %>%
dplyr::slice_tail(n = 2) %>%
dplyr::slice_head(n = 1) %>%
summarise(do_union = FALSE,.groups = 'drop') %>%
st_cast("POINT")
multilines <- multilines %>%
group_by(id) %>%
dplyr::slice_tail(n = 2) %>%
dplyr::slice_head(n = 1) %>%
summarise(do_union = FALSE,.groups = 'drop') %>%
st_cast("POINT")
# Combining vertices, ordering clockwise by ray angle and casting to polygon
alllines <- rbind(singlelines,multilines)
alllines <- alllines[order(alllines$id),]
isovist <- st_cast(st_combine(alllines),"POLYGON")
}
isovist
}
Running the function in a loop
It is possible to wrap the function in a loop to get multiple isovists for a multirowsfc_POINT object. There is no need to heed the repeating attributes for all sub-geometries warning as we want that to happen in this case.
isovists <- lapply(X = 1:length(viewpoints), FUN = function(x) {
viewpoint <- viewpoints[x]
st_isovist(buildings = buildings,
viewpoint = viewpoint,
rayno = 41,
raydist = 100)
})
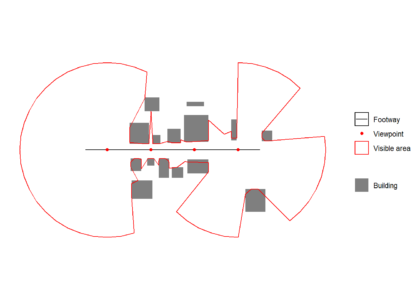
All isovists are unioned to create a visible area polygon, which can see plotted over the original path, viewpoint and building data below.isovists <- do.call(c,isovists)
visareapoly <- st_union(isovists)
ggplot() +
geom_sf(data = buildings,colour = "transparent",aes(fill = 'Building')) +
geom_sf(data = footway, aes(color = 'Footway')) +
geom_sf(data = viewpoints, aes(color = 'Viewpoint')) +
geom_sf(data = visareapoly,fill="transparent",aes(color = 'Visible area')) +
scale_fill_manual(values = c("Building" = "grey50"),
guide = guide_legend(override.aes = list(linetype = c("blank"),
shape = c(NA)))) +
scale_color_manual(values = c("Footway" = "black",
"Viewpoint" = "red",
"Visible area" = "red"),
labels = c("Footway", "Viewpoint","Visible area"))+
guides( color = guide_legend(
order = 1,
override.aes = list(
color = c("black","red","red"),
fill = c("transparent","transparent","white"),
linetype = c("solid","blank", "solid"),
shape = c(NA,16,NA))))+
theme_minimal()+
coord_sf(datum = NA)+
theme(legend.title=element_blank())
Scrivenvar: Writing + Variables
Here is an open source desktop text editor that integrates both externally defined variable definitions and R. In the following demo video, R is used shortly after the 5-minute mark:
Thoughts on the concept of integrated variables?
Download: https://github.com/DaveJarvis/scrivenvar/blob/master/README.md#download
Stay safe everyone.
Thoughts on the concept of integrated variables?
Download: https://github.com/DaveJarvis/scrivenvar/blob/master/README.md#download
Stay safe everyone.
A single loop is not enough. A collection of hello world control structures
As the post on “hello world” functions has been quite appreciated by the R community, here follows the second round of functions for wannabe R programmer.
# If else statement:
# See the code syntax below for if else statement
x=10
if(x>1){
print(“x is greater than 1”)
}else{
print(“x is less than 1”)
}
# See the code below for nested if else statement
x=10
if(x>1 & x<7){
print(“x is between 1 and 7”)} else if(x>8 & x< 15){
print(“x is between 8 and 15”)
}
# For loops:
# Below code shows for loop implementation
x = c(1,2,3,4,5)
for(i in 1:5){
print(x[i])
}
# While loop :
# Below code shows while loop in R
x = 2.987
while(x <= 4.987) {
x = x + 0.987
print(c(x,x-2,x-1))
}
# Repeat Loop:
# The repeat loop is an infinite loop and used in association with a break statement.
# Below code shows repeat loop:
a = 1
repeat{
print(a)
a = a+1
if (a > 4) {
break
}
}
# Break statement:
# A break statement is used in a loop to stop the iterations and flow the control outside of the loop.
#Below code shows break statement:
x = 1:10
for (i in x){
if (i == 6){
break
}
print(i)
}
# Next statement:
# Next statement enables to skip the current iteration of a loop without terminating it.
#Below code shows next statement
x = 1: 4
for (i in x) {
if (i == 2){
next
}
print(i)
}
# function
words = c(“R”, “datascience”, “machinelearning”,”algorithms”,”AI”)
words.names = function(x) {
for(name in x){
print(name)
}
}
words.names(words) # Calling the function
# extract the elements above the main diagonal of a (square) matrix
# example of a correlation matrix
cor_matrix <- matrix(c(1, -0.25, 0.89, -0.25, 1, -0.54, 0.89, -0.54, 1), 3,3)
rownames(cor_matrix) <- c(“A”,”B”,”C”)
colnames(cor_matrix) <- c(“A”,”B”,”C”)
cor_matrix
rho <- list()
name <- colnames(cor_matrix)
var1 <- list()
var2 <- list()
for (i in 1:ncol(cor_matrix)){
for (j in 1:ncol(cor_matrix)){
if (i != j & i<j){
rho <- c(rho,cor_matrix[i,j])
var1 <- c(var1, name[i])
var2 <- c(var2, name[j])
}
}
}
d <- data.frame(var1=as.character(var1), var2=as.character(var2), rho=as.numeric(rho))
d
var1 var2 rho
1 A B -0.25
2 A C 0.89
3 B C -0.54
As programming is the best way to learn and think, have fun programming awesome functions! This post is also shared in R-bloggers and LinkedIn
Azure Machine Learning For R Practitioners With The R SDK
[This article was first published on the Azure Medium channel, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
As probably you already know, Microsoft provided its Azure Machine Learning SDK for Python to build and run machine learning workflows, helping organizations to use massive data sets and bring all the benefits of the Azure cloud to machine learning.
Although Microsoft initially invested in R as the Advanced Analytics preferred language introducing the SQL Server R server and R services in the 2016 version, they abruptly shifted their attention to Python, investing exclusively on it. This basically happened for the following reasons:
- Python’s simple syntax and readability make the language accessible to non-programmers
- The most popular machine learning and deep learning open source libraries (such as Pandas, scikit-learn, TensorFlow, PyTorch, etc.) are deeply used by the Python community
- Python is a better choice for productionalization: it’s relatively very fast; it implements OOPs concepts in a better way; it is scalable (Hadoop/Spark); it has better functionality to interact with other systems; etc.
Azure ML Python SDK Main Key Points
One of the most valuable aspects of the Python SDK is its ease to use and flexibility. You can simply use just few classes, injecting them into your existing code or simply referring to your script files into method calls, in order to accomplish the following tasks:
- Explore your datasets and manage their lifecycle
- Keep track of what’s going on into your machine learning experiments using the Python SDK tracking and logging features
- Transform your data or train your models locally or using the best cloud computation resources needed by your workloads
- Register your trained models on the cloud, package them into container image and deploy them on web services hosted in Azure Container Instances or Azure Kubernetes Services
- Use Pipelines to automate workflows of machine learning tasks (data transformation, training, batch scoring, etc.)
- Use automated machine learning (AutoML) to iterate over many combinations of defined data transformation pipelines, machine learning algorithms and hyperparameter settings. It then finds the best-fit model based on your chosen performance metric.
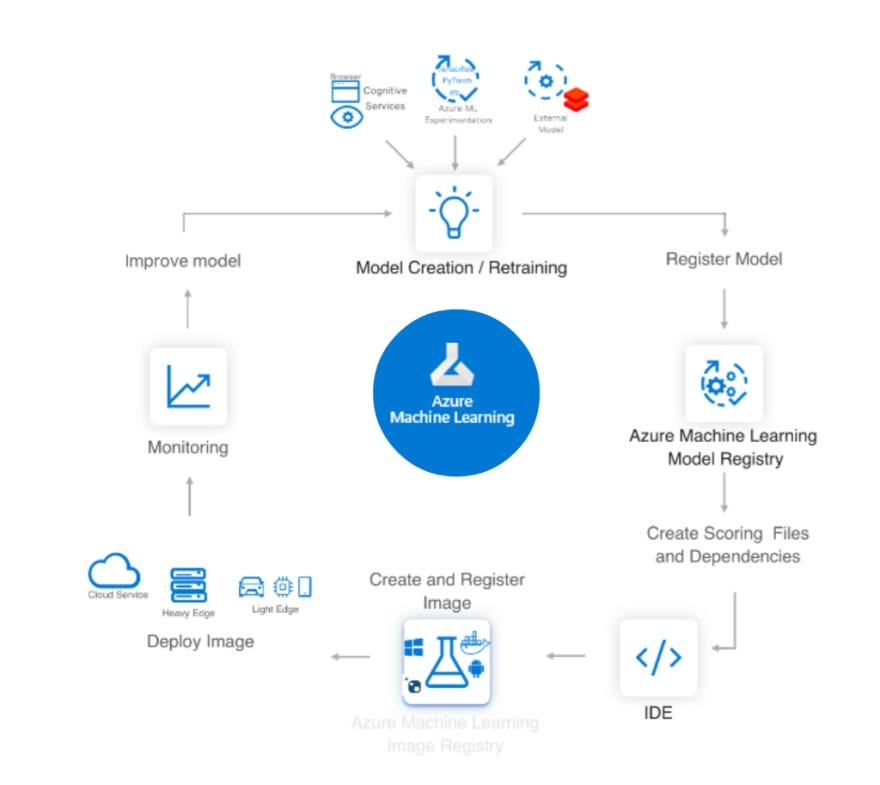
In summary, the scenario is the following one:
What About The R Community Engagement?
In the last 3 years Microsoft pushed a lot over the Azure ML Python SDK, making it a stable product and a first class citizen of the Azure cloud. But they seem to have forgotten all the R professionals who developed a huge amount of data science project all around the world.
We must not forget that in Analytics and Data Science the key of success of a project is to quickly try out a large number of analytical tools and find what’s the best one for the case in analysis. R was born for this reason. It has a lot of flexibility when you want to work with data and build some model, because it has tons of packages and easy of use visualization functionality. That’s why a lot of Analytics projects are developed using R by many statisticians and data scientists.
Fortunately in the last months Microsoft extended a hand to the R community, releasing a new project called Azure Machine Learning R SDK.
Can I Use R To Spin The Azure ML Wheels?
Starting from October 2019 Microsoft released a R interface for Azure Machine Learning SDK on GitHub. The idea behind this project is really straightforward. The Azure ML Python SDK is a way to simplify the access and the use of the Azure cloud storage and computation for machine learning purposes keeping the main code as the one a data scientist developed on its laptop.
Why not allow the Azure ML infrastructure to run also R code (using proper “cooked” Docker images) and let R data scientists call the Azure ML Python SDK methods using R functions?
The interoperability between Python and R is obtained thanks to reticulate. So, once the Python SDK module azureml is imported into any R environment using the import function, functions and other data within the azureml module can be accessed via the $ operator, like an R list.
Obviously, the machine hosting your R environment must have Python installed too in order to make the R SDK work properly.
Let’s start to configure your preferred environment.
Set Up A Development Environment For The R SDK
There are two option to start developing with the R SDK:
- Using an Azure ML Compute Instance (the fastest way, but not the cheaper one!)
- Using your machine (laptop, VM, etc.)
Set Up An Azure ML Compute Instance
Once you created an Azure Machine Learning Workspace through the Azure portal (a basic edition is enough), you can access to the brand new Azure Machine Learning Studio. Under the Compute section, you can create a new Compute Instance, choosing its name and its sizing:
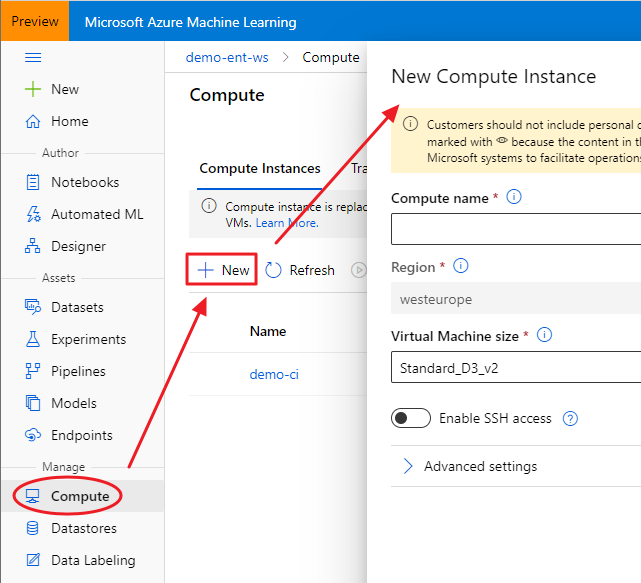
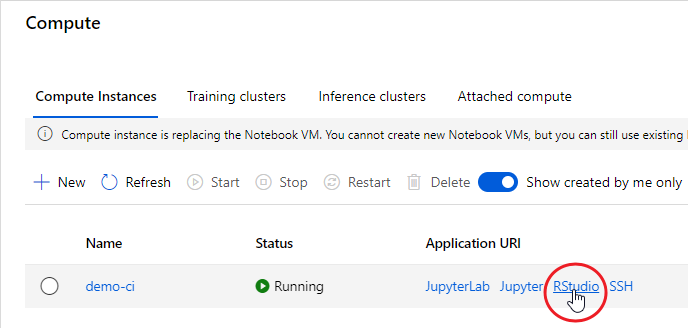
The advantage of using a Compute Instance is that the most used software and libraries by data scientists are already installed, including the Azure ML Python SDK and RStudio Server Open Source Edition. That said, once your Compute Instance is started, you can connect to RStudio using the proper link:
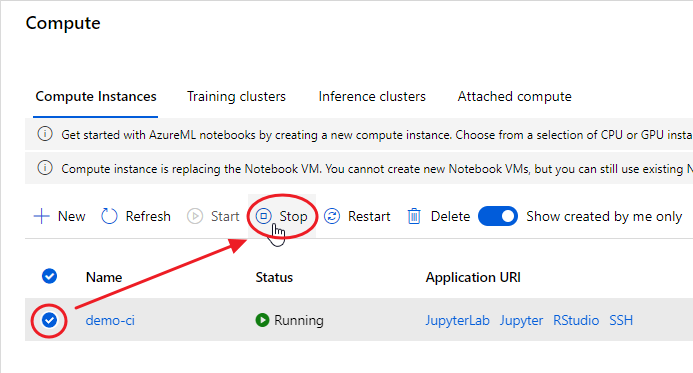
At the end of your experimentation, remember to shut down your Compute Instance, otherwise you’ll be charged according to the chosen plan:
Set Up Your Machine From Scratch
First of all you need to install the R engine from CRAN or MRAN. Then you could also install RStudio Desktop, the preferred IDE of R professionals.
The next step is to install Conda, because the R SDK needs to bind to the Python SDK through reticulate. If you really don’t need Anaconda for specific purposes, it’s recommended to install a lightweight version of it, Miniconda. During its installation, let the installer add the conda installation of Python to your PATH environment variable.
Install The R SDK
Open your RStudio, simply create a new R script (File → New File → R Script) and install the last stable version of Azure ML R SDK package (azuremlsdk) available on CRAN in the following way:install.packages("remotes")
remotes::install_cran("azuremlsdk")
If you want to install the latest committed version of the package from GitHub (maybe because the product team has fixed an annoying bug), you can instead use the following function:
remotes::install_github('https://github.com/Azure/azureml-sdk-for-r')
During the installation you could get this error:

In this case, you just need to set the TZ environment variable with your preferred timezone:
Sys.setenv(TZ="GMT")
Then simply re-install the R SDK.
You may also be asked to update some dependent packages:
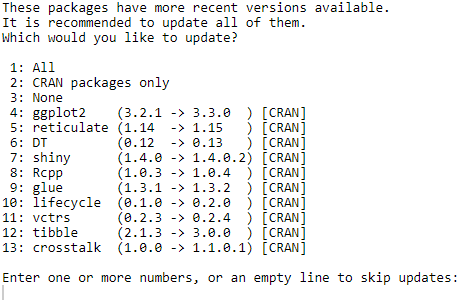
If you don’t have any requirement about dependencies in your project, it’s always better to update them all (put focus on the prompt in the console; press 1; press enter).
If you are on your Compute Instance and you get a warning like the following one:

just put the focus on the console and press “n”, since the Compute Instance environment already has a Conda installation. Microsoft engineers are already investigating on this issue.
You need then to install the Azure ML Python SDK, otherwise your azuremlsdk R package won’t work. You can do that directly from RStudio thanks to an azuremlsdk function:
azuremlsdk::install_azureml(remove_existing_env = TRUE)
The remove_existing_env parameter set to TRUE will remove the default Azure ML SDK environment r-reticulate if previously installed (it’s a way to clean up a Python SDK installation).
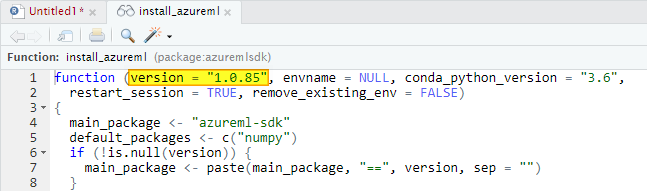
Just keep in mind that in this way you’ll install the version of the Azure ML Python SDK expected by your installed version of the azuremlsdk package. You can check what version you will install putting the cursor over the install_azureml function and visualizing the code definition clicking F2:
Sometimes there are new feature and fixes on the latest version of the Python SDK. If you need to install it, first check what version is available on this link:
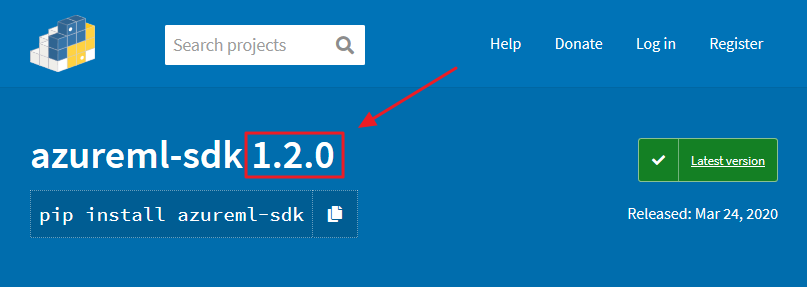
Then use that version number in the following code:
azuremlsdk::install_azureml(version = "1.2.0", remove_existing_env = TRUE)
Sometimes you may need to install an updated version of a single component of the Azure ML Python SDK to test, for example new features. Supposing you want to update the Azure ML Data Prep SDK, here the code you could use:
reticulate::py_install("azureml-dataprep==1.4.2", envname = "r-reticulate", pip = TRUE)
In order to check if the installation is working correctly, try this:
library(azuremlsdk) get_current_run()
It should return something like this:
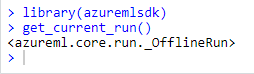
Great! You’re now ready to spin the Azure ML wheels using your preferred programming language: R!
Conclusions
After a long period during which Microsoft focused exclusively on Python SDK to enable data scientists to benefit from Azure computing and storage services, they recently released the R SDK too. This article focuses on the steps needed to install the Azure Machine Learning R SDK on your preferred environment.
Next articles will deal with the R SDK main capabilities.
Using bwimge R package to describe patterns in images of natural structures
This tutorial illustrates how to use the bwimge R package (Biagolini-Jr 2019) to describe patterns in images of natural structures. Digital images are basically two-dimensional objects composed by cells (pixels) that hold information of the intensity of three color channels (red, green and blue). For some file formats (such as png) another channel (the alpha channel) represents the degree of transparency (or opacity) of a pixel. If the alpha channel is equal to 0 the pixel will be fully transparent, if the alpha channel is equal to 1 the pixel will be fully opaque. Bwimage’s images analysis is based on transforming color intensity data to pure black-white data, and transporting the information to a matrix where it is possible to obtain a series of statistics data. Thus, the general routine of bwimage image analysis is initially to transform an image into a binary matrix, and secondly to apply a function to extract the desired information. Here, I provide examples and call attention to the following key aspects: i) transform an image to a binary matrix; ii) introduce distort images function; iii) demonstrate examples of bwimage application to estimate canopy openness; and iv) describe vertical vegetation complexity. The theoretical background of the available methods is presented in Biagolini & Macedo (2019) and in references cited along this tutorial. You can reproduce all examples of this tutorial by typing the given commands at the R prompt. All images used to illustrate the example presented here are in public domain. To download images, check out links in the Data availability section of this tutorial. Before starting this tutorial, make sure that you have installed and loaded bwimage, and all images are stored in your working directory.
install.packages("bwimage") # Download and install bwimage
library("bwimage") # Load bwimage package
setwd(choose.dir()) # Choose your directory. Remember to stores images to be analyzed in this folder.
Transform an image to a binary matrix
Transporting your image information to a matrix is the first step in any bwimage analysis. This step is critical for high quality analysis. The function threshold_color can be used to execute the thresholding process; with this function the averaged intensity of red, green and blue (or only just one channel if desired) is compared to a threshold (argument threshold_value). If the average intensity is less than the threshold (default is 50%) the pixel will be set as black, otherwise it will be white. In the output matrix, the value one represents black pixels, zero represents white pixels and NA represents transparent pixels. Figure 1 shows a comparison of threshold output when using all three channels in contrast to using just one channel (i.e. the effect of change argument channel).
# RGB comparassion
imagename="VD01.JPG"
bush_rgb=threshold_color(imagename, channel = "rgb")
bush_r=threshold_color(imagename, channel = "r")
bush_g=threshold_color(imagename, channel = "g")
bush_b=threshold_color(imagename, channel = "b")
par(mfrow = c(2, 2), mar = c(0,0,0,0))
image(t(bush_rgb)[,nrow(bush_rgb):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_r)[,nrow(bush_r):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_g)[,nrow(bush_g):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_b)[,nrow(bush_b):1], col = c("white","black"), xaxt = "n", yaxt = "n")
dev.off()
In this first example, the overall variations in thresholding are hard to detect with a simple visual inspection. This is because the way images were produced create a high contrast between the vegetation and the white background. Later in this tutorial, more information about this image will be presented. For a clear visual difference in the effect of change argument channel, let us repeat the thresholding process with two new images with more extreme color channel contrasts: sunflower (Figure 2), and Brazilian flag (Figure 3). 

file_name="sunflower.JPG" # for figure 2 file_name="brazilian_flag.JPG" # for figure 03Another important parameter that can affect output quality is the threshold value used to define if the pixel must be converted to black or white (i.e. the argument threshold_value in function threshold_color). Figure 4 compares the effect of using different threshold limits in the threshold output of the same bush image processed above.

# Threshold value comparassion
file_name="VD01.JPG"
bush_1=threshold_color(file_name, threshold_value = 0.1)
bush_2=threshold_color(file_name, threshold_value = 0.2)
bush_3=threshold_color(file_name, threshold_value = 0.3)
bush_4=threshold_color(file_name, threshold_value = 0.4)
bush_5=threshold_color(file_name, threshold_value = 0.5)
bush_6=threshold_color(file_name, threshold_value = 0.6)
bush_7=threshold_color(file_name, threshold_value = 0.7)
bush_8=threshold_color(file_name, threshold_value = 0.8)
par(mfrow = c(4, 2), mar = c(0,0,0,0))
image(t(bush_1)[,nrow(bush_1):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_2)[,nrow(bush_2):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_3)[,nrow(bush_3):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_4)[,nrow(bush_4):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_5)[,nrow(bush_5):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_6)[,nrow(bush_6):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_7)[,nrow(bush_7):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bush_8)[,nrow(bush_8):1], col = c("white","black"), xaxt = "n", yaxt = "n")
dev.off()
The bwimage package s threshold algorithm (described above) provides a simple, powerful and easy to understand process to convert colored images to a pure black and white scale. However, this algorithm was not designed to meet specific demands that may arise according to user applicability. Users interested in specific algorithms can use others R packages, such as auto_thresh_mask (Nolan 2019), to create a binary matrix to apply bwimage function. Below, we provide examples of how to apply four algorithms (IJDefault, Intermodes, Minimum, and RenyiEntropy) from the auto_thresh_mask function (auto_thresh_mask package – Nolan 2019), and use it to calculate vegetation density of the bush image (i.e. proportion of black pixels in relation to all pixels). I repeated the same analysis using bwimage algorithm to compare results. Figure 5 illustrates differences between image output from algorithms.# read tif image
img = ijtiff::read_tif("VD01.tif")
# IJDefault
IJDefault_mask= auto_thresh_mask(img, "IJDefault")
IJDefault_matrix = 1*!IJDefault_mask[,,1,1]
denseness_total(IJDefault_matrix)
# 0.1216476
# Intermodes
Intermodes_mask= auto_thresh_mask(img, "Intermodes")
Intermodes_matrix = 1*!Intermodes_mask[,,1,1]
denseness_total(Intermodes_matrix)
# 0.118868
# Minimum
Minimum_mask= auto_thresh_mask(img, "Minimum")
Minimum_matrix = 1*!Minimum_mask[,,1,1]
denseness_total(Minimum_matrix)
# 0.1133822
# RenyiEntropy
RenyiEntropy_mask= auto_thresh_mask(img, "RenyiEntropy")
RenyiEntropy_matrix = 1*!RenyiEntropy_mask[,,1,1]
denseness_total(RenyiEntropy_matrix)
# 0.1545827
# bWimage
bw_matrix=threshold_color("VD01.JPG")
denseness_total(bw_matrix)
# 0.1398836
The calculated vegetation density for each algorithm was:
| Algorithm | Vegetation density |
| IJDefault | 0.1334882 |
| Intermodes | 0.1199355 |
| Minimum | 0.1136603 |
| RenyiEntropy | 0.1599628 |
| Bwimage | 0.1397852 |
For a description of each algorithms, check out the documentation of function auto_thresh_mask and its references.
?auto_thresh_mask

par(mar = c(0,0,0,0)) ## Remove the plot margin
image(t(bw_matrix)[,nrow(bw_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(bw_matrix)[,nrow(bw_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(IJDefault_matrix)[,nrow(IJDefault_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(Intermodes_matrix)[,nrow(Intermodes_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(Minimum_matrix)[,nrow(Minimum_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(RenyiEntropy_matrix)[,nrow(RenyiEntropy_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
dev.off()
If you applied the above functions, you may have noticed that high resolution images imply in large R objects that can be computationally heavy (depending on your GPU setup). The argument compress_method from threshold_color and threshold_image_list functions can be used to reduce the output matrix. It reduces GPU usage and time necessary to run analyses. But it is necessary to keep in mind that by reducing resolution the accuracy of data description will be lowered. To compare different resamplings, from a figure of 2500×2500 pixels, check out figure 2 from Biagolini-Jr and Macedo (2019) . The available methods for image reduction are: i) frame_fixed, which resamples images to a desired target width and height; ii) proportional, which resamples the image by a given ratio provided in the argument “proportion”; iii) width_fixed, which resamples images to a target width, and also reduces the image height by the same factor. For instance, if the original file had 1000 pixels in width, and the new width_was set to 100, height will be reduced by a factor of 0.1 (100/1000); and iv) height_fixed, analogous to width_fixed, but assumes height as reference.
Distort images function
In many cases image distortion is intrinsic to image development, for instance global maps face a trade-off between distortion and the total amount of information that can be presented in the image. The bwimage package has two functions for distorting images (stretch and compress functions) which allow allow application of four different algorithms for mapping images, from circle to square and vice versa. Algorithms were adapted from Lambers (2016). Figure 6 compares image distortion of two images using stretch and compress functions, and all available algorithms.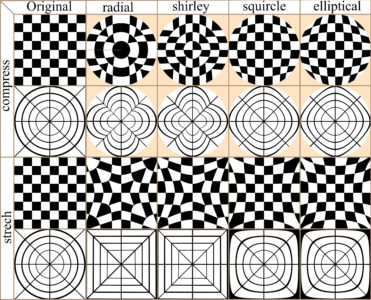
# Distortion images
chesstablet_matrix=threshold_color("chesstable.JPG")
target_matrix=threshold_color("target.JPG")
## Compress
# chesstablet_matrix
comp_cmr=compress(chesstablet_matrix,method="radial",background=0.5)
comp_cms=compress(chesstablet_matrix,method="shirley",background=0.5)
comp_cmq=compress(chesstablet_matrix,method="squircle",background=0.5)
comp_cme=compress(chesstablet_matrix,method="elliptical",background=0.5)
# target_matrix
comp_tmr=compress(target_matrix,method="radial",background=0.5)
comp_tms=compress(target_matrix,method="shirley",background=0.5)
comp_tmq=compress(target_matrix,method="squircle",background=0.5)
comp_tme=compress(target_matrix,method="elliptical",background=0.5)
## stretch
# chesstablet_matrix
stre_cmr=stretch(chesstablet_matrix,method="radial")
stre_cms=stretch(chesstablet_matrix,method="shirley")
stre_cmq=stretch(chesstablet_matrix,method="squircle")
stre_cme=stretch(chesstablet_matrix,method="elliptical")
# target_matrix
stre_tmr=stretch(target_matrix,method="radial")
stre_tms=stretch(target_matrix,method="shirley")
stre_tmq=stretch(target_matrix,method="squircle")
stre_tme=stretch(target_matrix,method="elliptical")
# Plot
par(mfrow = c(4,5), mar = c(0,0,0,0))
image(t(chesstablet_matrix)[,nrow(chesstablet_matrix):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_cmr)[,nrow(comp_cmr):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_cms)[,nrow(comp_cms):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_cmq)[,nrow(comp_cmq):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_cme)[,nrow(comp_cme):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(target_matrix)[,nrow(target_matrix):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_tmr)[,nrow(comp_tmr):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_tms)[,nrow(comp_tms):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_tmq)[,nrow(comp_tmq):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(comp_tme)[,nrow(comp_tme):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(chesstablet_matrix)[,nrow(chesstablet_matrix):1], col = c("white","bisque","black"), xaxt = "n", yaxt = "n")
image(t(stre_cmr)[,nrow(stre_cmr):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_cms)[,nrow(stre_cms):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_cmq)[,nrow(stre_cmq):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_cme)[,nrow(stre_cme):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(target_matrix)[,nrow(target_matrix):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_tmr)[,nrow(stre_tmr):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_tms)[,nrow(stre_tms):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_tmq)[,nrow(stre_tmq):1], col = c("white","black"), xaxt = "n", yaxt = "n")
image(t(stre_tme)[,nrow(stre_tme):1], col = c("white","black"), xaxt = "n", yaxt = "n")
dev.off()
Application examples
Estimate canopy openness
Canopy openness is one of the most common vegetation parameters of interest in field ecology surveys. Canopy openness can be calculated based on pictures on the ground or by an aerial system e.g. (Díaz and Lencinas 2018). Next, we demonstrate how to estimate canopy openness, using a picture taken on the ground. The photo setup is described in Biagolini-Jr and Macedo (2019). Canopy closure can be calculated by estimating the total amount of vegetation in the canopy. Canopy openness is equal to one minus the canopy closure. You can calculate canopy openness for the canopy image example (provide by bwimage package) using the following code:canopy=system.file("extdata/canopy.JPG",package ="bwimage")
canopy_matrix=threshold_color(canopy,"jpeg", compress_method="proportional",compress_rate=0.1)
1-denseness_total(canopy_matrix) # canopy openness
For users interested in deeper analyses of canopy images, I also recommend the caiman package.Describe vertical vegetation complexity
There are several metrics to describe vertical vegetation complexity that can be performed using a picture of a vegetation section against a white background, as described by Zehm et al. (2003). Part of the metrics presented by these authors were implemented in bwimage, and the following code shows how to systematically extract information for a set of 12 vegetation pictures. A description of how to obtain a digital image for the following methods is presented in Figure 7.
files_names= c("VD01.JPG", "VD02.JPG", "VD03.JPG", "VD04.JPG", "VD05.JPG", "VD06.JPG", "VD07.JPG", "VD08.JPG", "VD09.JPG", "VD10.JPG", "VD11.JPG", "VD12.JPG")
image_matrix_list=threshold_image_list(files_names, filetype = "jpeg",compress_method = "frame_fixed",target_width = 500,target_height=500)
Once you obtain the list of matrices, you can use a loop or apply family functions to extract information from all images and save them into objects or a matrix. I recommend storing all image information in a matrix, and exporting this matrix as a csv file. It is easier to transfer information to another database software, such as an excel sheet. Below, I illustrate how to apply functions denseness_total, heigh_propotion_test, and altitudinal_profile, to obtain information on vegetation density, a logical test to calculate the height below which 75% of vegetation denseness occurs, and the average height of 10 vertical image sections and its SD (note: sizes expressed in cm).
answer_matrix=matrix(NA,ncol=4,nrow=length(image_matrix_list))
row.names(answer_matrix)=files_names
colnames(answer_matrix)=c("denseness", "heigh 0.75", "altitudinal mean", "altitudinal SD")
# Loop to analyze all images and store values in the matrix
for(i in 1:length(image_matrix_list)){
answer_matrix[i,1]=denseness_total(image_matrix_list[[i]])
answer_matrix[i,2]=heigh_propotion_test(image_matrix_list[[i]],proportion=0.75, height_size= 100)
answer_matrix[i,3]=altitudinal_profile(image_matrix_list[[i]],n_sections=10, height_size= 100)[[1]]
answer_matrix[i,4]=altitudinal_profile(image_matrix_list[[i]],n_sections=10, height_size= 100)[[2]]
}
Finally, we analyze information of holes data (i.e. vegetation gaps), in 10 image lines equally distributed among image (Zehm et al. 2003). For this purpose, we use function altitudinal_profile. Sizes are expressed in number of pixels.# set a number of samples
nsamples=10
# create a matrix to receive calculated values
answer_matrix2=matrix(NA,ncol=7,nrow=length(image_matrix_list)*nsamples)
colnames(answer_matrix2)=c("Image name", "heigh", "N of holes", "Mean size", "SD","Min","Max")
# Loop to analyze all images and store values in the matrix
for(i in 1:length(image_matrix_list)){
for(k in 1:nsamples){
line_heigh= k* length(image_matrix_list[[i]][,1])/nsamples
aux=hole_section_data(image_matrix_list[[i]][line_heigh,] )
answer_matrix2[((i-1)*nsamples)+k ,1]=files_names[i]
answer_matrix2[((i-1)*nsamples)+k ,2]=line_heigh
answer_matrix2[((i-1)*nsamples)+k ,3:7]=aux
}}
write.table(answer_matrix2, file = "Image_data2.csv", sep = ",", col.names = NA, qmethod = "double")
Data availability
To download images access: https://figshare.com/articles/image_examples_for_bwimage_tutorial/9975656References
Biagolini-Jr C (2019) bwimage: Describe Image Patterns in Natural Structures. https://cran.r-project.org/web/packages/bwimage/index.htmlBiagolini-Jr C, Macedo RH (2019) bwimage: A package to describe image patterns in natural structures. F1000Research 8 https://f1000research.com/articles/8-1168
Díaz GM, Lencinas JD (2018) Model-based local thresholding for canopy hemispherical photography. Canadian Journal of Forest Research 48:1204-1216 https://www.nrcresearchpress.com/doi/abs/10.1139/cjfr-2018-0006
Lambers M (2016) Mappings between sphere, disc, and square. Journal of Computer Graphics Techniques Vol 5:1-21 http://jcgt.org/published/0005/02/01/paper-lowres.pdf
Nolan R (2019) autothresholdr: An R Port of the ‘ImageJ’ Plugin ‘Auto Threshold. https://cran.r-project.org/web/packages/autothresholdr/
Zehm A, Nobis M, Schwabe A (2003) Multiparameter analysis of vertical vegetation structure based on digital image processing. Flora-Morphology, Distribution, Functional Ecology of Plants 198:142-160 https://doi.org/10.1078/0367-2530-00086
Does imputing model labels using the model predictions can improve it’s performance?
In some scenarios a data scientist may want to train a model for which there exists an abundance of observations, but only a small fraction of is labeled, making the sample size available to train the model rather small. Although there’s plenty of literature on the subject (e.g. “Active learning”, “Semi-supervised learning” etc) one may be tempted (maybe due to fast approaching deadlines) to train a model with the labelled data and use it to impute the missing labels.
While for some the above suggestion might seem simply incorrect, I have encountered such suggestions on several occasions and had a hard time refuting them. To make sure it wasn’t just the type of places I work at I went and asked around in 2 Israeli (sorry non Hebrew readers) machine learning oriented Facebook groups about their opinion: Machine & Deep learning Israel and Statistics and probability group. While many were referring me to methods discussed in the literature, almost no one indicated the proposed method was utterly wrong.
I decided to perform a simulation study to get a definitive answer once and for all. If you’re interested in reading what were the results see my analysis on Github.
Reproducible development with Rmarkdown and Github
I’m pretty sure most readers of this blog are already familiar with Rmarkdown and Github. In this post I don’t pretend to invent the wheel but rather give a quick run-down of how I set-up and use these tools to produce high quality and scalable (in human time) reproducible data science development code.
Below is in illustration of how that process might look like:
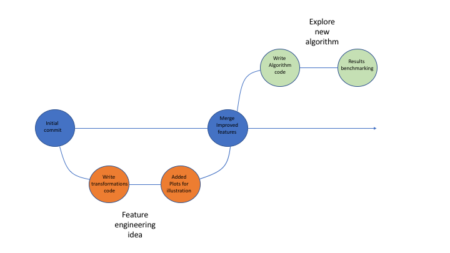
Using Github allows one to easily package his code, supporting files etc (using repos) and share it with fellow researches, which can in turn clone the repo, re-run the code and go through all the development iterations without a hassle.
To summarize this section, I would highly recommend developing with Rmd files rather than R files.
https://github.com/IyarLin/boilerplate-script
Github
While data science processes usually don’t involve the exact same workflows like software development (for which Git was originally intended) I think Git is actually very well suited to the iterative nature of data-science tasks. When walking down different avenues in the exploration path, it’s worth while to have them reside in different branches. That way instead of jotting down in general pointers what you did along with some code snippets in some text file (or god-forbid word when you want to have images as well) you can instead go back to the relevant branch, see the different iterations and read a neat report with code and images. You can even re-visit ideas that didn’t make it into the master branch. Be sure to use informative branch names and commit messages!Below is in illustration of how that process might look like:
Using Github allows one to easily package his code, supporting files etc (using repos) and share it with fellow researches, which can in turn clone the repo, re-run the code and go through all the development iterations without a hassle.
Rmarkdown
Most people familiar with Rmarkdown know it’s a great tool to write neat reports in all sorts of formats (html, PDF and even word!). One format that really makes it a great combo with Github is the github_document format. While one can’t view HTML files on Github, the output file from a github_document knit is an .md file which renders perfectly well on github, supporting images, tables, math, table of contents and many other. What some may not realize is that Rmarkdown is also a great development tool in itself. It behaves much like the popular Jupiter notebooks, with plots, tables and equations showing next to the code that generated them. What’s more, it has tons of cool features that really support reproducible development such as:- The first r-chunk (labled “setup” in the Rstudio template) always runs once when you execute code within chunks following it (pressing ctrl+Enter). It’s handy to load all packages used in later chucks (I like installing missing ones too) in this chunk such that whenever you run code within any of the chunks below it the needed packages are loaded.
- When running code from within a chunk (pressing ctrl+Enter) the working directory will always be the one which the .Rmd file is located at. In short this means no more worrying about setting the working directory – be it when working on several projects simultaneously or when cloning a repo from Github.
- It has many cool code execution tools such as a button to run code in all chunks up to the current one, run all code in the current chunk and it has a green progress bar so you don’t get lost too!
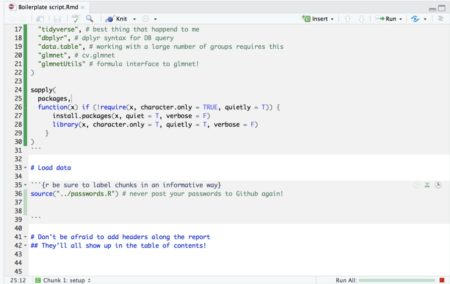
- If your script is so long that scrolling around it becomes tedious, you can use this neat feature in Rstudio: When viewing Rmarkdown files you can view an interactive table of contents that enables you to jump between sections (defined by # headers) in your code:
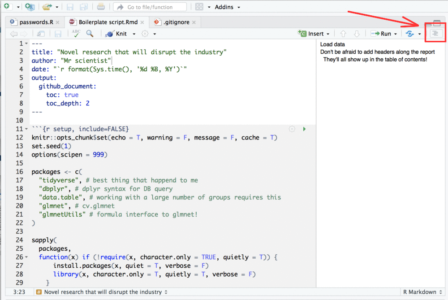
To summarize this section, I would highly recommend developing with Rmd files rather than R files.
A few set-up tips
- Place a file “passwords.R” with all passwords in the directory to which you clone repos and source it via the Rmd. That way you don’t accidentally publish your passwords to Github
- I like working with cache on all chunks in my Rmd. It’s usually good practice to avoid uploading the cache files generated in the process to Github so be sure to add to your .gitignore file the file types: *.RData, *.rdb, *.rdx, *.rds, *__packages
- Github renders CSV files pretty nicely (and enables searching them conveniently) so if you have some reference tables you want to include and you have a *.csv entry in your .gitignore file, you may want to add to your .gitignore the following entry: !reference_table_which_renders_nicely_on_github.csv to exclude it from the exclusion list.
Sample Reproducible development repo
Feel free to clone the sample reproducible development repo below and get your reproducible project running ASAP!https://github.com/IyarLin/boilerplate-script
Lyric Analysis with NLP and Machine Learning using R: Part One – Text Mining
June 22
By Debbie Liske
This is Part One of a three part tutorial series originally published on the DataCamp online learning platform in which you will use R to perform a variety of analytic tasks on a case study of musical lyrics by the legendary artist, Prince. The three tutorials cover the following:
Musical lyrics may represent an artist’s perspective, but popular songs reveal what society wants to hear. Lyric analysis is no easy task. Because it is often structured so differently than prose, it requires caution with assumptions and a uniquely discriminant choice of analytic techniques. Musical lyrics permeate our lives and influence our thoughts with subtle ubiquity. The concept of Predictive Lyrics is beginning to buzz and is more prevalent as a subject of research papers and graduate theses. This case study will just touch on a few pieces of this emerging subject.

Prince: The Artist
To celebrate the inspiring and diverse body of work left behind by Prince, you will explore the sometimes obvious, but often hidden, messages in his lyrics. However, you don’t have to like Prince’s music to appreciate the influence he had on the development of many genres globally. Rolling Stone magazine listed Prince as the 18th best songwriter of all time, just behind the likes of Bob Dylan, John Lennon, Paul Simon, Joni Mitchell and Stevie Wonder. Lyric analysis is slowly finding its way into data science communities as the possibility of predicting “Hit Songs” approaches reality.
Check out the article here!

(reprint by permission of DataCamp online learning platform)
By Debbie Liske
This is Part One of a three part tutorial series originally published on the DataCamp online learning platform in which you will use R to perform a variety of analytic tasks on a case study of musical lyrics by the legendary artist, Prince. The three tutorials cover the following:
- Part One: Text Mining and Exploratory Analysis (beginner)
- Part Two: Sentiment Analysis and Topic Modeling with NLP (intermediate)
- Part Three: Predictive Analytics using Machine Learning (intermediate -advanced)
Musical lyrics may represent an artist’s perspective, but popular songs reveal what society wants to hear. Lyric analysis is no easy task. Because it is often structured so differently than prose, it requires caution with assumptions and a uniquely discriminant choice of analytic techniques. Musical lyrics permeate our lives and influence our thoughts with subtle ubiquity. The concept of Predictive Lyrics is beginning to buzz and is more prevalent as a subject of research papers and graduate theses. This case study will just touch on a few pieces of this emerging subject.
Prince: The Artist
To celebrate the inspiring and diverse body of work left behind by Prince, you will explore the sometimes obvious, but often hidden, messages in his lyrics. However, you don’t have to like Prince’s music to appreciate the influence he had on the development of many genres globally. Rolling Stone magazine listed Prince as the 18th best songwriter of all time, just behind the likes of Bob Dylan, John Lennon, Paul Simon, Joni Mitchell and Stevie Wonder. Lyric analysis is slowly finding its way into data science communities as the possibility of predicting “Hit Songs” approaches reality.
Prince was a man bursting with music – a wildly prolific songwriter, a virtuoso on guitars, keyboards and drums and a master architect of funk, rock, R&B and pop, even as his music defied genres. – Jon Pareles (NY Times)In this tutorial, Part One of the series, you’ll utilize text mining techniques on a set of lyrics using the tidy text framework. Tidy datasets have a specific structure in which each variable is a column, each observation is a row, and each type of observational unit is a table. After cleaning and conditioning the dataset, you will create descriptive statistics and exploratory visualizations while looking at different aspects of Prince’s lyrics.
Check out the article here!
(reprint by permission of DataCamp online learning platform)