Due to the unprecedented technological progress that has been made in years past, the current climate allows us to monitor this pandemic better than any other pandemic in the past. We will argue, however, that R was instrumental in predicting when the 1,000,000th case of COVID-19 will occur, as demonstrated here in our collaboration spread out on three continents:
https://www.sciencedirect.com/science/article/pii/S2590113320300079
Since India is currently in lockdown and the correction process is in India, it has not been concluded as of writing.
The first draft of our paper was prepared on March 18 and can be accessed here: http://www.cs.laurentian.ca/wkoczkodaj/p/?C=M;O=D
Open this link and click twice on “last modified” to see the data (the computing was done a few days earlier).
Our heuristic developed for the prediction could not be implemented so quickly had it not been for our use of R. The function ‘nls‘ is crucial for modelling only the front incline part of the Gaussian function (also known as Gaussian). Should this pandemic not stop, or at the very least slow down, one billion cases could occur by the end of May 2020.
The entire world waits for the inflection point (https://en.wikipedia.org/wiki/Inflection_point) and if you help us, we may be able to reach this point sooner.
A few crucial R commands are:
modE <- nls(dfcov$all ~ a * exp(bdfcov$report), data = dfcov,
start = list(a = 100, b = 0.1))
a <- summary(modE)$parameters[1]
b <- summary(modE)$parameters[2]
summary(modE)
x <- 1:m + dfcov$report[length(dfcov$report)]
modEPr <- a * exp(bx)
Waldemar W. Koczkodaj (email: wkoczkodaj [AT] cs.laurentian.ca)
(for the entire Collaboration)
Category: R
Analyzing Remote Sensing Data using Image Segmentation
This post summarizes material posted as an Additional Topic to accompany the book Spatial Data Analysis in Ecology and Agriculture using R, Second Edition. The full post, together with R code and data, can be found in the Additional Topics section of the book’s website, http://psfaculty.plantsciences.ucdavis.edu/plant/sda2.htm
1. Introduction
The idea is best described with images. Here is a display in mapview of an agricultural region in California’s Central Valley. The boundary of the region is a rectangle developed from UTM coordinates, and it is interesting that the boundary of the region is slightly tilted with respect to the network of roads and field boundaries. There are several possible explanations for this, but it does not affect our presentation, so we will ignore it.
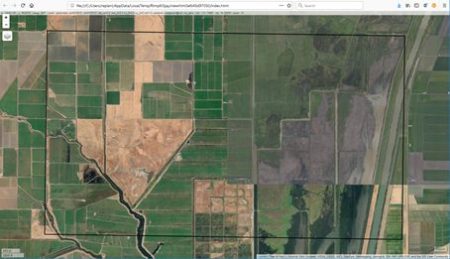 There are clearly several different cover types in the region, including fallow fields, planted fields, natural regions, and open water. Our objective is to develop a land classification of the region based on Landsat data. A common method of doing this is based on the so-called false color image. In a false color image, radiation in the green wavelengths is displayed as blue, radiation in the red wavelengths is displayed as green, and radiation in the infrared wavelengths is displayed as red. Here is a false color image of the region shown in the black rectangle.
There are clearly several different cover types in the region, including fallow fields, planted fields, natural regions, and open water. Our objective is to develop a land classification of the region based on Landsat data. A common method of doing this is based on the so-called false color image. In a false color image, radiation in the green wavelengths is displayed as blue, radiation in the red wavelengths is displayed as green, and radiation in the infrared wavelengths is displayed as red. Here is a false color image of the region shown in the black rectangle.
 Because living vegetation strongly reflects radiation in the infrared region and absorbs it in the red region, the amount of vegetation contained in a pixel can be estimated by using the normalized difference vegetation index, or NDVI, defined as
Because living vegetation strongly reflects radiation in the infrared region and absorbs it in the red region, the amount of vegetation contained in a pixel can be estimated by using the normalized difference vegetation index, or NDVI, defined as
where IR is the pixel intensity of the infrared band and R is the pixel intensity of the red band. Here is the NDVI of the region in the false color image above.
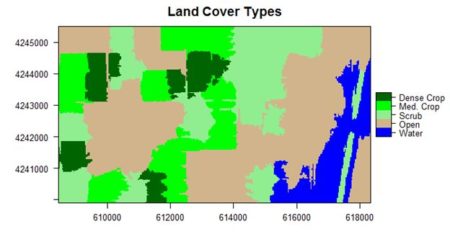
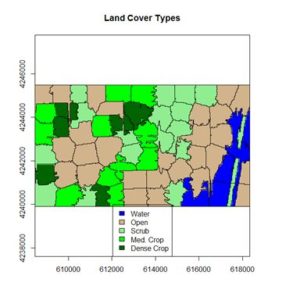
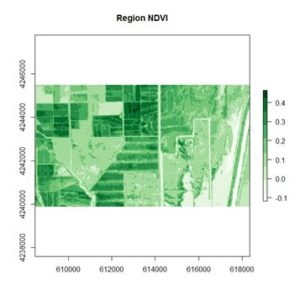 If you compare the images you can see that the areas in black rectangle above that appear green have a high NDVI, the areas that appear brown have a low NDVI, and the open water in the southeast corner of the image actually has a negative NDVI, because water strongly absorbs infrared radiation. Our objective is to generate a classification of the land surface into one of five classes: dense vegetation, sparse vegetation, scrub, open land, and open water. Here is the classification generated using the method I am going to describe.
If you compare the images you can see that the areas in black rectangle above that appear green have a high NDVI, the areas that appear brown have a low NDVI, and the open water in the southeast corner of the image actually has a negative NDVI, because water strongly absorbs infrared radiation. Our objective is to generate a classification of the land surface into one of five classes: dense vegetation, sparse vegetation, scrub, open land, and open water. Here is the classification generated using the method I am going to describe.
 There are a number of image analysis packages available in R. I elected to use the OpenImageR and SuperpixelImageSegmentation packages, both of which were developed by L. Mouselimis (2018, 2019a). One reason for this choice is that the objects created by these packages have a very simple and transparent data structure that makes them ideal for data analysis and, in particular, for integration with the raster package. The packages are both based on the idea of image segmentation using superpixels . According to Stutz et al. (2018), superpixels were introduced by Ren and Malik (2003). Stutz et al. define a superpixel as “a group of pixels that are similar to each other in color and other low level properties.” Here is the false color image above divided into superpixels.
There are a number of image analysis packages available in R. I elected to use the OpenImageR and SuperpixelImageSegmentation packages, both of which were developed by L. Mouselimis (2018, 2019a). One reason for this choice is that the objects created by these packages have a very simple and transparent data structure that makes them ideal for data analysis and, in particular, for integration with the raster package. The packages are both based on the idea of image segmentation using superpixels . According to Stutz et al. (2018), superpixels were introduced by Ren and Malik (2003). Stutz et al. define a superpixel as “a group of pixels that are similar to each other in color and other low level properties.” Here is the false color image above divided into superpixels.
 The superpixels of can then be represented by groups of pixels all having the same pixel value, as shown here. This is what we will call image segmentation.
The superpixels of can then be represented by groups of pixels all having the same pixel value, as shown here. This is what we will call image segmentation.

In the next section we will introduce the concepts of superpixel image segmentation and the application of these packages. In Section 3 we will discuss the use of these concepts in data analysis. The intent of image segmentation as implemented in these and other software packages is to provide support for human visualization. This can cause problems because sometimes a feature that improves the process of visualization detracts from the purpose of data analysis. In Section 4 we will see how the simple structure of the objects created by Mouselimis’s two packages can be used to advantage to make data analysis more powerful and flexible. This post is a shortened version of the Additional Topic that I described at the start of the post.
2. Introducing superpixel image segmentation
The discussion in this section is adapted from the R vignette Image Segmentation Based on Superpixels and Clustering (Mouselimis, 2019b). This vignette describes the R packages OpenImageR and SuperpixelImageSegmentation. In this post I will only discuss the OpenImageR package. It uses simple linear iterative clustering (SLIC, Achanta et al., 2010), and a modified version of this algorithm called SLICO (Yassine et al., 2018), and again for brevity I will only discuss the former. To understand how the SLIC algorithm works, and how it relates to our data analysis objective, we need a bit of review about the concept of color space. Humans perceive color as a mixture of the primary colors red, green, and blue (RGB), and thus a “model” of any given color can in principle be described as a vector in a three-dimensional vector space. The simplest such color space is one in which each component of the vector represents the intensity of one of the three primary colors. Landsat data used in land classification conforms to this model. Each band intensity is represented as an integer value between 0 and 255. The reason is that this covers the complete range of values that can be represented by a sequence of eight binary (0,1) values because 28 – 1 = 255. For this reason it is called the eight-bit RGB color model.
There are other color spaces beyond RGB, each representing a transformation for some particular purpose of the basic RGB color space. A common such color space is the CIELAB color space, defined by the International Commission of Illumination (CIE). You can read about this color space here. In brief, quoting from this Wikipedia article, the CIELAB color space “expresses color as three values: L* for the lightness from black (0) to white (100), a* from green (−) to red (+), and b* from blue (−) to yellow (+). CIELAB was designed so that the same amount of numerical change in these values corresponds to roughly the same amount of visually perceived change.”
Each pixel in an image contains two types of information: its color, represented by a vector in a three dimensional space such as the RGB or CIELAB color space, and its location, represented by a vector in two dimensional space (its x and y coordinates). Thus the totality of information in a pixel is a vector in a five dimensional space. The SLIC algorithm performs a clustering operation similar to K-means clustering on the collection of pixels as represented in this five-dimensional space.
The SLIC algorithm measures total distance between pixels as the sum of two components, dlab, the distance in the CIELAB color space, and dxy, the distance in pixel (x,y) coordinates. Specifically, the distance Ds is computed as
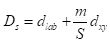 where S is the grid interval of the pixels and m is a compactness parameter that allows one to emphasize or de-emphasize the spatial compactness of the superpixels. The algorithm begins with a set of K cluster centers regularly arranged in the (x,y) grid and performs K-means clustering of these centers until a predefined convergence measure is attained.
where S is the grid interval of the pixels and m is a compactness parameter that allows one to emphasize or de-emphasize the spatial compactness of the superpixels. The algorithm begins with a set of K cluster centers regularly arranged in the (x,y) grid and performs K-means clustering of these centers until a predefined convergence measure is attained.
The following discussion assumes some basic familiarity with the raster package. If you are not familiar with this package, an excellent introduction is given here. After downloading the data files, you can use them to first construct RasterLayer objects and then combine them into a RasterBrick.
> print(nrows <- region.brick@nrows)
[1] 187
> print(ncols <- region.brick@ncols)
[1] 329
Next we plot the region.brick object (shown above) and write it to disk.
> # False color image
> plotRGB(region.brick, r = 4, g = 3, b = 2,
+ stretch = “lin”)
> # Write the image to disk
> jpeg(“FalseColor.jpg”, width = ncols,
+ height = nrows)
> plotRGB(region.brick, r = 4, g = 3, b = 2,
+ stretch = “lin”)
> dev.off()
We will now use SLIC for image segmentation. The code here is adapted directly from the superpixels vignette.
> library(OpenImageR)
> False.Color <- readImage(“FalseColor.jpg”)
> Region.slic = superpixels(input_image =
+ False.Color, method = “slic”, superpixel = 80,
+ compactness = 30, return_slic_data = TRUE,
+ return_labels = TRUE, write_slic = “”,
+ verbose = FALSE)
Warning message:
The input data has values between 0.000000 and 1.000000. The image-data will be multiplied by the value: 255!
> imageShow(Region.slic$slic_data)
We will discuss the warning message in Section 3. The function imageShow() is part of the OpenImageR package.
The OpenImageR function superpixels() creates superpixels, but it does not actually create an image segmentation in the sense that we are using the term is defined in Section 1. This is done by functions in the SuperPixelImageSegmentation package (Mouselimis, 2018), whose discussion is also contained in the superpixels vignette. This package is also described in the Additional Topic. As pointed out there, however, some aspects that make the function well suited for image visualization detract from its usefulness for data analysis, so we won’t discuss it further in this post. Instead, we will move directly to data analysis using the OpenImageR package.
3. Data analysis using superpixels
To use the functions in the OpenImageR package for data analysis, we must first understand the structure of objects created by these packages. The simple, open structure of the objects generated by the function superpixels() makes it an easy matter to use these objects for our purposes. Before we begin, however, we must discuss a preliminary matter: the difference between a Raster* object and a raster object. In Section 2 we used the function raster() to generate the blue, green, red and IR band objects b2, b3, b4, and b5, and then we used the function brick() to generate the object region.brick. Let’s look at the classes of these objects.
> class(b3)
[1] “RasterLayer”
attr(,”package”)
[1] “raster”
> class(full.brick)
[1] “RasterBrick”
attr(,”package”)
[1] “raster”
Objects created by the raster packages are called Raster* objects, with a capital “R”. This may seem like a trivial detail, but it is important to keep in mind because the objects generated by the functions in the OpenImageR and SuperpixelImageSegmentation packages are raster objects that are not Raster* objects (note the deliberate lack of a courier font for the word “raster”).
In Section 2 we used the OpenImageR function readImage() to read the image data into the object False.Color for analysis. Let’s take a look at the structure of this object.
> str(False.Color)
num [1:187, 1:329, 1:3] 0.373 0.416 0.341 0.204 0.165 …
It is a three-dimensional array, which can be thought of as a box, analogous to a rectangular Rubik’s cube. The “height” and “width” of the box are the number of rows and columns respectively in the image and at each value of the height and width the “depth” is a vector whose three components are the red, green, and blue color values of that cell in the image, scaled to [0,1] by dividing the 8-bit RGB values, which range from 0 to 255, by 255. This is the source of the warning message that accompanied the output of the function superpixels(), which said that the values will be multiplied by 255. For our purposes, however, it means that we can easily analyze images consisting of transformations of these values, such as the NDVI. Since the NDVI is a ratio, it doesn’t matter whether the RGB values are normalized or not. For our case the RasterLayer object b5 of the RasterBrick False.Color is the IR band and the object b4 is the R band. Therefore we can compute the NDVI as
> library(RColorBrewer)
> plot(NDVI.region, col = brewer.pal(9, “Greens”),
+ axes = TRUE, main = “Region NDVI”)
This generates the NDVI map shown above. The darkest areas have the highest NDVI. Let’s take a look at the structure of the RasterLayer object NDVI.region.
> str(NDVI.region)
Formal class ‘RasterLayer’ [package “raster”] with 12 slots
* * *
..@ data :Formal class ‘.SingleLayerData’ [package “raster”] with 13 slots
* * *
.. .. ..@ values : num [1:61523] 0.1214 0.1138 0.1043 0.0973 0.0883 …
* * *
..@ ncols : int 329
..@ nrows : int 187
Only the relevant parts are shown, but we see that we can convert the raster data to a matrix that can be imported into our image segmentation machinery as follows. Remember that by default R constructs matrices by columns. The data in Raster* objects such as NDVI.region are stored by rows, so in converting these data to a matrix we must specify byrow = TRUE.
> NDVI.mat <- matrix(NDVI.region@data@values,
+ nrow = NDVI.region@nrows,
+ ncol = NDVI.region@ncols, byrow = TRUE)
The function imageShow() works with data that are either in the eight bit 0 – 255 range or in the [0,1] range (i.e., the range of x between and including 0 and 1). It does not, however, work with NDVI values if these values are negative. Therefore, we will scale NDVI values to [0,1].
> m0 <- min(NDVI.mat)
> m1 <- max(NDVI.mat)
> NDVI.mat1 <- (NDVI.mat – m0) / (m1 – m0)
> imageShow(NDVI.mat)
Here is the resulting image.

The function imageShow() deals with a single layer object by producing a grayscale image. Unlike the green NDVI plot above, in this plot the lower NDVI regions are darker.
We are now ready to carry out the segmentation of the NDVI data. Since the structure of the NDVI image to be analyzed is the same as that of the false color image, we can simply create a copy of this image, fill it with the NDVI data, and run it through the superpixel image segmentation function. If an image has not been created on disk, it is also possible (see the Additional Topic) to create the input object directly from the data.
> NDVI.data <- False.Color
> NDVI.data[,,1] <- NDVI.mat1
> NDVI.data[,,2] <- NDVI.mat1
> NDVI.data[,,3] <- NDVI.mat1 In the next section we will describe how to create an image segmentation of the NDVI data and how to use cluster analysis to create a land classification.
4. Expanding the data analysis capacity of superpixels
Here is an application of the function superpixels() to the NDVI data generated in Section 3.
> NDVI.80 = superpixels(input_image = NDVI.data,
+ method = “slic”, superpixel = 80,
+ compactness = 30, return_slic_data = TRUE,
+ return_labels = TRUE, write_slic = “”,
+ verbose = FALSE)
> imageShow(Region.slic$slic_data)
Here is the result.
 Here the structure of the object NDVI.80 .
Here the structure of the object NDVI.80 .
> str(NDVI.80)
List of 2
$ slic_data: num [1:187, 1:329, 1:3] 95 106 87 52 42 50 63 79 71 57 …
$ labels : num [1:187, 1:329] 0 0 0 0 0 0 0 0 0 0 …
It is a list with two elements, NDVI.80$slic_data, a three dimensional array of pixel color data (not normalized), and NDVI.80$labels, a matrix whose elements correspond to the pixels of the image. The second element’s name hints that it may contain values identifying the superpixel to which each pixel belongs. Let’s see if this is true.
> sort(unique(as.vector(NDVI.80$labels)))
[1] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
[25] 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
[49] 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
There are 72 unique labels. Although the call to superpixels() specified 80 superpixels, the function generated 72. We can see which pixels have the label value 0 by setting the values of all of the other pixels to [255, 255, 255], which will plot as white.
> R0 <- NDVI.80
for (i in 1:nrow(R0$label))
+ for (j in 1:ncol(R0$label))
+ if (R0$label[i,j] != 0)
+ R0$slic_data[i,j,] <- c(255,255,255)
> imageShow(R0$slic_data)
This produces the plot shown here.
 The operation isolates the superpixel in the upper right corner of the image, together with the corresponding portion of the boundary. We can easily use this approach to figure out which value of NDVI.80$label corresponds to which superpixel. Now let’s deal with the boundary. A little exploration of the NDVI.80 object suggests that pixels on the boundary have all three components equal to zero. Let’s isolate and plot all such pixels by coloring all other pixels white.
The operation isolates the superpixel in the upper right corner of the image, together with the corresponding portion of the boundary. We can easily use this approach to figure out which value of NDVI.80$label corresponds to which superpixel. Now let’s deal with the boundary. A little exploration of the NDVI.80 object suggests that pixels on the boundary have all three components equal to zero. Let’s isolate and plot all such pixels by coloring all other pixels white.
> Bdry <- NDVI.80
for (i in 1:nrow(Bdry$label))
+ for (j in 1:ncol(Bdry$label))
+ if (!(Bdry$slic_data[i,j,1] == 0 &
+ Bdry$slic_data[i,j,2] == 0 &
+ Bdry$slic_data[i,j,3] == 0))
+ Bdry$slic_data[i,j,] <- c(255,255,255)
> Bdry.norm <- NormalizeObject(Bdry$slic_data)
> imageShow(Bdry$slic_data)
This shows that we have indeed identified the boundary pixels. Note that the function imageShow() displays these pixels as white with a black edge, rather than pure black. Having done a preliminary analysis, we can organize our segmentation process into two steps. The first step will be to replace each of the superpixels generated by the OpenImageR function superpixels() with one in which each pixel has the same value, corresponding to a measure of central tendency (e.g, the mean, median , or mode) of the original superpixel. The second step will be to use the K-means unsupervised clustering procedure to organize the superpixels from step 1 into a set of clusters and give each cluster a value corresponding to a measure of central tendency of the cluster. I used the code developed to identify the labels and to generate the boundary to construct a function make.segments() to carry out the segmentation. The first argument of make.segments() is the superpixels object, and the second is the functional measurement of central tendency. Although in this case each of the three colors of the object NDVI.80 have the same values, this may not be true for every application, so the function analyzes each color separately. Because the function is rather long, I have not included it in this post. If you want to see it, you can go to the Additional Topic linked to the book’s website.
> NDVI.clus <-
+ kmeans(as.vector(NDVI.means$slic_data[,,1]), 5)
> vege.class <- matrix(NDVI.clus$cluster,
+ nrow = NDVI.region@nrows,
+ ncol = NDVI.region@ncols, byrow = FALSE)
> class.ras <- raster(vege.class, xmn = W,
+ xmx = E, ymn = S, ymx = N, crs =
+ CRS(“+proj=utm +zone=10 +ellps=WGS84”))
Next I used the raster function ratify() to assign descriptive factor levels to the clusters.
> class.ras <- ratify(class.ras)
> rat.class <- levels(class.ras)[[1]]
> rat.class$landcover <- c(“Water”, “Open”,
+ “Scrub”, “Med. Crop”, “Dense Crop”)
> levels(class.ras) <- rat.class
> levelplot(class.ras, margin=FALSE,
+ col.regions= c(“blue”, “tan”,
+ “lightgreen”, “green”, “darkgreen”),
+ main = “Land Cover Types”)
The result is shown in the figure at the start of the post. We can also overlay the original boundaries on top of the image. This is more easily done using plot() rather than levelplot(). The function plot() allows plots to be built up in a series of statements. The function levelplot() does not.
> NDVI.rasmns <- raster(NDVI.means$slic_data[,,1],
+ xmn = W, xmx = E, ymn = S, ymx = N,
+ crs = CRS(“+proj=utm +zone=10 +ellps=WGS84”))
> NDVI.polymns <- rasterToPolygons(NDVI.rasmns,
+ dissolve = TRUE)
> plot(class.ras, col = c(“blue”, “tan”,
+ “lightgreen”, “green”, “darkgreen”),
+ main = “Land Cover Types”, legend = FALSE)
> legend(“bottom”, legend = c(“Water”, “Open”,
+ “Scrub”, “Med. Crop”, “Dense Crop”),
+ fill = c(“blue”, “tan”, “lightgreen”, “green”,
+ “darkgreen”))
> plot(NDVI.polymns, add = TRUE)
The application of image segmentation algorithms to remotely sensed image classification is a rapidly growing field, with numerous studies appearing every year. At this point, however, there is little in the way of theory on which to base an organization of the topic. If you are interested in following up on the subject, I encourage you to explore it on the Internet.
References
Achanta, R., A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Susstrunk (2010). SLIC Superpixels. Ecole Polytechnique Fedrale de Lausanne Technical Report 149300.
Appelhans, T., F. Detsch, C. Reudenbach and S. Woellauer (2017). mapview: Interactive Viewing of Spatial Data in R. R package version 2.2.0. https://CRAN.R-project.org/package=mapview Bivand, R., E. Pebesma, and V. Gómez-Rubio. (2008). Applied Spatial Data Analysis with R. Springer, New York, NY.
Frey, B.J. and D. Dueck (2006). Mixture modeling by affinity propagation. Advances in Neural Information Processing Systems 18:379.
Hijmans, R. J. (2016). raster: Geographic Data Analysis and Modeling. R package version 2.5-8. https://CRAN.R-project.org/package=raster
Mouselimis, L. (2018). SuperpixelImageSegmentation: Superpixel Image Segmentation. R package version 1.0.0. https://CRAN.R-project.org/package=SuperpixelImageSegmentation
Mouselimis, L. (2019a). OpenImageR: An Image Processing Toolkit. R package version 1.1.5. https://CRAN.R-project.org/package=OpenImageR
Mouselimis, L. (2019b) Image Segmentation Based on Superpixel Images and Clustering. https://cran.r-project.org/web/packages/OpenImageR/vignettes/Image_segmentation_superpixels_clustering.html.
Ren, X., and J. Malik (2003) Learning a classification model for segmentation. International Conference on Computer Vision, 2003, 10-17.
Stutz, D., A. Hermans, and B. Leibe (2018). Superpixels: An evaluation of the state-of-the-art. Computer Vision and Image Understanding 166:1-27.
Tufte, E. R. (1983). The Visual Display of Quantitative Information. Graphics Press, Cheshire, Conn.
Yassine, B., P. Taylor, and A. Story (2018). Fully automated lung segmentation from chest radiographs using SLICO superpixels. Analog Integrated Circuits and Signal Processing 95:423-428.
Zhou, B. (2013) Image segmentation using SLIC superpixels and affinity propagation clustering. International Journal of Science and Research. https://pdfs.semanticscholar.org/6533/654973054b742e725fd433265700c07b48a2.pdf
1. Introduction
The idea is best described with images. Here is a display in mapview of an agricultural region in California’s Central Valley. The boundary of the region is a rectangle developed from UTM coordinates, and it is interesting that the boundary of the region is slightly tilted with respect to the network of roads and field boundaries. There are several possible explanations for this, but it does not affect our presentation, so we will ignore it.
There are clearly several different cover types in the region, including fallow fields, planted fields, natural regions, and open water. Our objective is to develop a land classification of the region based on Landsat data. A common method of doing this is based on the so-called false color image. In a false color image, radiation in the green wavelengths is displayed as blue, radiation in the red wavelengths is displayed as green, and radiation in the infrared wavelengths is displayed as red. Here is a false color image of the region shown in the black rectangle.
Because living vegetation strongly reflects radiation in the infrared region and absorbs it in the red region, the amount of vegetation contained in a pixel can be estimated by using the normalized difference vegetation index, or NDVI, defined as
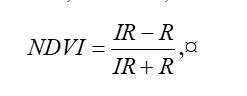 |
If you compare the images you can see that the areas in black rectangle above that appear green have a high NDVI, the areas that appear brown have a low NDVI, and the open water in the southeast corner of the image actually has a negative NDVI, because water strongly absorbs infrared radiation. Our objective is to generate a classification of the land surface into one of five classes: dense vegetation, sparse vegetation, scrub, open land, and open water. Here is the classification generated using the method I am going to describe.
There are a number of image analysis packages available in R. I elected to use the OpenImageR and SuperpixelImageSegmentation packages, both of which were developed by L. Mouselimis (2018, 2019a). One reason for this choice is that the objects created by these packages have a very simple and transparent data structure that makes them ideal for data analysis and, in particular, for integration with the raster package. The packages are both based on the idea of image segmentation using superpixels . According to Stutz et al. (2018), superpixels were introduced by Ren and Malik (2003). Stutz et al. define a superpixel as “a group of pixels that are similar to each other in color and other low level properties.” Here is the false color image above divided into superpixels.In the next section we will introduce the concepts of superpixel image segmentation and the application of these packages. In Section 3 we will discuss the use of these concepts in data analysis. The intent of image segmentation as implemented in these and other software packages is to provide support for human visualization. This can cause problems because sometimes a feature that improves the process of visualization detracts from the purpose of data analysis. In Section 4 we will see how the simple structure of the objects created by Mouselimis’s two packages can be used to advantage to make data analysis more powerful and flexible. This post is a shortened version of the Additional Topic that I described at the start of the post.
2. Introducing superpixel image segmentation
The discussion in this section is adapted from the R vignette Image Segmentation Based on Superpixels and Clustering (Mouselimis, 2019b). This vignette describes the R packages OpenImageR and SuperpixelImageSegmentation. In this post I will only discuss the OpenImageR package. It uses simple linear iterative clustering (SLIC, Achanta et al., 2010), and a modified version of this algorithm called SLICO (Yassine et al., 2018), and again for brevity I will only discuss the former. To understand how the SLIC algorithm works, and how it relates to our data analysis objective, we need a bit of review about the concept of color space. Humans perceive color as a mixture of the primary colors red, green, and blue (RGB), and thus a “model” of any given color can in principle be described as a vector in a three-dimensional vector space. The simplest such color space is one in which each component of the vector represents the intensity of one of the three primary colors. Landsat data used in land classification conforms to this model. Each band intensity is represented as an integer value between 0 and 255. The reason is that this covers the complete range of values that can be represented by a sequence of eight binary (0,1) values because 28 – 1 = 255. For this reason it is called the eight-bit RGB color model.
There are other color spaces beyond RGB, each representing a transformation for some particular purpose of the basic RGB color space. A common such color space is the CIELAB color space, defined by the International Commission of Illumination (CIE). You can read about this color space here. In brief, quoting from this Wikipedia article, the CIELAB color space “expresses color as three values: L* for the lightness from black (0) to white (100), a* from green (−) to red (+), and b* from blue (−) to yellow (+). CIELAB was designed so that the same amount of numerical change in these values corresponds to roughly the same amount of visually perceived change.”
Each pixel in an image contains two types of information: its color, represented by a vector in a three dimensional space such as the RGB or CIELAB color space, and its location, represented by a vector in two dimensional space (its x and y coordinates). Thus the totality of information in a pixel is a vector in a five dimensional space. The SLIC algorithm performs a clustering operation similar to K-means clustering on the collection of pixels as represented in this five-dimensional space.
The SLIC algorithm measures total distance between pixels as the sum of two components, dlab, the distance in the CIELAB color space, and dxy, the distance in pixel (x,y) coordinates. Specifically, the distance Ds is computed as
where S is the grid interval of the pixels and m is a compactness parameter that allows one to emphasize or de-emphasize the spatial compactness of the superpixels. The algorithm begins with a set of K cluster centers regularly arranged in the (x,y) grid and performs K-means clustering of these centers until a predefined convergence measure is attained.The following discussion assumes some basic familiarity with the raster package. If you are not familiar with this package, an excellent introduction is given here. After downloading the data files, you can use them to first construct RasterLayer objects and then combine them into a RasterBrick.
library(raster)
> b2 <- raster(“region_blue.grd”)
> b3 <- raster(“region_green.grd”)
> b4 <- raster(“region_red.grd”)
> b5 <- raster(“region_IR.grd”)
> region.brick <- brick(b2, b3, b4, b5)
> print(nrows <- region.brick@nrows)
[1] 187
> print(ncols <- region.brick@ncols)
[1] 329
Next we plot the region.brick object (shown above) and write it to disk.
> # False color image
> plotRGB(region.brick, r = 4, g = 3, b = 2,
+ stretch = “lin”)
> # Write the image to disk
> jpeg(“FalseColor.jpg”, width = ncols,
+ height = nrows)
> plotRGB(region.brick, r = 4, g = 3, b = 2,
+ stretch = “lin”)
> dev.off()
We will now use SLIC for image segmentation. The code here is adapted directly from the superpixels vignette.
> library(OpenImageR)
> False.Color <- readImage(“FalseColor.jpg”)
> Region.slic = superpixels(input_image =
+ False.Color, method = “slic”, superpixel = 80,
+ compactness = 30, return_slic_data = TRUE,
+ return_labels = TRUE, write_slic = “”,
+ verbose = FALSE)
Warning message:
The input data has values between 0.000000 and 1.000000. The image-data will be multiplied by the value: 255!
> imageShow(Region.slic$slic_data)
We will discuss the warning message in Section 3. The function imageShow() is part of the OpenImageR package.
The OpenImageR function superpixels() creates superpixels, but it does not actually create an image segmentation in the sense that we are using the term is defined in Section 1. This is done by functions in the SuperPixelImageSegmentation package (Mouselimis, 2018), whose discussion is also contained in the superpixels vignette. This package is also described in the Additional Topic. As pointed out there, however, some aspects that make the function well suited for image visualization detract from its usefulness for data analysis, so we won’t discuss it further in this post. Instead, we will move directly to data analysis using the OpenImageR package.
3. Data analysis using superpixels
To use the functions in the OpenImageR package for data analysis, we must first understand the structure of objects created by these packages. The simple, open structure of the objects generated by the function superpixels() makes it an easy matter to use these objects for our purposes. Before we begin, however, we must discuss a preliminary matter: the difference between a Raster* object and a raster object. In Section 2 we used the function raster() to generate the blue, green, red and IR band objects b2, b3, b4, and b5, and then we used the function brick() to generate the object region.brick. Let’s look at the classes of these objects.
> class(b3)
[1] “RasterLayer”
attr(,”package”)
[1] “raster”
> class(full.brick)
[1] “RasterBrick”
attr(,”package”)
[1] “raster”
Objects created by the raster packages are called Raster* objects, with a capital “R”. This may seem like a trivial detail, but it is important to keep in mind because the objects generated by the functions in the OpenImageR and SuperpixelImageSegmentation packages are raster objects that are not Raster* objects (note the deliberate lack of a courier font for the word “raster”).
In Section 2 we used the OpenImageR function readImage() to read the image data into the object False.Color for analysis. Let’s take a look at the structure of this object.
> str(False.Color)
num [1:187, 1:329, 1:3] 0.373 0.416 0.341 0.204 0.165 …
It is a three-dimensional array, which can be thought of as a box, analogous to a rectangular Rubik’s cube. The “height” and “width” of the box are the number of rows and columns respectively in the image and at each value of the height and width the “depth” is a vector whose three components are the red, green, and blue color values of that cell in the image, scaled to [0,1] by dividing the 8-bit RGB values, which range from 0 to 255, by 255. This is the source of the warning message that accompanied the output of the function superpixels(), which said that the values will be multiplied by 255. For our purposes, however, it means that we can easily analyze images consisting of transformations of these values, such as the NDVI. Since the NDVI is a ratio, it doesn’t matter whether the RGB values are normalized or not. For our case the RasterLayer object b5 of the RasterBrick False.Color is the IR band and the object b4 is the R band. Therefore we can compute the NDVI as
> NDVI.region <- (b5 – b4) / (b5 + b4)
Since NDVI is a ratio scale quantity, the theoretically best practice is to plot it using a monochromatic representation in which the brightness of the color (i.e., the color value) represents the value (Tufte, 1983). We can accomplish this using the RColorBrewer function brewer.pal().> library(RColorBrewer)
> plot(NDVI.region, col = brewer.pal(9, “Greens”),
+ axes = TRUE, main = “Region NDVI”)
This generates the NDVI map shown above. The darkest areas have the highest NDVI. Let’s take a look at the structure of the RasterLayer object NDVI.region.
> str(NDVI.region)
Formal class ‘RasterLayer’ [package “raster”] with 12 slots
* * *
..@ data :Formal class ‘.SingleLayerData’ [package “raster”] with 13 slots
* * *
.. .. ..@ values : num [1:61523] 0.1214 0.1138 0.1043 0.0973 0.0883 …
* * *
..@ ncols : int 329
..@ nrows : int 187
Only the relevant parts are shown, but we see that we can convert the raster data to a matrix that can be imported into our image segmentation machinery as follows. Remember that by default R constructs matrices by columns. The data in Raster* objects such as NDVI.region are stored by rows, so in converting these data to a matrix we must specify byrow = TRUE.
> NDVI.mat <- matrix(NDVI.region@data@values,
+ nrow = NDVI.region@nrows,
+ ncol = NDVI.region@ncols, byrow = TRUE)
The function imageShow() works with data that are either in the eight bit 0 – 255 range or in the [0,1] range (i.e., the range of x between and including 0 and 1). It does not, however, work with NDVI values if these values are negative. Therefore, we will scale NDVI values to [0,1].
> m0 <- min(NDVI.mat)
> m1 <- max(NDVI.mat)
> NDVI.mat1 <- (NDVI.mat – m0) / (m1 – m0)
> imageShow(NDVI.mat)
Here is the resulting image.
The function imageShow() deals with a single layer object by producing a grayscale image. Unlike the green NDVI plot above, in this plot the lower NDVI regions are darker.
We are now ready to carry out the segmentation of the NDVI data. Since the structure of the NDVI image to be analyzed is the same as that of the false color image, we can simply create a copy of this image, fill it with the NDVI data, and run it through the superpixel image segmentation function. If an image has not been created on disk, it is also possible (see the Additional Topic) to create the input object directly from the data.
> NDVI.data <- False.Color
> NDVI.data[,,1] <- NDVI.mat1
> NDVI.data[,,2] <- NDVI.mat1
> NDVI.data[,,3] <- NDVI.mat1 In the next section we will describe how to create an image segmentation of the NDVI data and how to use cluster analysis to create a land classification.
4. Expanding the data analysis capacity of superpixels
Here is an application of the function superpixels() to the NDVI data generated in Section 3.
> NDVI.80 = superpixels(input_image = NDVI.data,
+ method = “slic”, superpixel = 80,
+ compactness = 30, return_slic_data = TRUE,
+ return_labels = TRUE, write_slic = “”,
+ verbose = FALSE)
> imageShow(Region.slic$slic_data)
Here is the result.
Here the structure of the object NDVI.80 .> str(NDVI.80)
List of 2
$ slic_data: num [1:187, 1:329, 1:3] 95 106 87 52 42 50 63 79 71 57 …
$ labels : num [1:187, 1:329] 0 0 0 0 0 0 0 0 0 0 …
It is a list with two elements, NDVI.80$slic_data, a three dimensional array of pixel color data (not normalized), and NDVI.80$labels, a matrix whose elements correspond to the pixels of the image. The second element’s name hints that it may contain values identifying the superpixel to which each pixel belongs. Let’s see if this is true.
> sort(unique(as.vector(NDVI.80$labels)))
[1] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
[25] 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
[49] 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
There are 72 unique labels. Although the call to superpixels() specified 80 superpixels, the function generated 72. We can see which pixels have the label value 0 by setting the values of all of the other pixels to [255, 255, 255], which will plot as white.
> R0 <- NDVI.80
for (i in 1:nrow(R0$label))
+ for (j in 1:ncol(R0$label))
+ if (R0$label[i,j] != 0)
+ R0$slic_data[i,j,] <- c(255,255,255)
> imageShow(R0$slic_data)
This produces the plot shown here.
The operation isolates the superpixel in the upper right corner of the image, together with the corresponding portion of the boundary. We can easily use this approach to figure out which value of NDVI.80$label corresponds to which superpixel. Now let’s deal with the boundary. A little exploration of the NDVI.80 object suggests that pixels on the boundary have all three components equal to zero. Let’s isolate and plot all such pixels by coloring all other pixels white.> Bdry <- NDVI.80
for (i in 1:nrow(Bdry$label))
+ for (j in 1:ncol(Bdry$label))
+ if (!(Bdry$slic_data[i,j,1] == 0 &
+ Bdry$slic_data[i,j,2] == 0 &
+ Bdry$slic_data[i,j,3] == 0))
+ Bdry$slic_data[i,j,] <- c(255,255,255)
> Bdry.norm <- NormalizeObject(Bdry$slic_data)
> imageShow(Bdry$slic_data)
This shows that we have indeed identified the boundary pixels. Note that the function imageShow() displays these pixels as white with a black edge, rather than pure black. Having done a preliminary analysis, we can organize our segmentation process into two steps. The first step will be to replace each of the superpixels generated by the OpenImageR function superpixels() with one in which each pixel has the same value, corresponding to a measure of central tendency (e.g, the mean, median , or mode) of the original superpixel. The second step will be to use the K-means unsupervised clustering procedure to organize the superpixels from step 1 into a set of clusters and give each cluster a value corresponding to a measure of central tendency of the cluster. I used the code developed to identify the labels and to generate the boundary to construct a function make.segments() to carry out the segmentation. The first argument of make.segments() is the superpixels object, and the second is the functional measurement of central tendency. Although in this case each of the three colors of the object NDVI.80 have the same values, this may not be true for every application, so the function analyzes each color separately. Because the function is rather long, I have not included it in this post. If you want to see it, you can go to the Additional Topic linked to the book’s website.
Here is the application of the function to the object NDVI.80 with the second argument set to mean.
> NDVI.means <- make.segments(NDVI.80, mean)
> imageShow(NDVI.means$slic_data)
Here is the result.
The next step is to develop clusters that represent identifiable land cover types. In a real project the procedure would be to collect a set of ground truth data from the site, but that option is not available to us. Instead we will work with the true color rendition of the Landsat scene, shown here.
 The land cover is subdivided using K-means into five types: dense crop, medium crop, scrub, open, and water.
The land cover is subdivided using K-means into five types: dense crop, medium crop, scrub, open, and water.
> NDVI.clus <-
+ kmeans(as.vector(NDVI.means$slic_data[,,1]), 5)
> vege.class <- matrix(NDVI.clus$cluster,
+ nrow = NDVI.region@nrows,
+ ncol = NDVI.region@ncols, byrow = FALSE)
> class.ras <- raster(vege.class, xmn = W,
+ xmx = E, ymn = S, ymx = N, crs =
+ CRS(“+proj=utm +zone=10 +ellps=WGS84”))
Next I used the raster function ratify() to assign descriptive factor levels to the clusters.
> class.ras <- ratify(class.ras)
> rat.class <- levels(class.ras)[[1]]
> rat.class$landcover <- c(“Water”, “Open”,
+ “Scrub”, “Med. Crop”, “Dense Crop”)
> levels(class.ras) <- rat.class
> levelplot(class.ras, margin=FALSE,
+ col.regions= c(“blue”, “tan”,
+ “lightgreen”, “green”, “darkgreen”),
+ main = “Land Cover Types”)
The result is shown in the figure at the start of the post. We can also overlay the original boundaries on top of the image. This is more easily done using plot() rather than levelplot(). The function plot() allows plots to be built up in a series of statements. The function levelplot() does not.
> NDVI.rasmns <- raster(NDVI.means$slic_data[,,1],
+ xmn = W, xmx = E, ymn = S, ymx = N,
+ crs = CRS(“+proj=utm +zone=10 +ellps=WGS84”))
> NDVI.polymns <- rasterToPolygons(NDVI.rasmns,
+ dissolve = TRUE)
> plot(class.ras, col = c(“blue”, “tan”,
+ “lightgreen”, “green”, “darkgreen”),
+ main = “Land Cover Types”, legend = FALSE)
> legend(“bottom”, legend = c(“Water”, “Open”,
+ “Scrub”, “Med. Crop”, “Dense Crop”),
+ fill = c(“blue”, “tan”, “lightgreen”, “green”,
+ “darkgreen”))
> plot(NDVI.polymns, add = TRUE)
The application of image segmentation algorithms to remotely sensed image classification is a rapidly growing field, with numerous studies appearing every year. At this point, however, there is little in the way of theory on which to base an organization of the topic. If you are interested in following up on the subject, I encourage you to explore it on the Internet.
References
Achanta, R., A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Susstrunk (2010). SLIC Superpixels. Ecole Polytechnique Fedrale de Lausanne Technical Report 149300.
Appelhans, T., F. Detsch, C. Reudenbach and S. Woellauer (2017). mapview: Interactive Viewing of Spatial Data in R. R package version 2.2.0. https://CRAN.R-project.org/package=mapview Bivand, R., E. Pebesma, and V. Gómez-Rubio. (2008). Applied Spatial Data Analysis with R. Springer, New York, NY.
Frey, B.J. and D. Dueck (2006). Mixture modeling by affinity propagation. Advances in Neural Information Processing Systems 18:379.
Hijmans, R. J. (2016). raster: Geographic Data Analysis and Modeling. R package version 2.5-8. https://CRAN.R-project.org/package=raster
Mouselimis, L. (2018). SuperpixelImageSegmentation: Superpixel Image Segmentation. R package version 1.0.0. https://CRAN.R-project.org/package=SuperpixelImageSegmentation
Mouselimis, L. (2019a). OpenImageR: An Image Processing Toolkit. R package version 1.1.5. https://CRAN.R-project.org/package=OpenImageR
Mouselimis, L. (2019b) Image Segmentation Based on Superpixel Images and Clustering. https://cran.r-project.org/web/packages/OpenImageR/vignettes/Image_segmentation_superpixels_clustering.html.
Ren, X., and J. Malik (2003) Learning a classification model for segmentation. International Conference on Computer Vision, 2003, 10-17.
Stutz, D., A. Hermans, and B. Leibe (2018). Superpixels: An evaluation of the state-of-the-art. Computer Vision and Image Understanding 166:1-27.
Tufte, E. R. (1983). The Visual Display of Quantitative Information. Graphics Press, Cheshire, Conn.
Yassine, B., P. Taylor, and A. Story (2018). Fully automated lung segmentation from chest radiographs using SLICO superpixels. Analog Integrated Circuits and Signal Processing 95:423-428.
Zhou, B. (2013) Image segmentation using SLIC superpixels and affinity propagation clustering. International Journal of Science and Research. https://pdfs.semanticscholar.org/6533/654973054b742e725fd433265700c07b48a2.pdf
nnlib2Rcpp: a(nother) R package for Neural Networks
For anyone interested, nnlib2Rcpp is an R package containing a number of Neural Network implementations and is available on GitHub. It can be installed as follows (the usual way for packages on GitHub):
The package currently includes the following NN implementations:
library(devtools)
install_github("VNNikolaidis/nnlib2Rcpp")
The NNs are implemented in C++ (using nnlib2 C++ class library) and are interfaced with R via Rcpp package (which is also required).The package currently includes the following NN implementations:
- A Back-Propagation (BP) multi-layer NN (supervised) for input-output mappings.
- An Autoencoder NN (unsupervised) for dimensionality reduction (a bit like PCA) or dimensionality expansion.
- A Learning Vector Quantization NN (LVQ, supervised) for classification.
- A Self-Organizing Map NN (unsupervised, simplified 1-D variation of SOM) for clustering (a bit like k-means).
- A simple Matrix-Associative-Memory NN (MAM, supervised) for storing input-output vector pairs.
Generate names using posterior probabilities
If you are building synthetic data and need to generate people names, this article will be a helpful guide. This article is part of a series of articles regarding the R package conjurer. You can find the first part of this series here.
Install conjurer package by using the following code.
The package conjurer provides 2 two options to generate names.
The function that helps in generating names is buildNames. Let us understand the inputs of the function. This function takes the form as given below.
dframe is a dataframe. This dataframe must be a single column dataframe where each row contains a name. These names must only contain english alphabets(upper or lower case) from A to Z but no special characters such as “;” or non ASCII characters. If you do not pass this argument to the function, the function uses the default prior probabilities to generate the names.
numOfNames is a numeric. This specifies the number of names to be generated. It should be a non-zero natural number.
minLength is a numeric. This specifies the minimum number of alphabets in the name. It must be a non-zero natural number.
maxLength is a numeric. This specifies the maximum number of alphabets in the name. It must be a non-zero natural number.
Let us run this function with an example to see how it works. Let us use the default matrix of prior probabilities for this example. The output would be a list of names as given below.
Following is the consolidated code for your convenience.
In this article, we have learnt how to use the R package conjurer and generate names. Since the algorithm relies on prior probabilities, the names that are output may not look exactly like real human names but will phonetically sound like human names. So, go ahead and give it a try. If you like to understand the underlying code that generates these names, you can explore the GitHub repository here. If you are interested in what’s coming next in this package, you can find it in the issues section here
Steps to generate people names
1. Installation
Install conjurer package by using the following code.
install.packages("conjurer")
2. Training data Vs default data
The package conjurer provides 2 two options to generate names.
-
- The first option is to provide a custom training data.
- The second option is to use the default training data provided by the package.
The function that helps in generating names is buildNames. Let us understand the inputs of the function. This function takes the form as given below.
buildNames(dframe, numOfNames, minLength, maxLength)In this function,
dframe is a dataframe. This dataframe must be a single column dataframe where each row contains a name. These names must only contain english alphabets(upper or lower case) from A to Z but no special characters such as “;” or non ASCII characters. If you do not pass this argument to the function, the function uses the default prior probabilities to generate the names.
numOfNames is a numeric. This specifies the number of names to be generated. It should be a non-zero natural number.
minLength is a numeric. This specifies the minimum number of alphabets in the name. It must be a non-zero natural number.
maxLength is a numeric. This specifies the maximum number of alphabets in the name. It must be a non-zero natural number.
3. Example
Let us run this function with an example to see how it works. Let us use the default matrix of prior probabilities for this example. The output would be a list of names as given below.
library(conjurer) peopleNames <- buildNames(numOfNames = 3, minLength = 5, maxLength = 7) print(peopleNames) [1] "ellie" "bellann" "netar"Please note that since this is a random generator, you may get other names than displayed in the above example.
4. Consolidated code
Following is the consolidated code for your convenience.
#install latest version
install.packages("conjurer")
#invoke library
library(conjurer)
#generate names
peopleNames <- buildNames(numOfNames = 3, minLength = 5, maxLength = 7)
#inspect the names generated
print(peopleNames)
5. Concluding remarks
In this article, we have learnt how to use the R package conjurer and generate names. Since the algorithm relies on prior probabilities, the names that are output may not look exactly like real human names but will phonetically sound like human names. So, go ahead and give it a try. If you like to understand the underlying code that generates these names, you can explore the GitHub repository here. If you are interested in what’s coming next in this package, you can find it in the issues section here
Covid-19 interactive map (using R with shiny, leaflet and dplyr)
The departement of Public Health of the Strasbourg University Hospital (GMRC, Prof. Meyer) and the Laboratory of Biostatistics and Medical Informatics of the Strasbourg Medicine Faculty (Prof. Sauleau), to the extent of their means and expertise, are contributing to the fight against Covid-19 infection. Doctor Fabacher has produced an interactive map for global monitoring of the infection, accessible at :
https://thibautfabacher.shinyapps.io/covid-19/
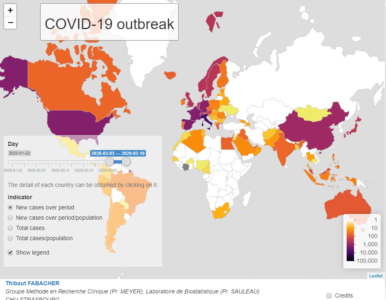
This map, which complements the Johns Hopkins University tool (Coronavirus COVID-19 Global Cases by Johns Hopkins CSSE), focuses on the evolution of the number of cases per country and for a given period, but in terms of incidence and prevalence. It is updated daily.
The period of interest can be defined by the user and it is possible to choose :
This map is made using R with shiny, leaflet and dplyr packages.
Code available here : https://github.com/DrFabach/Corona/blob/master/shiny.r
Reference
Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis; published online Feb 19. https://doi.org/10.1016/S1473-3099(20)30120-1.
https://thibautfabacher.shinyapps.io/covid-19/
This map, which complements the Johns Hopkins University tool (Coronavirus COVID-19 Global Cases by Johns Hopkins CSSE), focuses on the evolution of the number of cases per country and for a given period, but in terms of incidence and prevalence. It is updated daily.
The period of interest can be defined by the user and it is possible to choose :
- The count of new cases over a period of time or the same count in relation to the population of the country (incidence).
- The total case count over a period of time or the same count reported to the population (prevalence).
This map is made using R with shiny, leaflet and dplyr packages.
Code available here : https://github.com/DrFabach/Corona/blob/master/shiny.r
Reference
Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis; published online Feb 19. https://doi.org/10.1016/S1473-3099(20)30120-1.
Trend Forecasting Models and Seasonality with Time Series
Gasoline prices always is an issue in Turkey; because Turkish people love to drive where they would go but they complain about the prices anyway. I wanted to start digging for the last seven years’ prices and how they went. I have used unleaded gasoline 95 octane prices from Petrol Ofisi which is a fuel distribution company in Turkey. I arranged the prices monthly between 2013 and 2020 as the Turkish currency, Lira (TL). The dataset is here
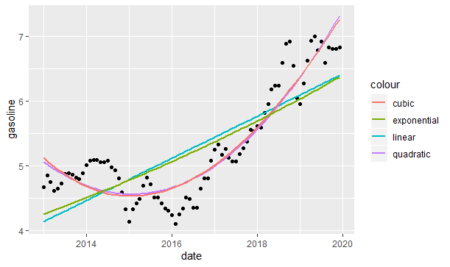
As we see above, the cubic and quadratic models almost overlap each other and they seem to be fit better to the data. However, we will analyze each model in detail.
The Forecasting Trend Models
The linear trend; $latex y_{t}&s=1$, the value of the series at given time, $latex t&s=1$, is described as:
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t&s=1+\epsilon_{t}$
$latex \beta_{0}&s=1$ and $latex \beta_{1}&s=1$ are the coefficients.
Adjusted $latex R^2&s=1=1-(1-R^2&s=1)(\frac {n-1} {n-k-1})$
$latex n$: sample size
$latex k$: number of variables
$latex R^2&s=1$: coefficient of determination which is the square of correlation of observation values with predicted values: $latex r^2_{y \hat {y}}$
$latex \ln(y_{t}&s=1)=\beta_{0}+\beta_{1}t&s=1+\epsilon_{t}$. $latex \ln(y_{t}&s=1)$ is a natural logarithm of the response variable.
To make predictions on the fitted model, we use exponential function as $latex \hat{y_{t}}&s=1=exp(b_{0}+b_{1}t+s_{e}^2/2)$ because the dependent variable was transformed by a natural logarithmic function. In order for $latex \hat{y_{t}}&s=1$ not to be under the expected value of $latex y{t}&s=1$, we add half of the residual standard error's square. In order to find $latex s_{e}&s=2$, we execute the summary function as below. In addition, we can see the level of significance of the coefficients and the model. As we see below, because the p-value of the coefficients and the model are less than 0.05, they are significant at the %5 level of significance.
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t+\beta_{2}t^2+\epsilon$
If there are two change of direction we use the cubic trend models:
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t+\beta_{2}t^2+\beta_{3}t^3+\epsilon$
Then again, we execute the same process as we did in the linear model.
The seasonality component represents the repeats in a specific period of time. Time series with weekly monthly or quarterly observations tend to show seasonal variations that repeat every year. For example, the sale of retail goods increases every year in the Christmas period or the holiday tours increase in the summer. In order to detect seasonality, we use decomposition analysis.
Decomposition analysis: $latex T, S, I&s=1$, are trend, seasonality and random components of the series respectively. When seasonal variation increases as the time series increase, we'd use the multiplicative model.
$latex y_{t}&s=1=T_{t} \times S_{t} \times I_{t}$
If the variation looks constant, we should use additive model.
$latex y_{t}&s=1=T_{t} + S_{t} + I_{t}$
To find which model is fit, we have to look at it on the graph.
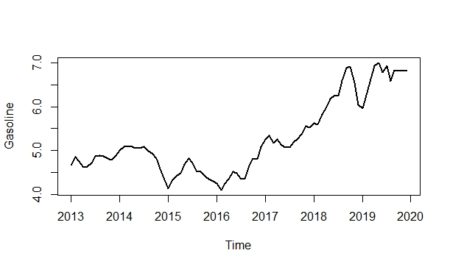
As we can see from the plot above, it seems that the multiplicative model would be more fit for the data; especially if we look at between 2016-2019. When we analyze the graph, we see some conjuncture variations caused by the expansion or contraction of the economy. Unlike seasonality, conjuncture fluctuations can be several months or years in length.
Additionally, the magnitude of conjuncture fluctuation can change in time because the fluctuations differ in magnitude and length so they are hard to reflect with historical data; because of that, we neglected the conjuncture component of the series.
Extracting the seasonality
Moving averages (ma) usually be used to separate the effect of a trend from seasonality.
$latex m\,\,term\,\,moving\,\,averages&s=1=\frac {Average\,\,of\,\,the\,\,last\,\,m\,\,observations} {m}$
We use the cumulative moving average (CMA), which is the average of two consecutive averages, to show the even-order moving average. For example; first two ma terms are $latex \bar{y}_{6.5}&s=1$ and $latex \bar{y}_{7.5}&s=1$ but there are no such terms in the original series; therefore we average the two terms to find CMA term matched up in the series:
$latex \bar y_7&s=3=$$latex \frac {\bar y_{6,5}&s=3+\bar y_{7,5}} {2}$
The default value of the 'centre' argument of the ma function remains TRUE to get CMA value.
Since $latex y_{t}&s=1=T_{t} \times S_{t} \times I_{t}$ and $latex \bar y_{t}&s=1=T_{t}$, the detrend variable is found by: $latex \frac {\bar y_{t}} {y_{t}}&s=1=S_{t} \times I_{t}$; it is also called ratio-to moving averages method.
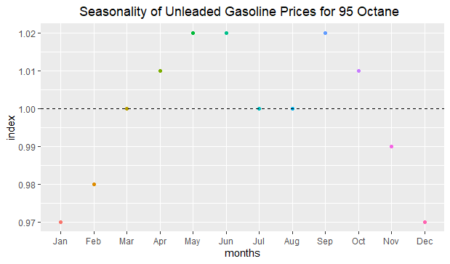
As we can see above, there is approximately a three-percent seasonal decrease in January and December; on the other hand, there is a two-percent seasonal increase in May and June. Seasonality is not seen in March, July, and August; because their index values are approximately equal to 1.
Decomposing the time series graphically
We will first show the trend line on the time series.
And will isolate the trend line from the plot:
Let's see the seasonality line:
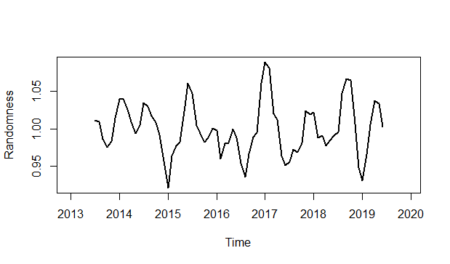
 And finally, we will show the randomness line; in order to do that:
And finally, we will show the randomness line; in order to do that:
$latex I_{t}&s=1=\frac {y_{t}} {S_{t}\times T_{t}}$
References
Sanjiv Jaggia, Alison Kelly (2013). Business Intelligence: Communicating with Numbers.
head(gasoline_df) # date gasoline #1 2013-01-01 4.67 #2 2013-02-01 4.85 #3 2013-03-01 4.75 #4 2013-04-01 4.61 #5 2013-05-01 4.64 #6 2013-06-01 4.72First of all, I wanted to see how gasoline prices went during the period and analyze the fitted trend lines.
#Trend lines library(tidyverse) ggplot(gasoline_df, aes(x = date, y = gasoline)) + geom_point() + stat_smooth(method = 'lm', aes(colour = 'linear'), se = FALSE) + stat_smooth(method = 'lm', formula = y ~ poly(x,2), aes(colour = 'quadratic'), se= FALSE) + stat_smooth(method = 'lm', formula = y ~ poly(x,3), aes(colour = 'cubic'), se = FALSE)+ stat_smooth(data=exp.model.df, method = 'loess',aes(x,y,colour = 'exponential'), se = FALSE)Because the response variable is measured by logarithmic in the exponential model, we have to get the exponent of it and create a different data frame for the exponential trend line.
#exponential trend model
exp.model <- lm(log(gasoline)~date,data = gasoline_df)
exp.model.df <- data.frame(x=gasoline_df$date,
y=exp(fitted(exp.model)))
As we see above, the cubic and quadratic models almost overlap each other and they seem to be fit better to the data. However, we will analyze each model in detail.
The Forecasting Trend Models
The linear trend; $latex y_{t}&s=1$, the value of the series at given time, $latex t&s=1$, is described as:
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t&s=1+\epsilon_{t}$
$latex \beta_{0}&s=1$ and $latex \beta_{1}&s=1$ are the coefficients.
model_linear <- lm(data = gasoline_df,gasoline~date)Above, we created a model variable for the linear trend model. In order to compare the models, we have to extract the adjusted coefficients of determination, that is used to compare regression models with a different number of explanatory variables, from each trend models.
Adjusted $latex R^2&s=1=1-(1-R^2&s=1)(\frac {n-1} {n-k-1})$
$latex n$: sample size
$latex k$: number of variables
$latex R^2&s=1$: coefficient of determination which is the square of correlation of observation values with predicted values: $latex r^2_{y \hat {y}}$
adj_r_squared_linear <- summary(model_linear) %>% .$adj.r.squared %>% round(4)The exponential trend; unlike the linear trend, allows the series to increase at an increasing rate in each period, is described as:
$latex \ln(y_{t}&s=1)=\beta_{0}+\beta_{1}t&s=1+\epsilon_{t}$. $latex \ln(y_{t}&s=1)$ is a natural logarithm of the response variable.
To make predictions on the fitted model, we use exponential function as $latex \hat{y_{t}}&s=1=exp(b_{0}+b_{1}t+s_{e}^2/2)$ because the dependent variable was transformed by a natural logarithmic function. In order for $latex \hat{y_{t}}&s=1$ not to be under the expected value of $latex y{t}&s=1$, we add half of the residual standard error's square. In order to find $latex s_{e}&s=2$, we execute the summary function as below. In addition, we can see the level of significance of the coefficients and the model. As we see below, because the p-value of the coefficients and the model are less than 0.05, they are significant at the %5 level of significance.
summary(model_exponential) #Call: #lm(formula = log(gasoline) ~ date, data = gasoline_df) #Residuals: # Min 1Q Median 3Q Max #-0.216180 -0.083077 0.009544 0.087953 0.151469 #Coefficients: # Estimate Std. Error t value Pr(<|t|) #(Intercept) -1.0758581 0.2495848 -4.311 4.5e-05 *** #date 0.0001606 0.0000147 10.928 < 2e-16 *** #--- #Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 #Residual standard error: 0.09939 on 82 degrees of freedom #Multiple R-squared: 0.5929, Adjusted R-squared: 0.5879 #F-statistic: 119.4 on 1 and 82 DF, p-value: < 2.2e-16We create an exponential model variable.
model_exponential <- lm(data = gasoline_df,log(gasoline)~date)To get adjusted $latex R^2&s=1$, we first transform the predicted variable.
library(purrr) y_predicted <- model_exponential$fitted.values %>% map_dbl(~exp(.+0.09939^2/2))And then, we execute the formula shown above to get adjusted $latex R^2&s=1$
r_squared_exponential <- (cor(y_predicted,gasoline_df$gasoline))^2 adj_r_squared_exponential <- 1-(1-r_squared_exponential)* ((nrow(gasoline_df)-1)/(nrow(gasoline_df)-1-1))Sometimes a time-series changes the direction with respect to many reasons. This kind of target variable is fitted to polynomial trend models. If there is one change of direction we use the quadratic trend model.
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t+\beta_{2}t^2+\epsilon$
If there are two change of direction we use the cubic trend models:
$latex y_{t}&s=1=\beta_{0}+\beta_{1}t+\beta_{2}t^2+\beta_{3}t^3+\epsilon$
Then again, we execute the same process as we did in the linear model.
#Model variables model_quadratic <- lm(data = df,gasoline~poly(date,2)) model_cubic <- lm(data = df,gasoline~poly(date,3)) #adjusted coefficients of determination adj_r_squared_quadratic <- summary(model_quadratic) %>% .$adj.r.squared adj_r_squared_cubic <- summary(model_cubic) %>% .$adj.r.squaredIn order to compare all models, we create a variable that gathers all adjusted $latex R^2&s=1$.
adj_r_squared_all <- c(linear=round(adj_r_squred_linear,4),
exponential=round(adj_r_squared_exponential,4),
quadratic=round(adj_r_squared_quadratic,4),
cubic=round(adj_r_squared_cubic,4))
As we can see below, the results justify the graphic we built before; polynomial models are much better than the linear and exponential models. Despite polynomial models look almost the same, the quadratic model is slightly better than the cubic model.adj_r_squared_all
#linear exponential quadratic cubic
#0.6064 0.6477 0.8660 0.8653
SeasonalityThe seasonality component represents the repeats in a specific period of time. Time series with weekly monthly or quarterly observations tend to show seasonal variations that repeat every year. For example, the sale of retail goods increases every year in the Christmas period or the holiday tours increase in the summer. In order to detect seasonality, we use decomposition analysis.
Decomposition analysis: $latex T, S, I&s=1$, are trend, seasonality and random components of the series respectively. When seasonal variation increases as the time series increase, we'd use the multiplicative model.
$latex y_{t}&s=1=T_{t} \times S_{t} \times I_{t}$
If the variation looks constant, we should use additive model.
$latex y_{t}&s=1=T_{t} + S_{t} + I_{t}$
To find which model is fit, we have to look at it on the graph.
#we create a time series variable for the plot gasoline_ts <- ts(gasoline_df$gasoline,start = c(2013,1),end = c(2019,12),frequency = 12) #The plot have all the components of the series(T, S, I) plot(gasoline_ts,lwd=2,ylab="Gasoline")
As we can see from the plot above, it seems that the multiplicative model would be more fit for the data; especially if we look at between 2016-2019. When we analyze the graph, we see some conjuncture variations caused by the expansion or contraction of the economy. Unlike seasonality, conjuncture fluctuations can be several months or years in length.
Additionally, the magnitude of conjuncture fluctuation can change in time because the fluctuations differ in magnitude and length so they are hard to reflect with historical data; because of that, we neglected the conjuncture component of the series.
Extracting the seasonality
Moving averages (ma) usually be used to separate the effect of a trend from seasonality.
$latex m\,\,term\,\,moving\,\,averages&s=1=\frac {Average\,\,of\,\,the\,\,last\,\,m\,\,observations} {m}$
We use the cumulative moving average (CMA), which is the average of two consecutive averages, to show the even-order moving average. For example; first two ma terms are $latex \bar{y}_{6.5}&s=1$ and $latex \bar{y}_{7.5}&s=1$ but there are no such terms in the original series; therefore we average the two terms to find CMA term matched up in the series:
$latex \bar y_7&s=3=$$latex \frac {\bar y_{6,5}&s=3+\bar y_{7,5}} {2}$
The default value of the 'centre' argument of the ma function remains TRUE to get CMA value.
library(forecast) gasoline_trend <- forecast::ma(gasoline_ts,12)If noticed, $latex \bar y_{t}&s=1$ eliminates both seasonal and random variations; hence: $latex \bar y_{t}&s=1=T_{t}$
Since $latex y_{t}&s=1=T_{t} \times S_{t} \times I_{t}$ and $latex \bar y_{t}&s=1=T_{t}$, the detrend variable is found by: $latex \frac {\bar y_{t}} {y_{t}}&s=1=S_{t} \times I_{t}$; it is also called ratio-to moving averages method.
gasoline_detrend <- gasoline_ts/gasoline_trendEach month has multiple ratios, where each ratio coincides with a different year; in this sample, each month has seven different ratios. The arithmetic average is used to determine common value for each month; by doing this, we eliminate the random component and subtract the seasonality from the detrend variable. It is called the unadjusted seasonal index.
unadjusted_seasonality <- sapply(1:12, function(x) mean(window(gasoline_detrend,c(2013,x),c(2019,12),deltat=1),na.rm = TRUE)) %>% round(4)Seasonal indexes for monthly data should be completed to 12, with an average of 1; in order to do that each unadjusted seasonal index is multiplied by 12 and divided by the sum of 12 unadjusted seasonal indexes.
adjusted_seasonality <- (unadjusted_seasonality*(12/sum(unadjusted_seasonality))) %>%
round(4)
The average of all adjusted seasonal indices is 1; if an index is equal to 1, that means there would be no seasonality. In order to plot seasonality:#building a data frame to plot in ggplot
adjusted_seasonality_df <- data_frame(
months=month.abb,
index=adjusted_seasonality)
#converting char month names to factor sequentially
adjusted_seasonality_df$months <- factor(adjusted_seasonality_df$months,levels = month.abb)
ggplot(data = adjusted_seasonality_df,mapping = aes(x=months,y=index))+
geom_point(aes(colour=months))+
geom_hline(yintercept=1,linetype="dashed")+
theme(legend.position = "none")+
ggtitle("Seasonality of Unleaded Gasoline Prices for 95 Octane")+
theme(plot.title = element_text(h=0.5))
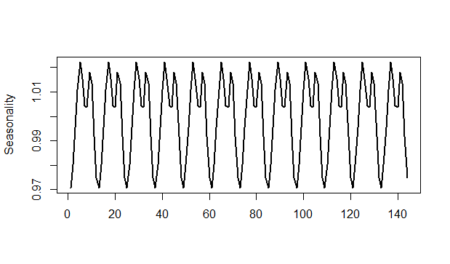
As we can see above, there is approximately a three-percent seasonal decrease in January and December; on the other hand, there is a two-percent seasonal increase in May and June. Seasonality is not seen in March, July, and August; because their index values are approximately equal to 1.
Decomposing the time series graphically
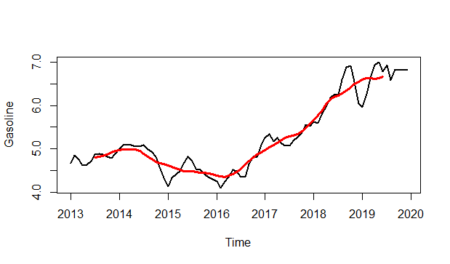
We will first show the trend line on the time series.
#Trend is shown by red line plot(gasoline_ts,lwd=2,ylab="Gasoline")+ lines(gasoline_trend,col="red",lwd=3)
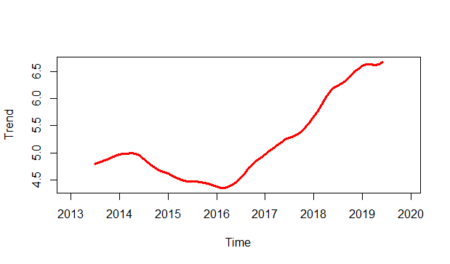
And will isolate the trend line from the plot:
plot(gasoline_trend,lwd=3,col="red",ylab="Trend")
Let's see the seasonality line:
plot(as.ts(rep(unadjusted_seasonality,12)),lwd=2,ylab="Seasonality",xlab="")
And finally, we will show the randomness line; in order to do that:$latex I_{t}&s=1=\frac {y_{t}} {S_{t}\times T_{t}}$
randomness <- gasoline_ts/(gasoline_trend*unadjusted_seasonality) plot(randomness,ylab="Randomness",lwd=2)
References
Sanjiv Jaggia, Alison Kelly (2013). Business Intelligence: Communicating with Numbers.
tsmp v0.4.8 release – Introducing the Matrix Profile API
A new tool for painlessly analyzing your time series
We’re surrounded by time-series data. From finance to IoT to marketing, many organizations produce thousands of these metrics and mine them to uncover business-critical insights. A Site Reliability Engineer might monitor hundreds of thousands of time series streams from a server farm, in the hopes of detecting anomalous events and preventing catastrophic failure. Alternatively, a brick and mortar retailer might care about identifying patterns of customer foot traffic and leveraging them to guide inventory decisions.
Identifying anomalous events (or “discords”) and repeated patterns (“motifs”) are two fundamental time-series tasks. But how does one get started? There are dozens of approaches to both questions, each with unique positives and drawbacks. Furthermore, time-series data is notoriously hard to analyze, and the explosive growth of the data science community has led to a need for more “black-box” automated solutions that can be leveraged by developers with a wide range of technical backgrounds.
We at the Matrix Profile Foundation believe there’s an easy answer. While it’s true that there’s no such thing as a free lunch, the Matrix Profile (a data structure & set of associated algorithms developed by the Keogh research group at UC-Riverside) is a powerful tool to help solve this dual problem of anomaly detection and motif discovery. Matrix Profile is robust, scalable, and largely parameter-free: we’ve seen it work for a wide range of metrics including website user data, order volume and other business-critical applications. And as we will detail below, the Matrix Profile Foundation has implemented the Matrix Profile across three of the most common data science languages (Python, R and Golang) as an easy-to-use API that’s relevant for time series novices and experts alike.
The basics of Matrix Profile are simple: If I take a snippet of my data and slide it along the rest of the time series, how well does it overlap at each new position? More specifically, we can evaluate the Euclidean distance between a subsequence and every possible time series segment of the same length, building up what’s known as the snippet’s “Distance Profile.” If the subsequence repeats itself in the data, there will be at least one match and the minimum Euclidean distance will be zero (or close to zero in the presence of noise).
In contrast, if the subsequence is highly unique (say it contains a significant outlier), matches will be poor and all overlap scores will be high. Note that the type of data is irrelevant: We’re only looking at pattern conservation. We then slide every possible snippet across the time series, building up a collection of Distance Profiles. By taking the minimum value for each time step across all distance profiles, we can build the final Matrix Profile. Notice that both ends of the Matrix Profile value spectrum are useful. High values indicate uncommon patterns or anomalous events; in contrast, low values highlight repeatable motifs and provide valuable insight into your time series of interest. For those interested, this post by one of our co-founders provides a more in-depth discussion of the Matrix Profile.
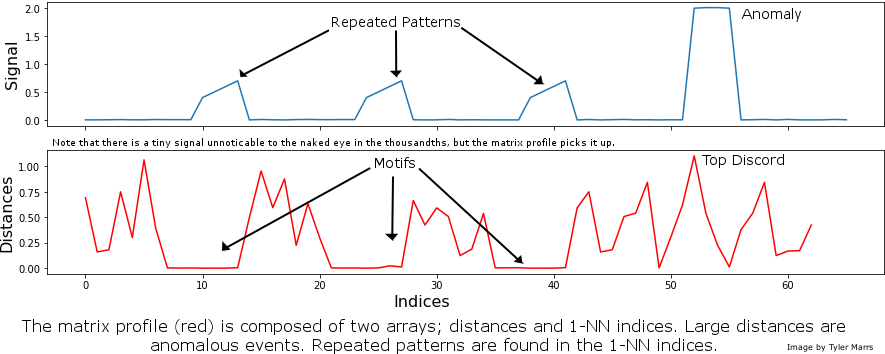
Although the Matrix Profile can be a game-changer for time series analysis, leveraging it to produce insights is a multi-step computational process, where each step requires some level of domain experience. However, we believe that the most powerful breakthroughs in data science occur when the complex is made accessible. When it comes to the Matrix Profile, there are three facets to accessibility: “out-of-the-box” working implementations, gentle introductions to core concepts that can naturally lead into deeper exploration, and multi-language accessibility. Today, we’re proud to unveil the Matrix Profile API (MPA), a common codebase written in R, Python and Golang that achieves all three of these goals.
Using the Matrix Profile consists of three steps. First, you Compute the Matrix Profile itself. However, this is not the end: you need to Discover something by leveraging the Matrix Profile that you’ve created. Do you want to find repeated patterns? Or perhaps uncover anomalous events? Finally, it’s critical that you Visualize your findings, as time series analysis greatly benefits from some level of visual inspection.
Normally, you’d need to read through pages of documentation (both academic and technical) to figure out how to execute each of these three steps. This may not be a challenge if you’re an expert with prior knowledge of the Matrix Profile, but we’ve seen that many users simply want to Analyze their data by breaking through the methodology to get to a basic starting point. Can the code simply leverage some reasonable defaults to produce a reasonable output?
To parallel this natural computational flow, MPA consists of three core components:
As an example, we’ll use the R flavour of MPA to analyze the synthetic time series shown below (here is the code):
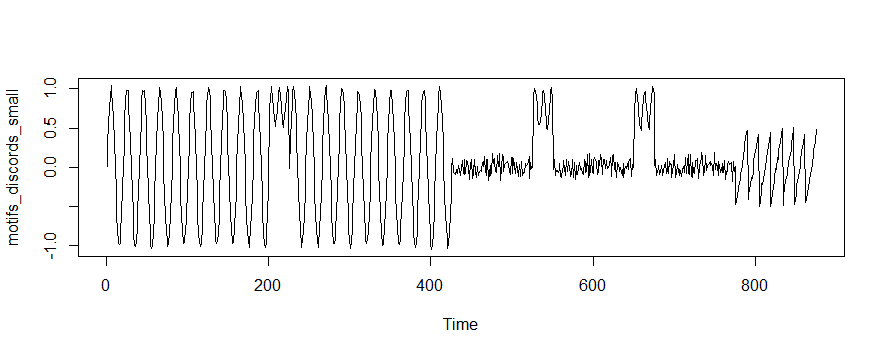 Visual inspection reveals that there are both patterns and discords present. However, one immediate problem is that your choice of subsequence length will change both the number and location of your motifs! Are there only two sinusoidal motifs present between indices 0-500, or is each cycle an instance of the pattern? Let’s see how MPA handles this challenge:
Visual inspection reveals that there are both patterns and discords present. However, one immediate problem is that your choice of subsequence length will change both the number and location of your motifs! Are there only two sinusoidal motifs present between indices 0-500, or is each cycle an instance of the pattern? Let’s see how MPA handles this challenge:
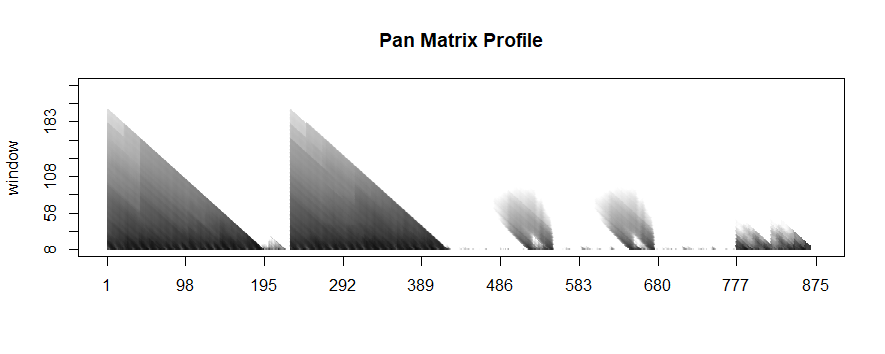
Because we haven’t specified any information regarding our subsequence length, `analyze` begins by leveraging a powerful calculation known as the pan-matrix profile (or PMP) to generate insights that will help us evaluate different subsequence lengths. We’ll discuss the details of PMP in a later post (or you can read the associated paper), but in a nutshell, it is a global calculation of all possible subsequence lengths condensed into a single visual summary. The X-axis is the index of the matrix profile, and the Y-axis is the corresponding subsequence length. The darker the shade, the lower the Euclidean distance at that point. We can use the “peaks” of the triangles to find the 6 “big” motifs visually present in the synthetic time series.
The PMP is all well and good, but we promised a simple way of understanding your time series. To facilitate this, `analyze` will combine PMP with an under the hood algorithm to choose sensible motifs and discords from across all possible window sizes. The additional graphs created by `analyze` show the top three motifs and top three discords, along with the corresponding window size and position within the Matrix Profile (and, by extension, your time series).
Not surprisingly, this is a lot of information coming out of the default setting. Our goal is that this core function call can serve as a jumping-off point for many of your future analyses. For example, the PMP indicates that there is a conserved motif of length ~175 within our time series. Try calling `analyze` on that subsequence length and see what happens!
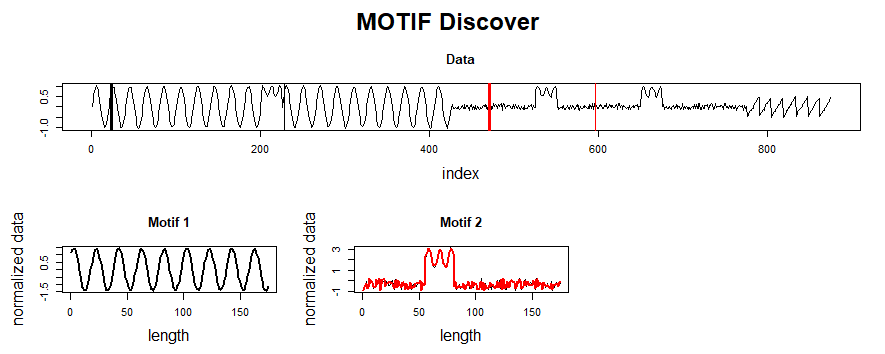
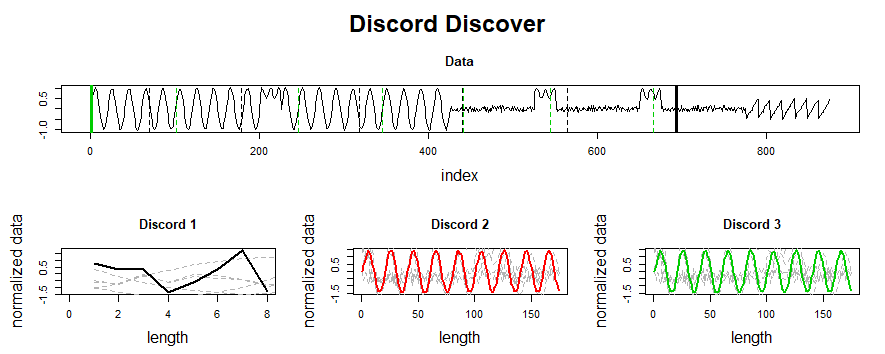
We hope that MPA enables you to more painlessly analyze your time series! For further information, visit our website (https://matrixprofile.org/), GitHub repos (https://github.com/matrix-profile-foundation) or follow us on Twitter (https://twitter.com/matrixprofile). MPF also operates a Discord channel where you can engage with fellow users of the Matrix Profile and ask questions. Happy time series hunting!
Acknowledgements
Thank you to Tyler Marrs, Frankie Cancino, Francisco Bischoff, Austin Ouyang and Jack Green for reviewing this article and assisting in its creation. And above all, thank you to Eamonn Keogh, Abdullah Mueen and their numerous graduate students for creating the Matrix Profile and continuing to drive its development.
Supplemental
We’re surrounded by time-series data. From finance to IoT to marketing, many organizations produce thousands of these metrics and mine them to uncover business-critical insights. A Site Reliability Engineer might monitor hundreds of thousands of time series streams from a server farm, in the hopes of detecting anomalous events and preventing catastrophic failure. Alternatively, a brick and mortar retailer might care about identifying patterns of customer foot traffic and leveraging them to guide inventory decisions.
Identifying anomalous events (or “discords”) and repeated patterns (“motifs”) are two fundamental time-series tasks. But how does one get started? There are dozens of approaches to both questions, each with unique positives and drawbacks. Furthermore, time-series data is notoriously hard to analyze, and the explosive growth of the data science community has led to a need for more “black-box” automated solutions that can be leveraged by developers with a wide range of technical backgrounds.
We at the Matrix Profile Foundation believe there’s an easy answer. While it’s true that there’s no such thing as a free lunch, the Matrix Profile (a data structure & set of associated algorithms developed by the Keogh research group at UC-Riverside) is a powerful tool to help solve this dual problem of anomaly detection and motif discovery. Matrix Profile is robust, scalable, and largely parameter-free: we’ve seen it work for a wide range of metrics including website user data, order volume and other business-critical applications. And as we will detail below, the Matrix Profile Foundation has implemented the Matrix Profile across three of the most common data science languages (Python, R and Golang) as an easy-to-use API that’s relevant for time series novices and experts alike.
The basics of Matrix Profile are simple: If I take a snippet of my data and slide it along the rest of the time series, how well does it overlap at each new position? More specifically, we can evaluate the Euclidean distance between a subsequence and every possible time series segment of the same length, building up what’s known as the snippet’s “Distance Profile.” If the subsequence repeats itself in the data, there will be at least one match and the minimum Euclidean distance will be zero (or close to zero in the presence of noise).
In contrast, if the subsequence is highly unique (say it contains a significant outlier), matches will be poor and all overlap scores will be high. Note that the type of data is irrelevant: We’re only looking at pattern conservation. We then slide every possible snippet across the time series, building up a collection of Distance Profiles. By taking the minimum value for each time step across all distance profiles, we can build the final Matrix Profile. Notice that both ends of the Matrix Profile value spectrum are useful. High values indicate uncommon patterns or anomalous events; in contrast, low values highlight repeatable motifs and provide valuable insight into your time series of interest. For those interested, this post by one of our co-founders provides a more in-depth discussion of the Matrix Profile.
Although the Matrix Profile can be a game-changer for time series analysis, leveraging it to produce insights is a multi-step computational process, where each step requires some level of domain experience. However, we believe that the most powerful breakthroughs in data science occur when the complex is made accessible. When it comes to the Matrix Profile, there are three facets to accessibility: “out-of-the-box” working implementations, gentle introductions to core concepts that can naturally lead into deeper exploration, and multi-language accessibility. Today, we’re proud to unveil the Matrix Profile API (MPA), a common codebase written in R, Python and Golang that achieves all three of these goals.
Using the Matrix Profile consists of three steps. First, you Compute the Matrix Profile itself. However, this is not the end: you need to Discover something by leveraging the Matrix Profile that you’ve created. Do you want to find repeated patterns? Or perhaps uncover anomalous events? Finally, it’s critical that you Visualize your findings, as time series analysis greatly benefits from some level of visual inspection.
Normally, you’d need to read through pages of documentation (both academic and technical) to figure out how to execute each of these three steps. This may not be a challenge if you’re an expert with prior knowledge of the Matrix Profile, but we’ve seen that many users simply want to Analyze their data by breaking through the methodology to get to a basic starting point. Can the code simply leverage some reasonable defaults to produce a reasonable output?
To parallel this natural computational flow, MPA consists of three core components:
- Compute (computing the Matrix Profile)
- Discover (evaluate the MP for motifs, discords, etc)
- Visualize (display results through basic plots)
As an example, we’ll use the R flavour of MPA to analyze the synthetic time series shown below (here is the code):
Visual inspection reveals that there are both patterns and discords present. However, one immediate problem is that your choice of subsequence length will change both the number and location of your motifs! Are there only two sinusoidal motifs present between indices 0-500, or is each cycle an instance of the pattern? Let’s see how MPA handles this challenge:Because we haven’t specified any information regarding our subsequence length, `analyze` begins by leveraging a powerful calculation known as the pan-matrix profile (or PMP) to generate insights that will help us evaluate different subsequence lengths. We’ll discuss the details of PMP in a later post (or you can read the associated paper), but in a nutshell, it is a global calculation of all possible subsequence lengths condensed into a single visual summary. The X-axis is the index of the matrix profile, and the Y-axis is the corresponding subsequence length. The darker the shade, the lower the Euclidean distance at that point. We can use the “peaks” of the triangles to find the 6 “big” motifs visually present in the synthetic time series.
The PMP is all well and good, but we promised a simple way of understanding your time series. To facilitate this, `analyze` will combine PMP with an under the hood algorithm to choose sensible motifs and discords from across all possible window sizes. The additional graphs created by `analyze` show the top three motifs and top three discords, along with the corresponding window size and position within the Matrix Profile (and, by extension, your time series).
Not surprisingly, this is a lot of information coming out of the default setting. Our goal is that this core function call can serve as a jumping-off point for many of your future analyses. For example, the PMP indicates that there is a conserved motif of length ~175 within our time series. Try calling `analyze` on that subsequence length and see what happens!
We hope that MPA enables you to more painlessly analyze your time series! For further information, visit our website (https://matrixprofile.org/), GitHub repos (https://github.com/matrix-profile-foundation) or follow us on Twitter (https://twitter.com/matrixprofile). MPF also operates a Discord channel where you can engage with fellow users of the Matrix Profile and ask questions. Happy time series hunting!
Acknowledgements
Thank you to Tyler Marrs, Frankie Cancino, Francisco Bischoff, Austin Ouyang and Jack Green for reviewing this article and assisting in its creation. And above all, thank you to Eamonn Keogh, Abdullah Mueen and their numerous graduate students for creating the Matrix Profile and continuing to drive its development.
Supplemental
- Matrix Profile research papers can be found on Eamonn Keogh’s UCR web page: https://www.cs.ucr.edu/~eamonn/MatrixProfile.html
- The Python implementation of Matrix Profile algorithms can be found here: https://github.com/matrix-profile-foundation/matrixprofile
- The R implementation of Matrix Profile algorithms can be found here: https://github.com/matrix-profile-foundation/tsmp
- The Golang implementation of Matrix Profile algorithms can be found here: https://github.com/matrix-profile-foundation/go-matrixprofile
Machine Learning with R: A Hands-on Introduction from Robert Muenchen at Machine Learning Week, Las Vegas
Join Robert Muenchen’s workshop about Machine Learning with R at Machine Learning Week on May 31 – June 4, 2020 in Las Vegas!
Workshop Description
The Workshop will take place in May 31, 2020.
R offers a wide variety of machine learning (ML) functions, each of which works in a slightly different way. This one-day, hands-on workshop starts with ML basics and takes you step-by-step through increasingly complex modeling styles. This workshop makes ML modeling easier through the use of packages that standardize the way the various functions work. When finished, you should be able to use R to apply the most popular and effective machine learning models to make predictions and assess the likely accuracy of those predictions. The instructor will guide attendees on hands-on execution with R, covering:
Each workshop participant is required to bring their laptop. Software installation instructions are available at http://r4stats.com/workshops/PAW2020. Attendees receive an electronic copy of the course materials and related R code after the workshop.
See more information about the workshop here.

Workshop Description
The Workshop will take place in May 31, 2020.
R offers a wide variety of machine learning (ML) functions, each of which works in a slightly different way. This one-day, hands-on workshop starts with ML basics and takes you step-by-step through increasingly complex modeling styles. This workshop makes ML modeling easier through the use of packages that standardize the way the various functions work. When finished, you should be able to use R to apply the most popular and effective machine learning models to make predictions and assess the likely accuracy of those predictions. The instructor will guide attendees on hands-on execution with R, covering:
-
- A brief introduction to R’s tidyverse functions, including a comparison of the caret and parsnip packages
- Pre-processing data
- Selecting variables
- Partitioning data for model development and validation
- Setting model training controls
- Developing predictive models using naïve Bayes, classification and regression trees, random forests, gradient boosting machines, and neural networks (more, if time permits)
- Evaluating model effectiveness using measures of accuracy and visualization
- Interpreting what “black-box” models are doing internally
Each workshop participant is required to bring their laptop. Software installation instructions are available at http://r4stats.com/workshops/PAW2020. Attendees receive an electronic copy of the course materials and related R code after the workshop.
See more information about the workshop here.
XGBoostLSS – An extension of XGBoost to probabilistic forecasting

Introduction
To reason rigorously under uncertainty we need to invoke the language of probability (Zhang et al. 2020). Any model that falls short of providing quantification of the uncertainty attached to its outcome is likely to yield an incomplete and potentially misleading picture. While this is an irrevocable consensus in statistics, a common misconception, albeit a very persistent one, is that machine learning models usually lack proper ways of quantifying uncertainty. Despite the fact that the two terms exist in parallel and are used interchangeably, the perception that machine learning and statistics imply a non-overlapping set of techniques remains lively, both among practitioners and academics. This is vividly portrayed by the provocatively (and potentially tongue-in-cheek) statement of Brian D. Ripley that ‘machine learning is statistics minus any checking of models and assumptions‘ that he made during the useR! 2004, Vienna conference that served to illustrate the difference between machine learning and statistics.
In fact, the relationship between statistics and machine learning is artificially complicated by such statements and is unfortunate at best, as it implies a profound and qualitative distinction between the two disciplines (Januschowski et al. 2020). The paper by Breiman (2001) is a noticeable exception, as it proposes to differentiate the two based on scientific culture, rather than on methods alone. While the approaches discussed in Breiman (2001) are an admissible partitioning of the space of how to analyse and model data, more recent advances have gradually made this distinction less clear-cut. In fact, the current research trend in both statistics and machine learning gravitates towards bringing both disciplines closer together. In an era of increasing necessity that the output of prediction models needs to be turned into explainable and reliable insights, this is an exceedingly promising and encouraging development, as both disciplines have much to learn from each other. Along with Januschowski et al. (2020), we argue that it is more constructive to seek common ground than it is to introduce artificial boundaries.
In order to further closing the gap between the two cultures, we propose a new framework of the eminent XGBoost that predicts the entire conditional distribution of a univariate response variable. We term our model XGBoostLSS, as it combines the accuracy and speed of XGBoost with the flexibility and interpretability of GAMLSS that allow for the estimation and prediction of the entire conditional distribution. In particular, XGBoostLSS models all moments of a parametric distribution (i.e., mean, location, scale and shape [LSS]) instead of the conditional mean only. XGBoostLSS allows the user to choose from a wide range of continuous, discrete and mixed discrete-continuous distributions to better adapt to the data at hand, as well as to provide predictive distributions, from which prediction intervals and quantiles can be derived.
Applications
In the following, we present both a simulation study and a real-world example that demonstrate the functionality of XGBoostLSS.
Simulation
We start with a simulated a data set that exhibits heteroskedasticity, where the interest lies in predicting the 5% and 95% quantiles. Points outside the 5% and 95% quantile are coloured in red, with the black dashed lines depicting the actual 5% and 95% quantiles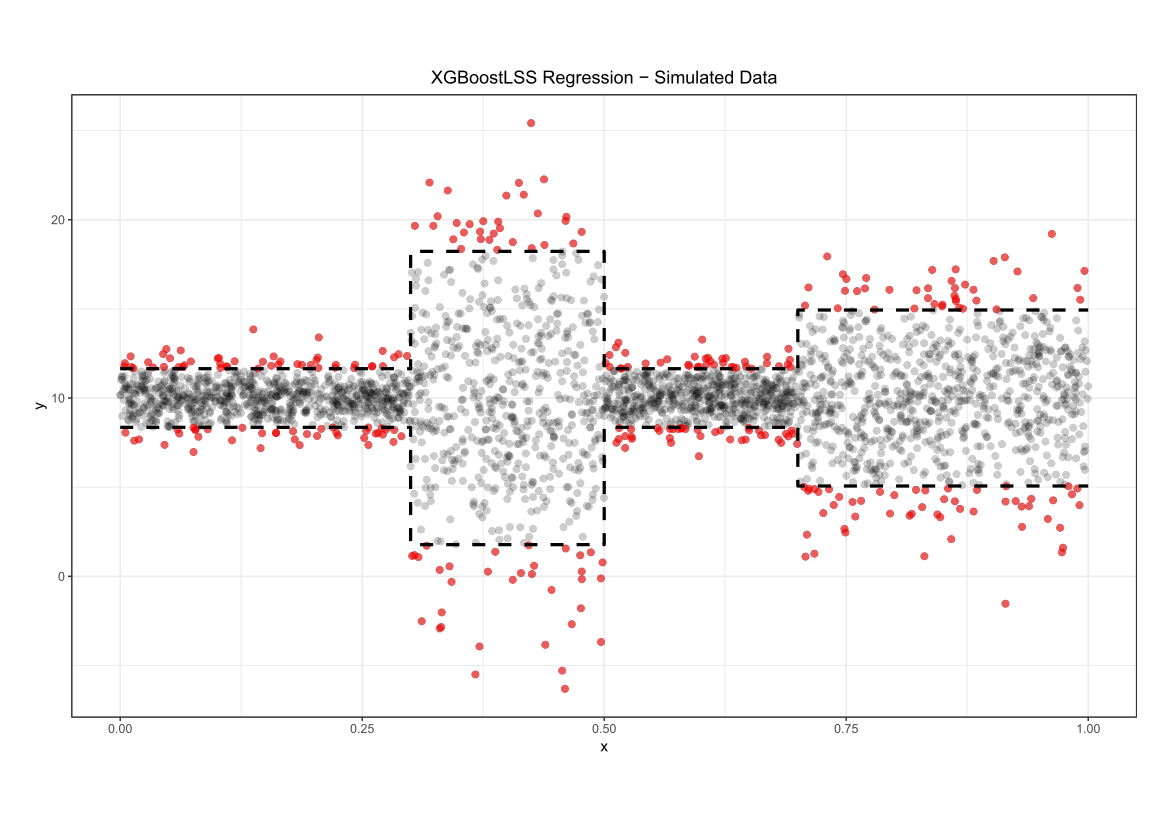
Let’s fit the XGBoostLSS model to the data. In general, the syntax is similar to the original XGBoost implementation. However, the user has to make a distributional assumption by specifying a family in the function call. As the data has been generated by a Normal distribution, we use the Normal as a function input. The user also has the option of providing a list of hyper-parameters that are used for training the surrogate regression model to find an optimized set of parameters. As our model allows to model the entire conditional distribution, we obtain prediction intervals and quantiles of interest directly from the predicted quantile function. Once the model is trained, we can predict all parameter of the distribution. The following Figure shows the predictions of XGBoostLSS for the 5% and 95% quantile in blue.
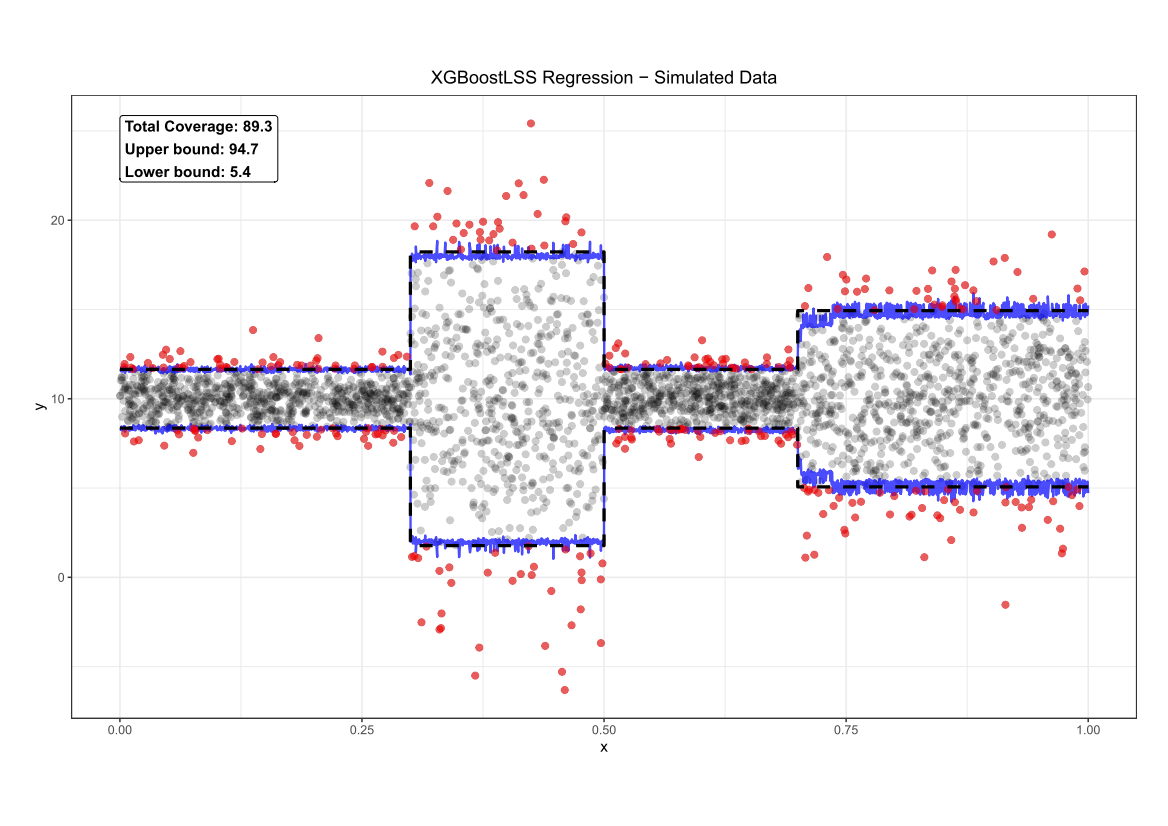 Comparing the coverage of the intervals with the nominal level of 90% shows that XGBoostLSS does not only correctly model the heteroskedasticity in the data, but it also provides an accurate forecast for the 5% and 95% quantiles. The flexibility of XGBoostLSS also comes from its ability to provide attribute importance, as well as partial dependence plots, for all of the distributional parameters. In the following we only investigate the effect on the conditional variance.
Comparing the coverage of the intervals with the nominal level of 90% shows that XGBoostLSS does not only correctly model the heteroskedasticity in the data, but it also provides an accurate forecast for the 5% and 95% quantiles. The flexibility of XGBoostLSS also comes from its ability to provide attribute importance, as well as partial dependence plots, for all of the distributional parameters. In the following we only investigate the effect on the conditional variance. 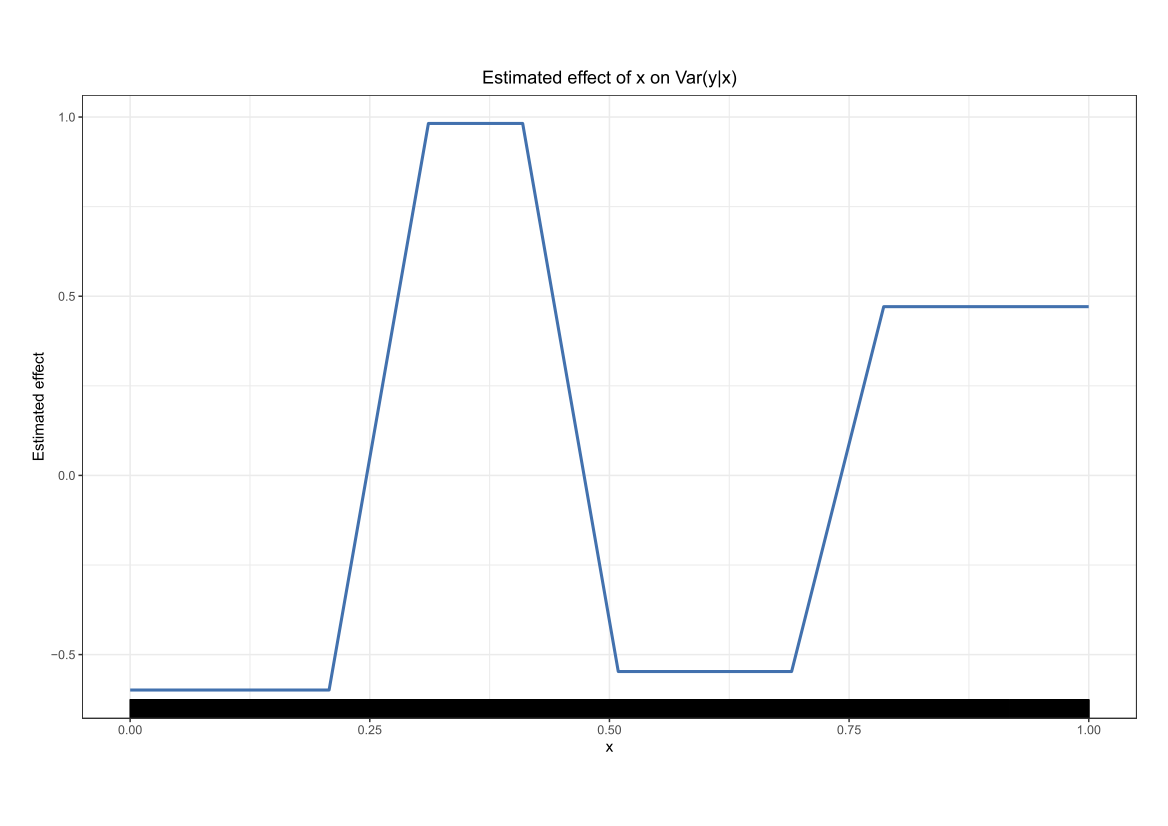
Munich Rent
Considering there is an active discussion around imposing a freeze in German cities on rents, we have chosen to re-visit the famous Munich Rent data set commonly used in the GAMLSS literature, as Munich is among the most expensive cities in Germany when it comes to living costs. As our dependent variable, we select Net rent per square meter in EUR.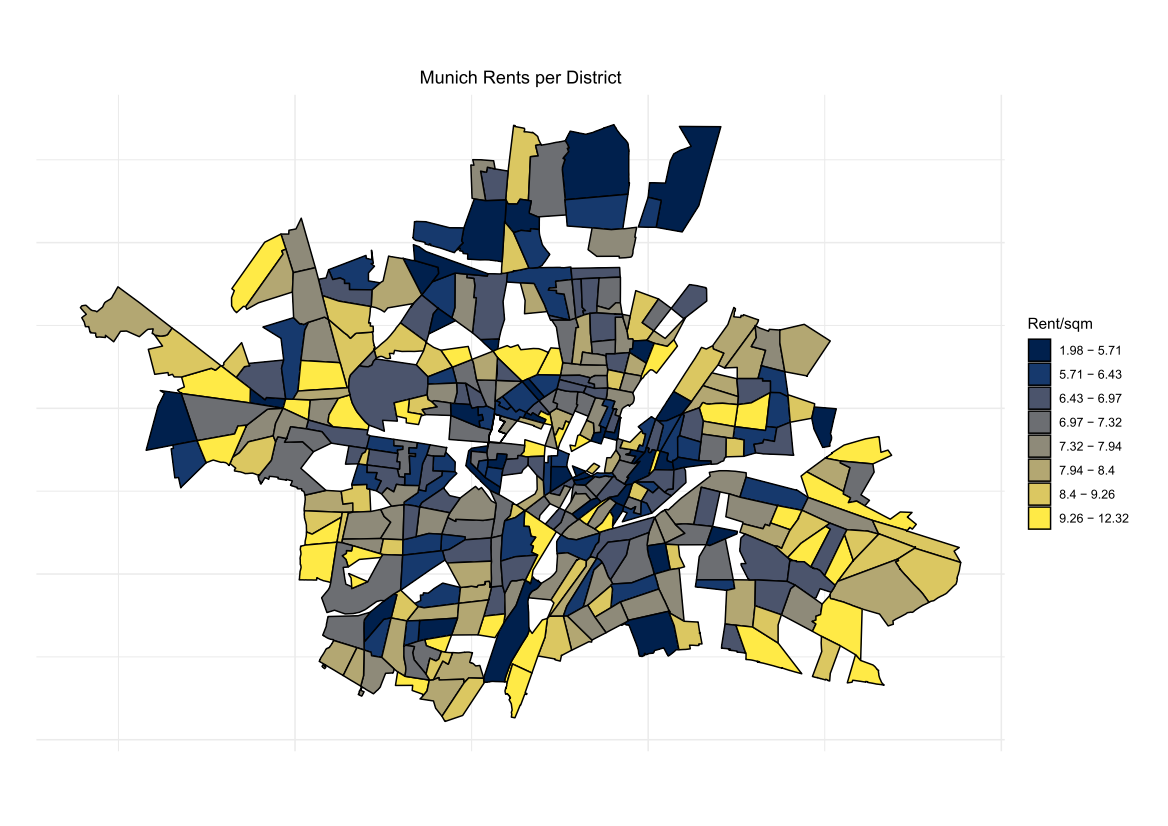
Even though the Generalized Beta Type 2 to provide the best approximation to the data, we use the more parsimonious Normal distribution, as it has only two distributional parameters, compared to 4 of the Generalized Beta Type 2.
Now that we have specified the distribution, we fit XGBoostLSS to the data. Again, we use Bayesian Optimization for finding an optimal set of hyper-parameters. Looking at the estimated effects presented in the following Figure indicates that newer flats are on average more expensive, with the variance first decreasing and increasing again for flats built around 1980 and later. Also, as expected, rents per square meter decrease with an increasing size of the apartment.
The diagnostics for XGBoostLSS are based on quantile residuals of the fitted model and are shown in the following Figure.
Despite some slight under-fitting in the tails of the distribution, XGBoostLSS provides a well calibrated forecast and confirms that our model is a good approximation to the data. XGBoostLSS also allows to investigate feature importance for all distributional parameters. Looking at the top 10 features with the highest Shapley values for both the conditional mean and variance indicates that both yearc and area are considered as being the most important variables.
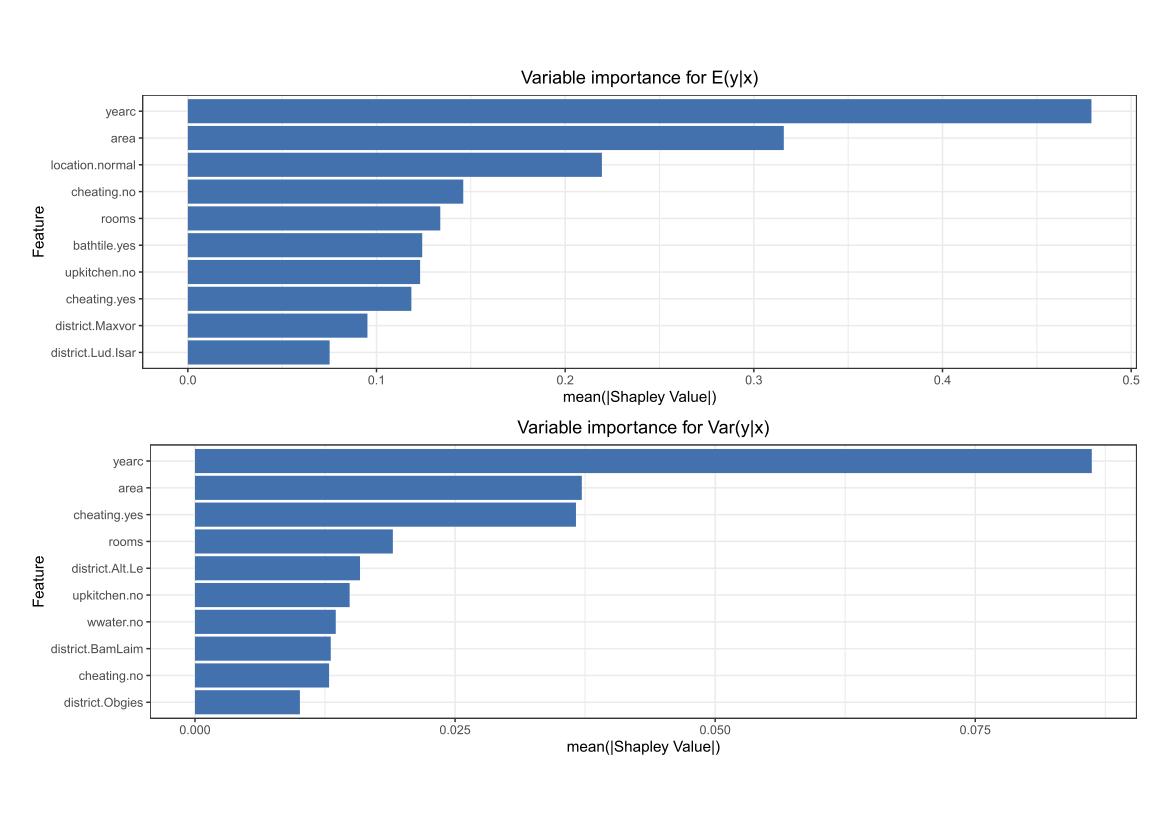
Besides the global attribute importance, the user might also be interested in local attribute importance for each single prediction individually. This allows to answer questions like ‘How did the feature values of a single data point affect its prediction?‘ For illustration purposes, we select the first predicted rent of the test data set and present the local attribute importance for the conditional mean.
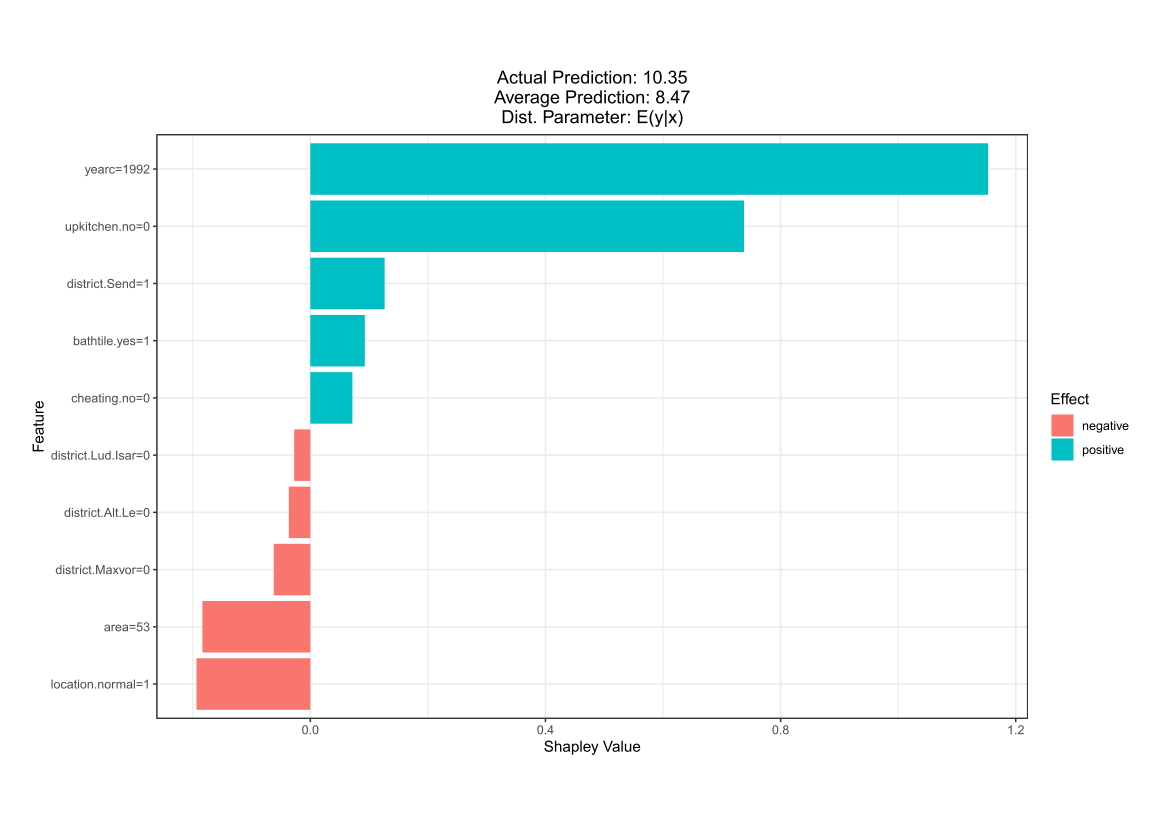
As we have modelled all parameters of the Normal distribution, XGBoostLSS provides a probabilistic forecast, from which any quantity of interest can be derived. Th following Figure shows a random subset of 50 predictions only for ease of readability. The red dots show the actual out of sample rents, while the boxplots visualize the predicted distributions.
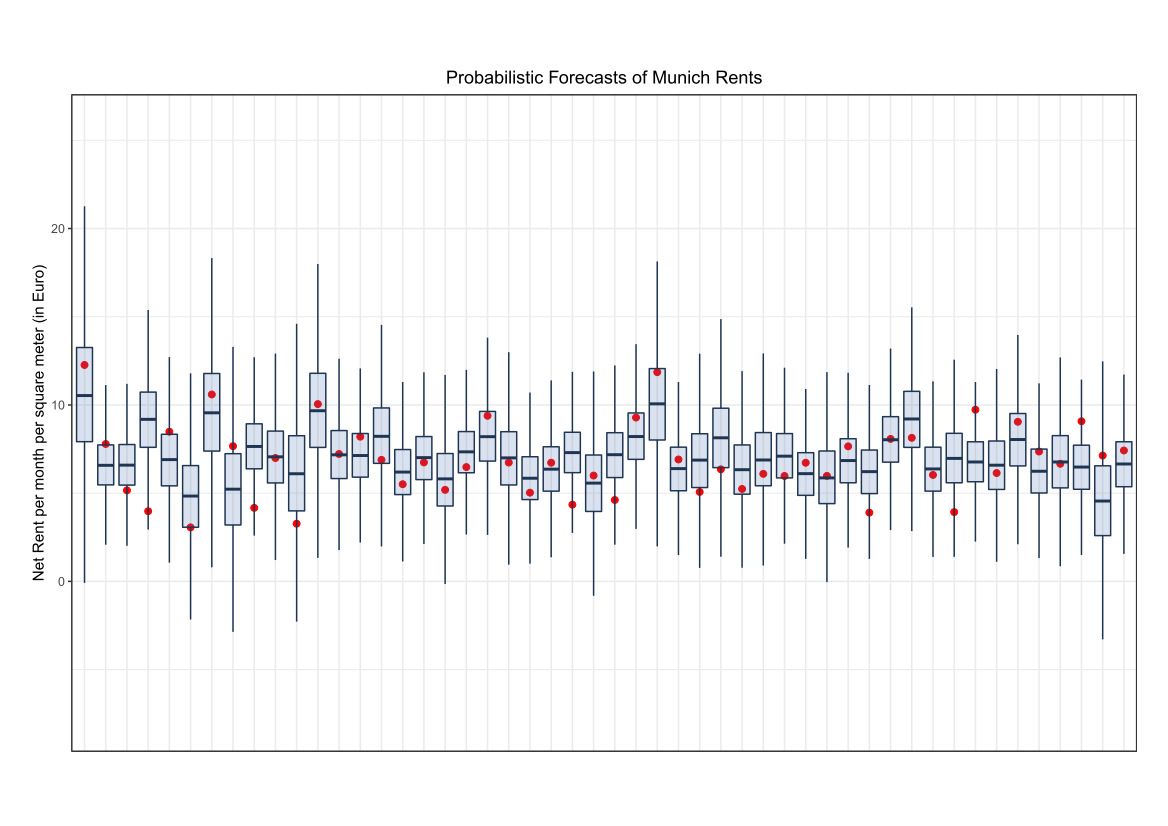
We can also plot a subset of the forecasted densities and cumulative distributions.
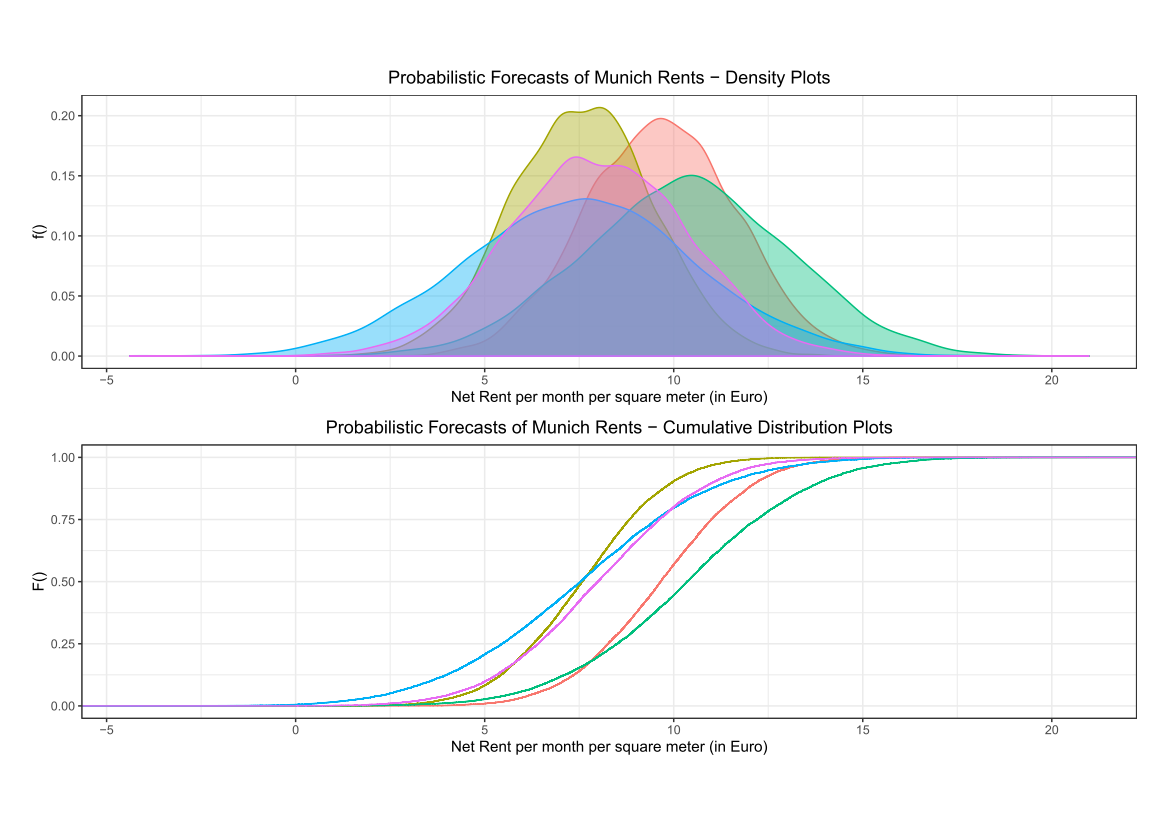
Comparison to other approaches
All measures, except the Median Absolute Error, show that XGBoostLSS provides more accurate forecasts than existing implementations.
Software Implementation
In its current implementation, XGBoostLSS is available in R and made publicly available soon on the Git-repo StatMixedML/XGBoostLSS. Extensions to Julia and Python are also planned. I am currently also working on an extension of CatBoost to allow for probabilistic forecasting. You may find it on the Git-repo StatMixedML/CatBoostLSS. Please note that due to time some restrictions, the public release of the package(s) may be somewhat delayed.
Reference Paper
März, Alexander (2019) “XGBoostLSS – An extension of XGBoost to probabilistic forecasting”.
März, Alexander (2020) “CatBoostLSS – An extension of CatBoost to probabilistic forecasting”.
The Premier Machine Learning Conference (15% discount code)
Attend any or all of the five jointly scheduled events! Get an additional 15% discount on your booking with the code RBLOGGERSMLW . Join us in Las Vegas for the largest Predictive Analytics World event to date! Learn more

5 days, 8 tracks, 160 speaker and over 150 exciting sessions
Join the Machine Learning Week 2020, May 31 – June 4, Las Vegas! It brings together five co-located events:
– Google: Join Richard Dutton (Head of Machine Learning for Corporate Engineering) at his session “How Google Uses AI and Machine Learning in the Enterprise”!
– Lyft: Gil Arditi (Product Lead, Machine Learning) will speak about “From Self-Driving to Fraud Detection – How Lyft Streamlines Machine Learning Deployment”.
– LinkedIn: You want to learn something about launching artificial intelligence products? Then the session from Priyanka Gariba (Head of Artificial Intelligence Technical Program Management) fits best for you!
– Visa: Abhishek Joshi ‘AJ’ (Senior Director) will explain you “The Predictive Power of Card Transaction Data”.
– Microsoft: Jaya Mathew (Senior Data Scientist) will present you “Getting the Most out of Your IoT Data: Basics of Predictive Maintenance, Bootstrapping you Model with Your Data & Comparing the Traditional vs Deep Learning Methodologies”
– Verizon: Join Bryan Larish Ph.D. (Director of Technology) at his session “Auditing Cellular Networks with Deep Learning”
See the full 8-track agenda here.
What are the 5 conferences about?
Predictive Analytics World for Business focuses on concrete examples of deployed predictive analytics. Hear from the horse’s mouth precisely how Fortune 500 analytics competitors and other top practitioners deploy machine learning, and the kind of business results they achieve. Predictive Analytics World for Financial Services is the leading data science event covering the deployment of machine learning by banks, insurance companies, credit card companies, investment firms, and other financial institutions. The Predictive Analytics World Healthcare program will feature sessions and case studies across Healthcare Business Operations and Clinical applications so you can witness how data science and machine learning are employed at leading enterprises, resulting in improved outcomes, lower costs, and higher patient satisfaction. Predictive Analytics World for Industry 4.0 is the leading vendor-neutral conference for machine learning for smart manufacturing and IoT. Data scientists, industrial planners, and other machine learning experts will meet in Las Vegas to explore the latest trends and technologies in machine & deep learning for the IoT era. Deep Learning World is the premier conference covering the commercial deployment of deep learning. The event’s mission is to foster breakthroughs in the value-driven operationalization of established deep learning methods.
Attend any or all of the five jointly scheduled events! Get an additional 15% discount on your booking with the code RBLOGGERSMLW . Join us in Las Vegas for the largest Predictive Analytics World event to date! Learn more
5 days, 8 tracks, 160 speaker and over 150 exciting sessions
Join the Machine Learning Week 2020, May 31 – June 4, Las Vegas! It brings together five co-located events:
-
- Predictive Analytics World for Business
- Predictive Analytics World for Financial Services
- Predictive Analytics World for Industry 4.0
- Predictive Analytics World for Healthcare
- Deep Learning World
– Google: Join Richard Dutton (Head of Machine Learning for Corporate Engineering) at his session “How Google Uses AI and Machine Learning in the Enterprise”!
– Lyft: Gil Arditi (Product Lead, Machine Learning) will speak about “From Self-Driving to Fraud Detection – How Lyft Streamlines Machine Learning Deployment”.
– LinkedIn: You want to learn something about launching artificial intelligence products? Then the session from Priyanka Gariba (Head of Artificial Intelligence Technical Program Management) fits best for you!
– Visa: Abhishek Joshi ‘AJ’ (Senior Director) will explain you “The Predictive Power of Card Transaction Data”.
– Microsoft: Jaya Mathew (Senior Data Scientist) will present you “Getting the Most out of Your IoT Data: Basics of Predictive Maintenance, Bootstrapping you Model with Your Data & Comparing the Traditional vs Deep Learning Methodologies”
– Verizon: Join Bryan Larish Ph.D. (Director of Technology) at his session “Auditing Cellular Networks with Deep Learning”
See the full 8-track agenda here.
What are the 5 conferences about?
Predictive Analytics World for Business focuses on concrete examples of deployed predictive analytics. Hear from the horse’s mouth precisely how Fortune 500 analytics competitors and other top practitioners deploy machine learning, and the kind of business results they achieve. Predictive Analytics World for Financial Services is the leading data science event covering the deployment of machine learning by banks, insurance companies, credit card companies, investment firms, and other financial institutions. The Predictive Analytics World Healthcare program will feature sessions and case studies across Healthcare Business Operations and Clinical applications so you can witness how data science and machine learning are employed at leading enterprises, resulting in improved outcomes, lower costs, and higher patient satisfaction. Predictive Analytics World for Industry 4.0 is the leading vendor-neutral conference for machine learning for smart manufacturing and IoT. Data scientists, industrial planners, and other machine learning experts will meet in Las Vegas to explore the latest trends and technologies in machine & deep learning for the IoT era. Deep Learning World is the premier conference covering the commercial deployment of deep learning. The event’s mission is to foster breakthroughs in the value-driven operationalization of established deep learning methods.
Attend any or all of the five jointly scheduled events! Get an additional 15% discount on your booking with the code RBLOGGERSMLW . Join us in Las Vegas for the largest Predictive Analytics World event to date! Learn more