Intended Audience:
Practitioners who wish to learn the nuts and bolts of the R language; anyone who wants “to turn ideas into software, quickly and faithfully.”
Knowledge Level: Experience with handling data (e.g. spreadsheets) or hands-on familiarity with any programming language.
Workshop Description
This afternoon workshop launches your tenure as a user of R, the well-known open-source platform for data science and machine learning. The workshop stands alone as the perfect way to get started with R, or may serve to prepare for the more advanced full-day hands-on workshop, “R for Predictive Modeling”.
Designed for newcomers to the language of R, “R Bootcamp” covers the R ecosystem and core elements of the language, so you attain the foundations for becoming an R user. Topics include common tools for data import, manipulation and export. If time allows, other topics will be covered, such: as graphical systems in R (e.g. LATTICE and GGPLOT) and automated reporting.
The instructor will guide attendees on hands-on execution with R, covering:
A working knowledge of the R system
The strengths and limitations of the R language
Core language features
The best tools for merging, processing and arranging data
Hardware: Bring Your Own Laptop
Each workshop participant is required to bring their own laptop running Windows or OS X. The software used during this training program, R, is free and readily available for download.
Attendees receive an electronic copy of the course materials and related R code at the conclusion of the workshop.
Intended Audience:
Practitioners who wish to learn how to execute on predictive analytics by way of the R language; anyone who wants “to turn ideas into software, quickly and faithfully.”
Knowledge Level: Either hands-on experience with predictive modeling (without R) or both hands-on familiarity with any programming language (other than R) and basic conceptual knowledge about predictive modeling is sufficient background and preparation to participate in this workshop.
The 2 1/2 hour “R Bootcamp” is recommended preparation for this workshop.
Workshop Description
This one-day session provides a hands-on introduction to R, the well-known open-source platform for data analysis. Real examples are employed in order to methodically expose attendees to best practices driving R and its rich set of predictive modeling (machine learning) packages, providing hands-on experience and know-how. R is compared to other data analysis platforms, and common pitfalls in using R are addressed.
The instructor will guide attendees on hands-on execution with R, covering:
A working knowledge of the R system
The strengths and limitations of the R language
Preparing data with R, including splitting, resampling and variable creation
Developing predictive models with R, including the use of these machine learning methods: decision trees, ensemble methods, and others.
Visualization: Exploratory Data Analysis (EDA), and tools that persuade
Evaluating predictive models, including viewing lift curves, variable importance and avoiding overfitting
Hardware: Bring Your Own Laptop
Each workshop participant is required to bring their own laptop running Windows or OS X. The software used during this training program, R, is free and readily available for download.
Attendees receive an electronic copy of the course materials and related R code at the conclusion of the workshop.
Brennan is a self-proclaimed data nerd. He has been working in the financial industry for the past ten years and is striving to save the world with a little help from our machine friends.
He has held cyber security, data scientist, and leadership roles at JP Morgan Chase, the Federal Reserve Bank of New York, Bloomberg, and Goldman Sachs.
Brennan holds a Masters in Business Analytics from New York University and participates in the data science community with his non-profit pro-bono work at DataKind, and as a co-organizer for the NYU Data Science and Analytics Meetup.
Brennan is also an instructor at the New York Data Science Academy and teaches data science courses in R and Python.
I have written a small booklet (about 120 pages A5 size) on statistics and origami
it is a very simple -basic book, useful for introductory courses.
There are several R examples and the R script for each of them
R programmers are not necessary data scientists, but rather software engineers. We have an entirely new multitrack focus area that helps engineers learn AI skills – AI for Engineers. This focus area is designed specifically to help programmers get familiar with AI-driven software that utilizes deep learning and machine learning models to enable conversational AI, autonomous machines, machine vision, and other AI technologies that require serious engineering.
For example, some use R in reinforcement learning – a popular topic and arguably one of the best techniques for sequential decision making and control policies. At ODSC East, Leonardo De Marchi of Badoo will present “Introduction to Reinforcement Learning,” where he will go over the fundamentals of RL all the way to creating unique algorithms, and everything in between.
Well, what if you’re missing data? That will mess up your entire workflow – R or otherwise. In “Good, Fast, Cheap: How to do Data Science with Missing Data,” Matt Brems of General Assembly, you will start by visualizing missing data and identifying the three different types of missing data, which will allow you to see how they affect whether we should avoid, ignore, or account for the missing data. Matt will give you practical tips for working with missing data and recommendations for integrating it with your workflow.
How about getting some context? In “Intro to Technical Financial Evaluation with R” with Ted Kwartler of Liberty Mutual and Harvard Extension School, you will learn how to download and evaluate equities with the TTR (technical trading rules) package. You will evaluate an equity according to three basic indicators and introduce you to backtesting for more sophisticated analyses on your own.
There is a widespread belief that the twin modeling goals of prediction and explanation are in conflict. That is, if one desires superior predictive power, then by definition one must pay a price of having little insight into how the model made its predictions. In “Explaining XGBoost Models – Tools and Methods” with Brian Lucena, PhD, Consulting Data Scientist at Agentero you will work hands-on using XGBoost with real-world data sets to demonstrate how to approach data sets with the twin goals of prediction and understanding in a manner such that improvements in one area yield improvements in the other.
What about securing your deep learning frameworks? In “Adversarial Attacks on Deep Neural Networks” with Sihem Romdhani, Software Engineer at Veeva Systems, you will answer questions such as how do adversarial attacks pose a real-world security threat? How can these attacks be performed? What are the different types of attacks? What are the different defense techniques so far and how to make a system more robust against adversarial attacks? Get these answers and more here.
Data science is an art. In “Data Science + Design Thinking: A Perfect Blend to Achieve the Best User Experience,” Michael Radwin, VP of Data Science at Intuit, will offer a recipe for how to apply design thinking to the development of AI/ML products. You will learn to go broad to go narrow, focusing on what matters most to customers, and how to get customers involved in the development process by running rapid experiments and quick prototypes.
Lastly, your data and hard work mean nothing if you don’t do anything with it – that’s why the term “data storytelling” is more important than ever. In “Data Storytelling: The Essential Data Science Skill,” Isaac Reyes, TedEx speaker and founder of DataSeer, will discuss some of the most important of data storytelling and visualization, such as what data to highlight, how to use colors to bring attention to the right numbers, the best charts for each situation, and more.
Ready to apply all of your R skills to the above situations? Learn more techniques, applications, and use cases at ODSC East 2019 in Boston this April 30 to May 3!Save 10% off the public ticket price when you use the code RBLOG10 today.Register Here
More on ODSC:
ODSC East 2019 is one of the largest applied data science conferences in the world. Speakers include some of the core contributors to many open source tools, libraries, and languages. Attend ODSC East in Boston this April 30 to May 3 and learn the latest AI & data science topics, tools, and languages from some of the best and brightest minds in the field.
Coke and Pepsi have been fighting the cola wars for over one hundred years and, by now, if you are still willing to consume soft drinks, you are either a Coke person or a Pepsi person. How did you choose? Why are you so convinced and passionate about the choice? Which side is winning and why? Similarly, some users of R prefer enhancements to data frame provided by data.table while others lean towards tidy-related framework. Both popular R packages provide functionality that is lacking in the built-in R data frame. While the competition between them spans much less than one hundred years, can we draw similarities and learn from the deeper understanding of consumption choices exhibited in Coke vs Pepsi battle? One of the basic measures of consumer enthusiasm is a so-called Net Promoter Score (NPS).
In the business world, the NPS is widely used for products and services and it can be a leading indicator for market share growth. One simple question is the basis for the NPS – How likely are you to recommend the brand to your friends or colleagues, using a scale from 0 to 10? Respondents who give a score of 0-6 belong to the Detractors group. These unhappy customers will tend to voice their displeasure and can damage a brand. The Passive group gives a score of 7-8, and they are generally satisfied, but they are also open to changing brands. The Promoters are the loyal enthusiasts who give a score of 9-10, and these coveted cheerleaders will fuel the growth of a brand. To calculate the NPS, subtract the percentage of Detractors from the percentage of Promoters. A minimum score of -100 means everyone is a Detractor, and the elusive maximum score of +100 means everyone is a Promoter.
How does the NPS play out in the cola wars? For 2019 there is a standoff, with Coca-cola and Pepsi tied at 20. Instinct tells us that a NPS over 0 is good, but how good? The industry average for fast moving consumer goods is 30 (“Pepsi Net Promoter Score 2019 Benchmarks”, 2019). We will let you be the judge.
In the Fall of 2018 we surveyed R users identified by the first commit that added a dependency on either package to a public repository (a repository hosted on GitHub, BitBucket, and other so-called software forges) with some code written in R language. The results of the full survey can be seen here. The responding project contributors were identified as “data.table” users or “tidy” users by their inclusion of the corresponding R libraries in their projects. The survey responses were used to obtain a Net Promoter Score.
Unlike the cola wars, the results of the survey indicate that data.table has an industry average NPS of 28.6, while tidy brings home the gold with a 59.4. What makes tidy users so much more enthusiastic in their choice of data structure library? Tune in for next installment where we try to track down what factors drive a users choice.
References: “Pepsi Net Promoter Score 2019 Benchmarks.” Pepsi Net Promoter Score 2019 Benchmarks | Customer.guru, customer.guru/net-promoter-score/pepsi.
For many, R is the go-to language when it comes to data analysis and predictive analytics. However many data scientists are also expanding their use of R to include machine learning and deep learning. These are exciting new topics, and ODSC East — where thousands of data scientists will gather this year in Boston — has several speakers scheduled to lead trainings in R from April 30 to May 3.Can’t make it to Boston? Sign up now to Livestream the conference in its entirety so as not to miss out on the latest methodologies and newest developments.Some of the most anticipated talks this year at the conference include “Mapping Geographic Data in R” and “Modeling the tidyverse,” which will be further discussed, below. For a full list of speakers, click here.Highlighted R-Specific Talks:In “Machine Learning in R” Part 1 and Part 2, with Jared Lander of the Columbia Business School, you will learn everything ranging from the theoretical backing behind ML up through the nitty-gritty technical side of implementation.Jared will also present “Introduction to R-Markdown in Shiny,” where he will cover everything from formatting and integrating R, to reactive expressions and outputs like text, tables, and plots. He will also give an “Intermediate R-Markdown in Shiny” presentation to go a bit deeper into the subject.With everything Jared is presenting on, you definitely have quite a lot to work with for R and Shiny. Why not take it a step further and be able to communicate your findings? Alyssa Columbus of Pacific Life will present “Data Visualization with R Shiny,” where she will show you how to build simple yet robust Shiny applications and how to build data visualizations. You’ll learn how to use R to prepare data, run simple analyses, and display the results in Shiny web applications as you get hands-on experience creating effective and efficient data visualizations.For many businesses, non-profits, educational institutions, and more, location is important in developing the best products, services, and messages. In “Data Visualization with R Shiny” with Joy Payton of the Children’s Hospital of Philadelphia, you will use R to take public data from various sources and combine them to find statistically interesting patterns and display them in static and dynamic, web-ready maps.The “tidyverse” collects some of the most versatile R packages: ggplot2, dplyr, tidyr, readr, purrr, and tibble, all working in harmony to clean, process, model, and visualize data. In “Modeling in the tidyverse” author and creator of the Caret R package, Max Kuhn, Phd, will provide a concise overview of the system and will provide examples and context for implementation. Factorization machines are a relatively new and powerful tool for modeling high-dimensional and sparse data. Most commonly they are used as recommender systems by modeling the relationship between users and items. Here, Jordan Bakerman, PhD and Robert Blanchard of SAS will present “Building Recommendation Engines and Deep Learning Models Using Python, R and SAS,” where you will use recurrent neural networks to analyze sequential data and improve the forecast performance of time series data, and use convolutional neural networks for image classification.Connecting it AllR isn’t siloed language; new machine and deep learning packages are being added monthly and data scientists are finding new ways to utilize it in machine learning, deep learning, data visualization, and more. Attend ODSC East this April 30 to May 3 and learn all there is to know about the current state of R, and walk away with tangible experience!Save 30% off ticket prices for a limited time when you use the code RBLOG10 today.
Register HereMore on ODSC:ODSC East 2019 is one of the largest applied data science conferences in the world. Speakers include some of the core contributors to many open source tools, libraries, and languages. Attend ODSC East in Boston this April 30 to May 3 and learn the latest AI & data science topics, tools, and languages from some of the best and brightest minds in the field.
In my daily work I often have to transform a long table to a wide matrix so accommodate some function. At some stage in my life I came across the reshape2 package, and I have been with that philosophy ever since – I find it makes data wrangling easy and straight forward. I particularly like the tidyverse philosophy where data should be in a long table, where one row is an observation, and a column a parameter. It just makes sense.
However, I quite often have to transform the data into another format, a wide matrix especially for functions of the vegan package, and one day I wondering how to do that in the fastest way.
The code to create the test sets and benchmark the functions is in section ‘Settings and script’ at the end of this document.
I created several data sets that mimic the data I usually work with in terms of size and values. The data sets have 2 to 10 groups, where each group can have up to 50000, 100000, 150000, or 200000 samples. The methods xtabs() from base R, dcast() from data.table, dMcast() from Matrix.utils, and spread() from tidyr were benchmarked using microbenchmark() from the package microbenchmark. Each method was evaluated 10 times on the same data set, which was repeated for 10 randomly generated data sets.
After the 10 x 10 repetitions of casting from long to wide it is clear the spread() is the worst. This is clear when we focus on the size (figure 1). Figure 1. Runtime for 100 repetitions of data sets of different size and complexity.
And the complexity (figure 2). Figure 2. Runtime for 100 repetitions of data sets of different complexity and size.
Close up on the top three methods
Casting from a long table to a wide matrix is clearly slowest with spread(), where as the remaining look somewhat similar. A direct comparison of the methods show a similarity in their performance, with dMcast() from the package Matrix.utils being better — especially with the large and more complex tables (figure 3). Figure 3. Direct comparison of set size.
I am aware, that it might be to much to assume linearity, between the computation times at different set sizes, but I do believe it captures the point – dMcast() and dcast() are similar, with advantage to dMcast() for large data sets with large number of groups. It does, however, look like dcast() scales better with the complexity (figure 4). Figure 4. Direct comparison of number groups.
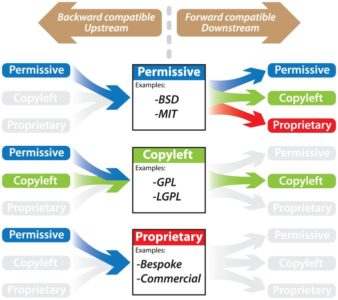
Being a data scientist in a startup I can program with several languages, but often R is a natural choice. Recently I wanted my company to build a product based on R. It simply seemed like a perfect fit.But this turned out to be a slippery slope into the open-source code licensing field, which I wasn’t really aware of before.
Bottom line: legal advice was not to use R!
Was it a single lawyer? No. The company was willing to “play along” with me, and we had a consultation with 4 different software lawyers, one after the other. What is the issue? R is licensed as GPL 2, and most R packages are also GPL (whether 2 or 3).
GPL is not a permissive license. It is categorized as “strongly protective”.
In layman terms, if you build your work on a GPL program it may force you to license your product with a GPL license, too. In other words – it restrains you from keeping your code proprietary.
Now you say – “This must be wrong”, and “You just don’t understand the license and its meaning”, right? You may also mention that Microsoft and other big companies are using R, and provide R services.
Well, maybe. I do believe there are ways to make your code proprietary, legally. But, when your software lawyers advise to “make an effort to avoid using this program” you do not brush them off 🙁
Now, for some details.
As a private company, our code needs to be proprietary. Our core is not services, but the software itself. We need to avoid handing our source code to a customer. The program itself will be installed on a customer’s server. Most of our customers have sensitive data and a SAAS model (or a connection to the internet) is out of the question. Can we use R?
The R Core Team addressed the question “Can I use R for commercial purposes?”. But, as lawyers told us, the way it is addressed does not solve much. Any GPL program can be used for commercial purposes. You can offer your services installing the software, or sell a visualization you’ve prepared with ggplot2. But, it does not answer the question – can I write a program in R, and have it licensed with a non-GPL license (or simply – a commercial license)?
The key question we were asked was is our work a “derivative work” of R. Now, R is an interpreted programming language. You can write your code in notepad and it will run perfectly. Logic says that if you do not modify the original software (R) and you do not copy any of its source code, you did not make a derivative work.
As a matter of fact, when you read the FAQ of the GPL license it almost seems that indeed there is no problem. Here is a paragraph from the Free Software Foundation https://www.gnu.org/licenses/gpl-faq.html#IfInterpreterIsGPL: If a programming language interpreter is released under the GPL, does that mean programs written to be interpreted by it must be under GPL-compatible licenses?(#IfInterpreterIsGPL)When the interpreter just interprets a language, the answer is no. The interpreted program, to the interpreter, is just data; a free software license like the GPL, based on copyright law, cannot limit what data you use the interpreter on. You can run it on any data (interpreted program), any way you like, and there are no requirements about licensing that data to anyone.
Problem solved? Not quite. The next paragraph shuffles the cards:
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. So if these facilities are released under the GPL, the interpreted program that uses them must be released in a GPL-compatible way. The JNI or Java Native Interface is an example of such a binding mechanism; libraries that are accessed in this way are linked dynamically with the Java programs that call them. These libraries are also linked with the interpreter. If the interpreter is linked statically with these libraries, or if it is designed to link dynamically with these specific libraries, then it too needs to be released in a GPL-compatible way.
Another similar and very common case is to provide libraries with the interpreter which are themselves interpreted. For instance, Perl comes with many Perl modules, and a Java implementation comes with many Java classes. These libraries and the programs that call them are always dynamically linked together.
A consequence is that if you choose to use GPLed Perl modules or Java classes in your program, you must release the program in a GPL-compatible way, regardless of the license used in the Perl or Java interpreter that the combined Perl or Java program will run on
This is commonly interpreted as “You can use R, as long as you don’t call any library”.
Now, can you think of using R without, say, the Tidyverse package? Tidyverse is a GPL library. And if you want to create a shiny web app – you still use the Shiny library (also GPL). Assume you will purchase a shiny server pro commercial license, this still does not resolve the shiny library itself being licensed as GPL.
Furthermore, we often use quite a lot of R libraries – and almost all are GPL. Same goes for a shiny app, in which you are likely to use many GPL packages to make your product look and behave as you want it to.
Is it legal to use R after all?
I think it is. The term “library” may be the cause of the confusion.As Perl is mentioned specifically in the GPL FAQ quoted above, Perl addressed the issue of GPL licensed interpreter on proprietary scripts head on (https://dev.perl.org/licenses/ ): “my interpretation of the GNU General Public License is that no Perl script falls under the terms of the GPL unless you explicitly put said script under the terms of the GPL yourself.
Furthermore, any object code linked with perl does not automatically fall under the terms of the GPL, provided such object code only adds definitions of subroutines and variables, and does not otherwise impair the resulting interpreter from executing any standard Perl script”
There may also be a hidden explanation by which most libraries are fine to use. As said above, it is possible the confusion is caused by the use of the term “library” in different ways.
Linking/binding is a technical term for what occurs when compiling software together. This is not what happens with most R packages, as may be understood when reading the following question and answer: Does an Rcpp-dependent package require a GPL license?
The question explains why (due to GPL) one should NOT use the Rcpp R library. Can we infer from it that it IS ok to use most other libraries?
“This is not a legal advice”
As we’ve seen, what is and is not legal to do with R, being GPL, is far from being clear.
Everything that is written on the topic is also marked as “not a legal advice”. While this may not be surprising, one has a hard time convincing a lawyer to be permissive, when the software owners are not clear about it. For example, the FAQ “Can I use R for commercial purposes?” mentioned above begins with “R is released under the GNU General Public License (GPL), version 2. If you have any questions regarding the legality of using R in any particular situation you should bring it up with your legal counsel”. And ends with “None of the discussion in this section constitutes legal advice. The R Core Team does not provide legal advice under any circumstances.”
In between the information is not very decisive, either. So at the end of the day, it is unclear what is the actual legal situation.
Another thing one of the software lawyers told us is that Investors do not like GPL. In other words, even if it turns out that it is legal to use R with its libraries – a venture capital investor may be reluctant. If true, this may cause delays and may also require additional work convincing the potential investor that what you are doing is indeed flawless. Hence, lawyers told us, it is best if you can find an alternative that is not GPL at all.
What makes Python better?
Most of the “R vs. Python” articles are pure junk, IMHO. They express nonsense commonly written in the spirit of “Python is a general-purpose language with a readable syntax. R, however, is built by statisticians and encompasses their specific language.” Far away from the reality as I see it.
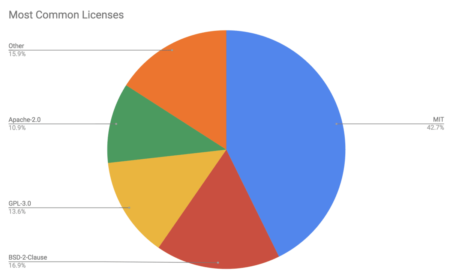
Most Common Licenses for Python Packages https://snyk.io/blog/over-10-of-python-packages-on-pypi-are-distributed-without-any-license/But Python has a permissive license. You can distribute it, you can modify it, and you do not have to worry your code will become open-source, too. This truly is a great advantage.
Is there anything in between a permissive license and a GPL?
Yes there is.
For example, there is the Lesser GPL (LGPL). As described in Wikipedia: “The license allows developers and companies to use and integrate a software component released under the LGPL into their own (even proprietary) software without being required by the terms of a strong copyleft license to release the source code of their own components. However, any developer who modifies an LGPL-covered component is required to make their modified version available under the same LGPL license.” Isn’t this exactly what the R choice of a license was aiming at?
Others use an exception. Javascript, for example, is also GPL. But they added the following exception: “As a special exception to GPL, any HTML file which merely makes function calls to this code, and for that purpose includes it by reference shall be deemed a separate work for copyright law purposes. In addition, the copyright holders of this code give you permission to combine this code with free software libraries that are released under the GNU LGPL. You may copy and distribute such a system following the terms of the GNU GPL for this code and the LGPL for the libraries. If you modify this code, you may extend this exception to your version of the code, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.”
R is not LGPL. R has no written exceptions.
The fact that R and most of its libraries use a GPL license is a problem. At the very least it is not clear if it is really legal to use R to write proprietary code.
Even if it is legal, Python still has an advantage being a permissive license, which means “no questions asked” by potential customers and investors.
It would be good if the R core team, as well as people releasing packages, were clearer about the proper use of the software, as they see it. They could take Perl as an example.
It would be even better if the license would change. At least by adding an exception, reducing it to an LGPL or (best) permissive license.
In some scenarios a data scientist may want to train a model for which there exists an abundance of observations, but only a small fraction of is labeled, making the sample size available to train the model rather small. Although there’s plenty of literature on the subject (e.g. “Active learning”, “Semi-supervised learning” etc) one may be tempted (maybe due to fast approaching deadlines) to train a model with the labelled data and use it to impute the missing labels.
While for some the above suggestion might seem simply incorrect, I have encountered such suggestions on several occasions and had a hard time refuting them. To make sure it wasn’t just the type of places I work at I went and asked around in 2 Israeli (sorry non Hebrew readers) machine learning oriented Facebook groups about their opinion:Machine & Deep learning IsraelandStatistics and probability group. While many were referring me to methods discussed in the literature, almost no one indicated the proposed method was utterly wrong.
I decided to perform a simulation study to get a definitive answer once and for all. If you’re interested in reading what were the results see my analysis on Github.
Proteins are conserved bio molecules present in all organisms. Some proteins are conserved in many similar species, making them homologues of each other, meaning that the sequence is not the same but there is a degree of similarity.
R is a high level programming language with a focus on statistical analysis and machine learning.R Project
R is widely used in bioinformatics and has a huge resources library of packages, most of them developed by the top Universities to help with hard to understand data, like genomic and proteomic data.
Why this matters?
This matters because antibodies will bind to specific proteins, but many proteins have similar structure and sequence. So when performing an assay you want to know what specific protein the antibody binds to.
This is also relevant when choosing an antibody that works in many species, specially when doing research in less used species, like veterinary studies.
Getting Started
You need the sequence of the epitope used to produce the antibody, I need to know where this product will bind in the target protein. If the sequence is very conserved in mammalians for example, this will be homologue in other species; eg. actins, membrane proteins, etc.
Obtaining the data
Data for sequence can be provided by the manufacturer, in some cases it will be in the terms of region of the protein, eg. 162–199aa in C-terminal of RAB22A human.
In these cases I will need to retrieve the protein sequence fromUNIPROTand then cut it according to the information I have on the immunogen, this can be done using a program sequentially, like Rstringipackage or using an excel sheet withMIDfunction.
For this case the sequence is in a column calledsequenceImunogenthat is why I have to make a loop so the protein blast goes through all the sequences in the data frame.
The function
I will use the functionblastSequencesto blast the protein and obtain the homology of this specific sequence to other species. The parameters of the function can be found in theliterature. I usedprogram = “blastp”so I perform aProtein Blast, I use a hitListSize of 50 and a timeout of 200 seconds, this is from previous experience, as I will do this for multiple sequences I prefer the data to beas = data.frame.
x <- blastSequences(x = Sequence, timeout = 200, as = "data.frame", program = "blastp", hitListSize = 50)
Making a loop in R
When creating a loop in R I always put aStartvariable with theSys.time()constant, so I know how long it takes to run this loop.
Start <- Sys.time()
I have use this in a couple of hundred sequences and the result toke a few days, so keep that in mind when you run.
I first create a function that formats my results in terms of percentage of homology and give it the term percentage.
#Create a percent function
percent <- function(x, digits = 1, format = "f", ...) {
paste0(formatC(100 * x, format = format, digits = digits, ...), "%")
}
Cleaning the result data
Once the blastP results come, the 1st step is to clean unwanted information so it is not confusing, I used the base functionssubset,grepl,gsubto get only information with results verified, and remove annoying characters. The objective is to have a nice table result with the best homologues.
#Remove what I do not want
x <- subset(x, grepl("_A", x$Hit_accession) == FALSE)
x <- subset(x, grepl("XP_", x$Hit_accession) == FALSE)
x <- subset(x, grepl("unnamed", x$Hit_def) == FALSE)
#Removing characters that do not
x$Species <- sub(".*\\[(.*)\\].*", "\\1", x$Hit_def, perl=TRUE)
x$Species <- gsub("/].*","", x$Species)
x$Hit_def <- gsub("[[:punct:]].*", "", x$Hit_def)
Retrieving the results above 80% identical
After I get all the results and clean a bit of the results, I want to subset the homologues to above 80%. To do this I count the total characters of the sequence usingncharfunction and divide the total number of hit results by this number of character, ie. for a 100 aa sequence if I hit 80 I get a 80% homology.
I Remove also any duplicated information from our table, and paste all the result into a new column, with all results separated by (line break in HTML), to do this I use the functionpaste, with the optioncollapse = “<br>”
This will create hopefully a table like following:
All the code
All the code can be seen bellow: UseTryCatchfor error management, sometimes the functions times out and you need to rerun, you get a prompt asking to skip or run again, a simple Y is enough.
Start <- Sys.time()
for (i in 1:nrow(dataframe)) {
tryCatch({
percent <- function(x, digits = 1, format = "f", ...) { paste0(formatC(100 * x, format = format, digits = digits, ...), "%")
}
x <- blastSequences(x = dataframe$sequenceImunogen[i], timeout = 200, as = "data.frame", program = "blastp", hitListSize = 50)
#Remove what I do not want
x <- subset(x, grepl("_A", x$Hit_accession) == FALSE)
x <- subset(x, grepl("XP_", x$Hit_accession) == FALSE)
x <- subset(x, grepl("unnamed", x$Hit_def) == FALSE)
#Removing characters that do not
x$Species <- sub(".\\[(.)\\].*", "\\1", x$Hit_def, perl=TRUE)
x$Species <- gsub("/].*","", x$Species)
x$Hit_def <- gsub("[[:punct:]].*", "", x$Hit_def)
x$Hsp_identity <- as.numeric(x$Hsp_identity)
n <- nchar(masterir2$sequenceImunogen[i])
x$percentage <- as.numeric(x$Hsp_identity/n)
x<- x[order(-x$percentage), ]
x<- x[x$percentage > 0.8, ]
x$percentage <- percent(x$percentage)
x$link <- paste0("https://www.ncbi.nlm.nih.gov/protein/",x$Hit_accession)
x$final <- paste(x$Hit_def, x$Species, x$percentage, sep = " - ")
x <- subset(x,!duplicated(x$final))
x$TOTAL <- paste0("<a href='",x$link,"'target='_blank'>",x$final,"</a>")
dataframe$Homology[i] <- paste(unlist(x$TOTAL), collapse ="</br>")
}, error=function(e{cat("ERROR :",conditionMessage(e), "\n")})
}
end <- Sys.time()
print(end - Start)
Conclusion
I can use R and the Bioinformatics packages in Bioconductor to retrieve the homology of known epitopes, this help us provide more valuable information to researchers.
Homology is important in the niche world of antibodies, there is a limited amount of money for validation and a limited amount of species that the antibodies can be tested on. With this simple program a homology can be check in a click of a button, instead of using
What next?
This can be incorporated into a small web application that can provide the homology for a specific selected product with a click off a button, saving time to search and blast on the NCBI website.
I am very new to the world of R and coding, so any comment is appreciated.