Changing Your Viewpoint for Factors
In real life, data tends to follow some patterns but the reasons are not apparent right from the start of the data analysis. Taking a common example of a demographics based survey, many people will answer questions in a particular ‘way’. For example, all married men will have higher expenses than single men but lower than married men with children. In this case, the driving factor which makes them answer following a pattern is the economic status but these answers may also depend on other factors such as level of education, salary and locality or area. It becomes complicated to assign answers related to multiple factors. One option is to map variables or answers to one of the factors. This process has a lot of drawbacks such as the requirement to ‘guess’ the number of factors, heuristic based or biased manual assignment and non-consideration of influence of other factors to the variable. We have variables and answers in the data defined in a way such that we can understand them and interpret. What if we change our view lens in an alternate reality where all variables are automatically mapped into different new categories with customized weight based on their influence on that category. This is the idea behind factor analysis.Creating Meaningful Factors
Factor analysis starts with the assumption of hidden latent variables which cannot be observed directly but are reflected in the answers or variables of the data. It also makes the assumption that there are as many factors as there are variables. We then transform our current set of variables into an equal number of variables such that each new variable is a combination of the current ones in some weightage. Hence, we are not essentially adding or removing information in this step but only transforming it. A typical way to make this transformation is to use eigenvalues and eigenvectors. We transform our data in the direction of each eigenvector and represent all the new variables or ‘factors’ using the eigenvalues. An eigenvalue more than 1 will mean that the new factor explains more variance than one original variable. We then sort the factors in decreasing order of the variances they explain. Thus, the first factor will be the most influential factor followed by the second factor and so on. This also helps us think of variable reduction by removing the last few factors. Typically we take factors which collectively explain 90-99% of the variance depending upon the dataset and problem. Thus, there is no need to guess the number of factors required for the data. However, we need to read into each of the factors and the combination of original features out of which they are made of to understand what they represent.Loading Factors With Factor Loadings
As I mentioned, even after transformation, we retain the weight of each original feature that were combined to obtain the factor. These weights are known as ‘factor loadings’ and help understand what the factors represent. Let’s take a cooked up example of factor loadings for an airlines survey. Let’s say the table looks like this:
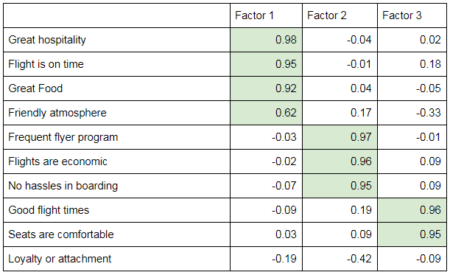
I took 10 features originally so it should generate 10 factors. Let’s say our first three factors are as shown in the table. Looking at the values of the factors, the first factor may represent customer experience post on-boarding. The second factor reflects the airline booking experience and related perks. The third factor shows the flight competitive advantage of the airline compared to its competition. We also have a 10th feature which is negatively affecting the second factor (which seems to make sense as a loyal customer will book flights even if they are no longer economic or don’t have as great frequent flyer programs). Thus, we can now understand that the top most important factors for customers filling the survey are customer experience, booking experience and competitive advantage. However, this understanding needs to be developed manually by looking at the loadings. It is the factor loadings and their understanding which are the prime reason which makes factor analysis of such importance followed by the ability to scale down to a few factors without losing much information.
Exploration – How Many Factors?
Factor analysis can be driven by different motivations. One objective of factor analysis can be verifying with the data with what you already know and think about it. This requires a prior intuition on the number of important factors after which the loadings will be low overall as well as an idea of the loadings of each original variable in those factors. This is the confirmatory way of factor analysis where the process is run to confirm with understanding of the data. A more common approach is to understand the data using factor analysis. In this case, you perform factor analysis first and then develop a general idea of what you get out of the results. How do we stop at a specific number of factor in factor analysis when we are exploring? We use the scree plot in this case. The scree plot maps the factors with their eigenvalues and a cut-off point is determined wherever there is a sudden change in the slope of the line.Going Practical – The BFI Dataset in R
Let’s start with a practical demonstration of factor analysis. We will use the Psych package in R which is a package for personality, psychometric, and psychological research. It consists a dataset – the bfi dataset which represents 25 personality items with 3 additional demographics for 2800 data points. The columns are already classified into 5 factors thus their names start with letters A (Agreeableness), C (Conscientiousness), E (Extraversion), N (Neuroticism) and O (Openness). Let’s perform factor analysis to see if we really have the same association of the variables with each factor.#Installing the Psych package and loading it
install.packages("psych")
library(psych)
#Loading the dataset
bfi_data=bfi
Though we have NA values in our data which need to be handled but we will not perform much processing on the data. To make things simple, we will only take those data points where there are no missing values.
#Remove rows with missing values and keep only complete cases bfi_data=bfi_data[complete.cases(bfi_data),]This leaves us with 2236 data points down from 2800 which means a reduction of 564 data points. Since 2236 is still a plausible number of data points, we can proceed further. We will use the fa() function for factor analysis and need to calculate the correlation matrix for the function
#Create the correlation matrix from bfi_data bfi_cor <- cor(bfi_data)The fa() function needs correlation matrix as r and number of factors. The default value is 1 which is undesired so we will specify the factors to be 6 for this exercise.
#Factor analysis of the data factors_data <- fa(r = bfi_cor, nfactors = 6) #Getting the factor loadings and model analysis factors_data Factor Analysis using method = minres Call: fa(r = bfi_cor, nfactors = 6)Standardized loadings (pattern matrix) based upon correlation matrix
MR2 MR3 MR1 MR5 MR4 MR6 h2 u2 com
A1 0.11 0.07 -0.07 -0.56 -0.01 0.35 0.379 0.62 1.8
A2 0.03 0.09 -0.08 0.64 0.01 -0.06 0.467 0.53 1.1
A3 -0.04 0.04 -0.10 0.60 0.07 0.16 0.506 0.49 1.3
A4 -0.07 0.19 -0.07 0.41 -0.13 0.13 0.294 0.71 2.0
A5 -0.17 0.01 -0.16 0.47 0.10 0.22 0.470 0.53 2.1
C1 0.05 0.54 0.08 -0.02 0.19 0.05 0.344 0.66 1.3
C2 0.09 0.66 0.17 0.06 0.08 0.16 0.475 0.53 1.4
C3 0.00 0.56 0.07 0.07 -0.04 0.05 0.317 0.68 1.1
C4 0.07 -0.67 0.10 -0.01 0.02 0.25 0.555 0.45 1.3
C5 0.15 -0.56 0.17 0.02 0.10 0.01 0.433 0.57 1.4
E1 -0.14 0.09 0.61 -0.14 -0.08 0.09 0.414 0.59 1.3
E2 0.06 -0.03 0.68 -0.07 -0.08 -0.01 0.559 0.44 1.1
E3 0.02 0.01 -0.32 0.17 0.38 0.28 0.507 0.49 3.3
E4 -0.07 0.03 -0.49 0.25 0.00 0.31 0.565 0.44 2.3
E5 0.16 0.27 -0.39 0.07 0.24 0.04 0.410 0.59 3.0
N1 0.82 -0.01 -0.09 -0.09 -0.03 0.02 0.666 0.33 1.1
N2 0.83 0.02 -0.07 -0.07 0.01 -0.07 0.654 0.35 1.0
N3 0.69 -0.03 0.13 0.09 0.02 0.06 0.549 0.45 1.1
N4 0.44 -0.14 0.43 0.09 0.10 0.01 0.506 0.49 2.4
N5 0.47 -0.01 0.21 0.21 -0.17 0.09 0.376 0.62 2.2
O1 -0.05 0.07 -0.01 -0.04 0.57 0.09 0.357 0.64 1.1
O2 0.12 -0.09 0.01 0.12 -0.43 0.28 0.295 0.70 2.2
O3 0.01 0.00 -0.10 0.05 0.65 0.04 0.485 0.52 1.1
O4 0.10 -0.05 0.34 0.15 0.37 -0.04 0.241 0.76 2.6
O5 0.04 -0.04 -0.02 -0.01 -0.50 0.30 0.330 0.67 1.7
gender 0.20 0.09 -0.12 0.33 -0.21 -0.15 0.184 0.82 3.6
education -0.03 0.01 0.05 0.11 0.12 -0.22 0.072 0.93 2.2
age -0.06 0.07 -0.02 0.16 0.03 -0.26 0.098 0.90 2.0
MR2 MR3 MR1 MR5 MR4 MR6
SS loadings 2.55 2.13 2.14 2.03 1.79 0.87
Proportion Var 0.09 0.08 0.08 0.07 0.06 0.03
Cumulative Var 0.09 0.17 0.24 0.32 0.38 0.41
Proportion Explained 0.22 0.18 0.19 0.18 0.16 0.08
Cumulative Proportion 0.22 0.41 0.59 0.77 0.92 1.00
With factor correlations of
MR2 MR3 MR1 MR5 MR4 MR6
MR2 1.00 -0.18 0.24 -0.05 -0.01 0.10
MR3 -0.18 1.00 -0.23 0.16 0.19 0.04
MR1 0.24 -0.23 1.00 -0.28 -0.19 -0.15
MR5 -0.05 0.16 -0.28 1.00 0.18 0.17
MR4 -0.01 0.19 -0.19 0.18 1.00 0.05
MR6 0.10 0.04 -0.15 0.17 0.05 1.00
Mean item complexity = 1.8
Test of the hypothesis that 6 factors are sufficient.
The degrees of freedom for the null model are 378 and the objective function was 7.79
The degrees of freedom for the model are 225 and the objective function was 0.57
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
Fit based upon off diagonal values = 0.98
Measures of factor score adequacy
MR2 MR3 MR1 MR5 MR4 MR6
Correlation of (regression) scores with factors 0.93 0.89 0.89 0.88 0.86 0.77
Multiple R square of scores with factors 0.86 0.79 0.79 0.77 0.74 0.59
Minimum correlation of possible factor scores 0.72 0.57 0.58 0.54 0.49 0.18
The factor loadings show that the first factor represents N followed by C,E,A and O. This means most of the members in the data have Neuroticism in the data. We also notice that the first five factors adequately represent the factor categories as the data is meant for.
Conclusion: A Deeper Insight
As apparent from the bfi survey example, factor analysis is helpful in classifying our current features into factors which represent hidden features not measured directly. It also has an additional advantage of helping reduce our data into a smaller set of features without losing much information. There are a few things to keep in mind before putting factor analysis into action. The first is about the values of factor loadings. We may have datasets where the factor loadings for all factors are low – lower than 0.5 or 0.3. While a factor loading lower than 0.3 means that you are using too many factors and need to re-run the analysis with lesser factors. A range of loadings around 0.5 is satisfactory but indicates poor predicting ability. You should later keep thresholds and discard factors which have a loading lower than the threshold for all features. Factor analysis on dynamic data can also be helpful in tracking changes in the nature of data. In case the data changes significantly, the number of factors in exploratory factor analysis will also change and indicate you to look into the data and check what changes have occurred. The final one of importance is the interpretability of factors. In case you are unable to understand or explain the factor loadings, you are either using a very granular or very generalized set of factors. In this case, you need to find the right number of factors and obtain loadings to features which are both interpretable and beneficial for analysis. There can be a variety of other situations that may occur with factor analysis and are all subject to interpretation.Keep learning and here is the entire code used in this article.
#Installing the Psych package and loading it
install.packages("psych")
library(psych)
#Loading the dataset
bfi_data=bfi
#Remove rows with missing values and keep only complete cases
bfi_data=bfi_data[complete.cases(bfi_data),]
#Create the correlation matrix from bfi_data
bfi_cor <- cor(bfi_data)
#Factor analysis of the data
factors_data <- fa(r = bfi_cor, nfactors = 6)
#Getting the factor loadings and model analysis
factors_data
Author Bio:
This article was contributed by Perceptive Analytics. Madhur Modi, Prudhvi Sai Ram, Saneesh Veetil and Chaitanya Sagar contributed to this article.Perceptive Analytics provides Tableau Consulting, data analytics, business intelligence and reporting services to e-commerce, retail, healthcare and pharmaceutical industries. Our client roster includes Fortune 500 and NYSE listed companies in the USA and India.