Most of the useful data in the world, from economic data to news content to geographic information, lives somewhere on the internet – and this course will teach you how to access it. You’ll explore how to work with APIs (computer-readable interfaces to websites), access data from Wikipedia and other sources, and build your own simple API client. For those occasions where APIs are not available, you’ll find out how to use R to scrape information out of web pages. In the process, you’ll learn how to get data out of even the most stubborn website, and how to turn it into a format ready for further analysis. The packages you’ll use and learn your way around are
rvest, httr, xml2 and jsonlite, along with particular API client packages like WikipediR and pageviews.Take me to chapter 1!
Working with Web Data in R features interactive exercises that combine high-quality video, in-browser coding, and gamification for an engaging learning experience that will make you an expert in getting information from the Internet!

What you’ll learn
1. Downloading Files and Using API Clients
Sometimes getting data off the internet is very, very simple – it’s stored in a format that R can handle and just lives on a server somewhere, or it’s in a more complex format and perhaps part of an API but there’s an R package designed to make using it a piece of cake. This chapter will explore how to download and read in static files, and how to use APIs when pre-existing clients are available.
2. Using
httr to interact with APIs directlyIf an API client doesn’t exist, it’s up to you to communicate directly with the API. But don’t worry, the package
httr makes this really straightforward. In this chapter, you’ll learn how to make web requests from R, how to examine the responses you get back and some best practices for doing this in a responsible way.3. Handling JSON and XML
Sometimes data is a TSV or nice plaintext output. Sometimes it’s XML and/or JSON. This chapter walks you through what JSON and XML are, how to convert them into R-like objects, and how to extract data from them. You’ll practice by examining the revision history for a Wikipedia article retrieved from the Wikipedia API using
httr, xml2 and jsonlite.4. Web scraping with XPATHs
Now that we’ve covered the low-hanging fruit (“it has an API, and a client”, “it has an API”) it’s time to talk about what to do when a website doesn’t have any access mechanisms at all – when you have to rely on web scraping. This chapter will introduce you to the
rvest web-scraping package, and build on your previous knowledge of XML manipulation and XPATHs.5. ECSS Web Scraping and Final Case Study
CSS path-based web scraping is a far-more-pleasant alternative to using XPATHs. You’ll start this chapter by learning about CSS, and how to leverage it for web scraping. Then, you’ll work through a final case study that combines everything you’ve learnt so far to write a function that queries an API, parses the response and returns data in a nice form.
Master web data in R with our course Working with Web Data in R!
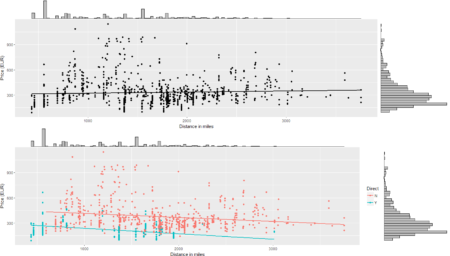 To conclude the 4-step (flight) trip from data acquisition to data analysis, let's recap the most important concepts described in each of the post:
1)
To conclude the 4-step (flight) trip from data acquisition to data analysis, let's recap the most important concepts described in each of the post:
1) 
 The collection of example flight data in json format available in
The collection of example flight data in json format available in 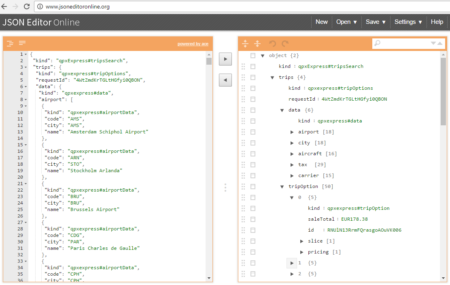 However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions:
However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions: