Join our workshop on Tabular ML in R: an overview of tidymodels in R for tabularized data, which is a part of our workshops for Ukraine series!
Here’s some more info:
Title: Tabular ML in R: an overview of tidymodels in R for tabularized data
Date: Thursday, February 20th, 18:00 – 20:00 CET (Rome, Berlin, Paris timezone)
Speaker: Frank Hull is currently Director of Analytics at ACES. Frank oversees ACES’ Data Science department, which works directly with Portfolio Strategy, Portfolio Modeling, Transmission, Resource Planning, Fundamentals, and Trading & Operations. Frank leads & advises various initiatives such as weather-driven stochastics (WDS), long-term load forecasting (LTLF), peak prediction services (PPS), dark calm (DC) and extreme weather event (EWE) analyses. Frank also hosts internal R meetings for programmers at ACES. Prior to his current role, Frank held various roles related to data science, systems, modeling, and quantitative analysis at AES & ACES. Frank holds a degree in physics with a concentration in engineering physics.
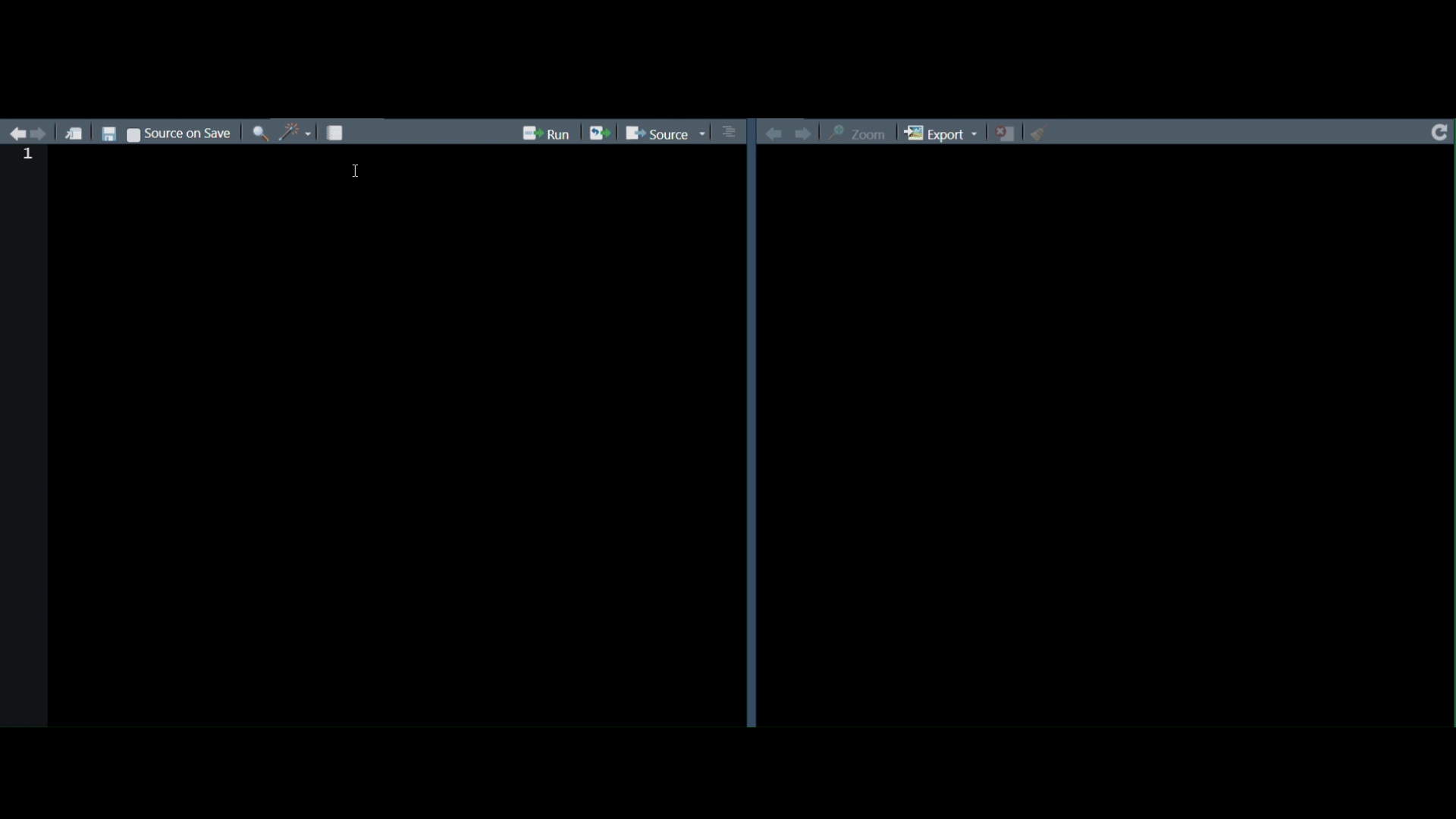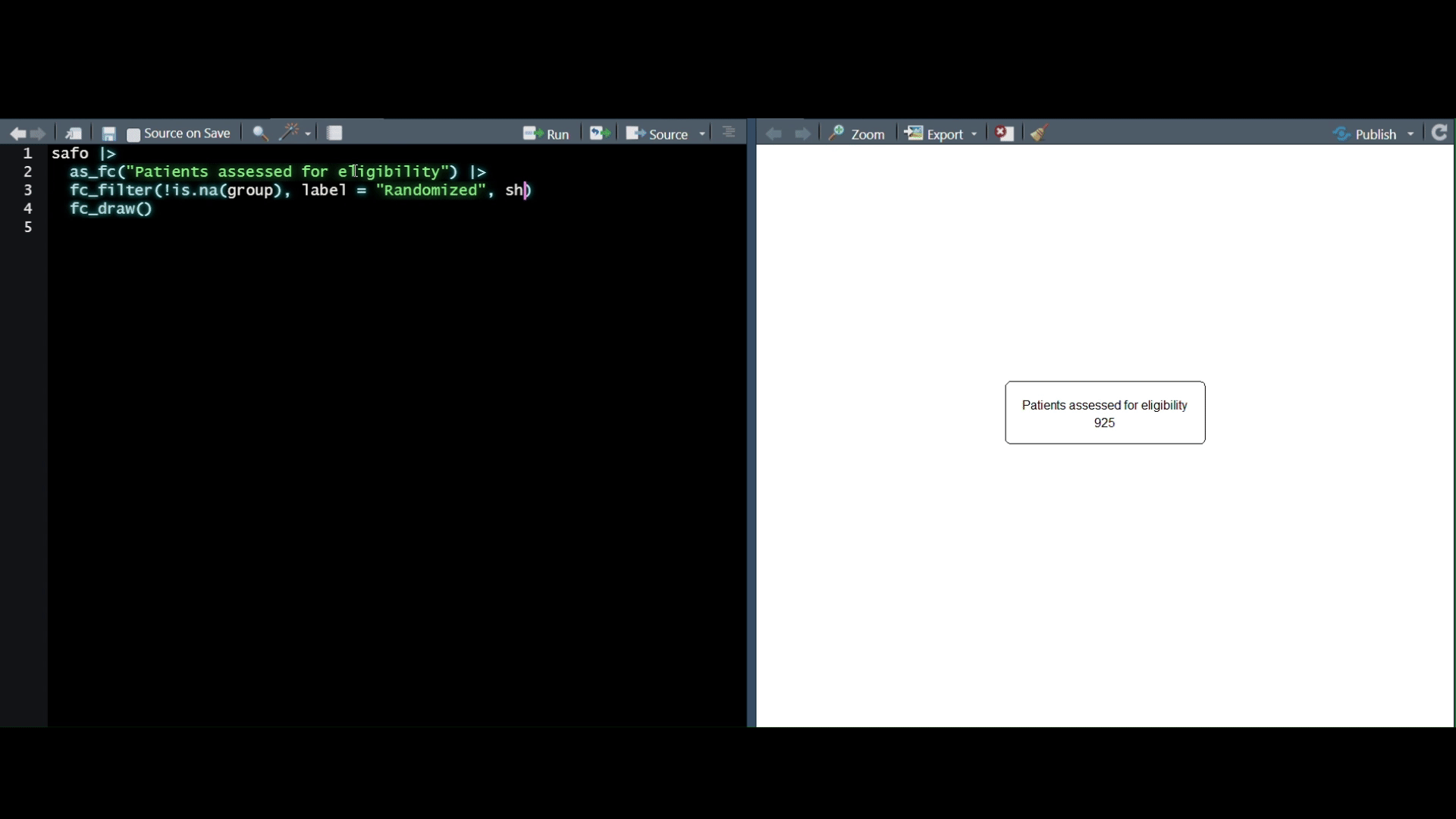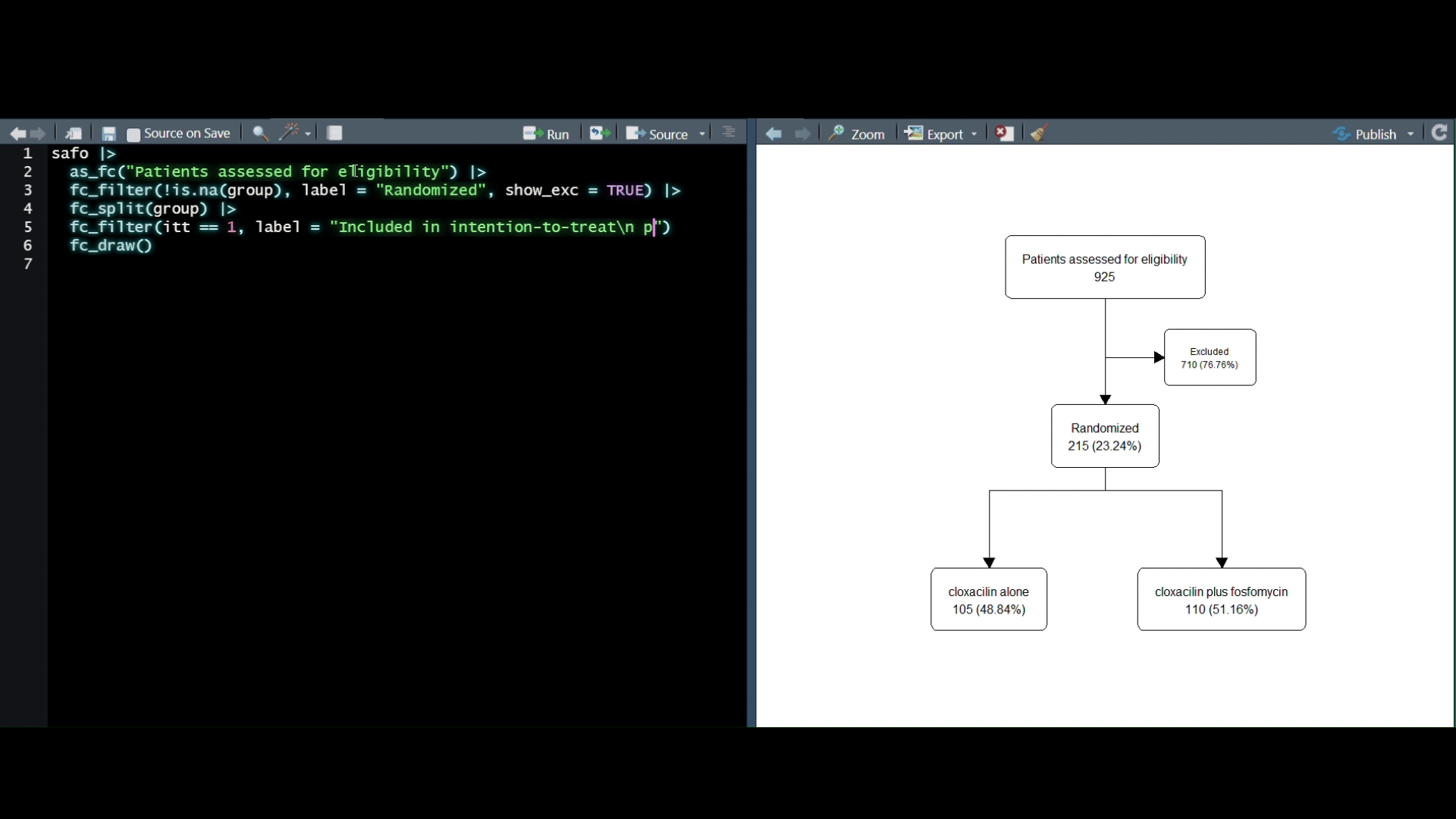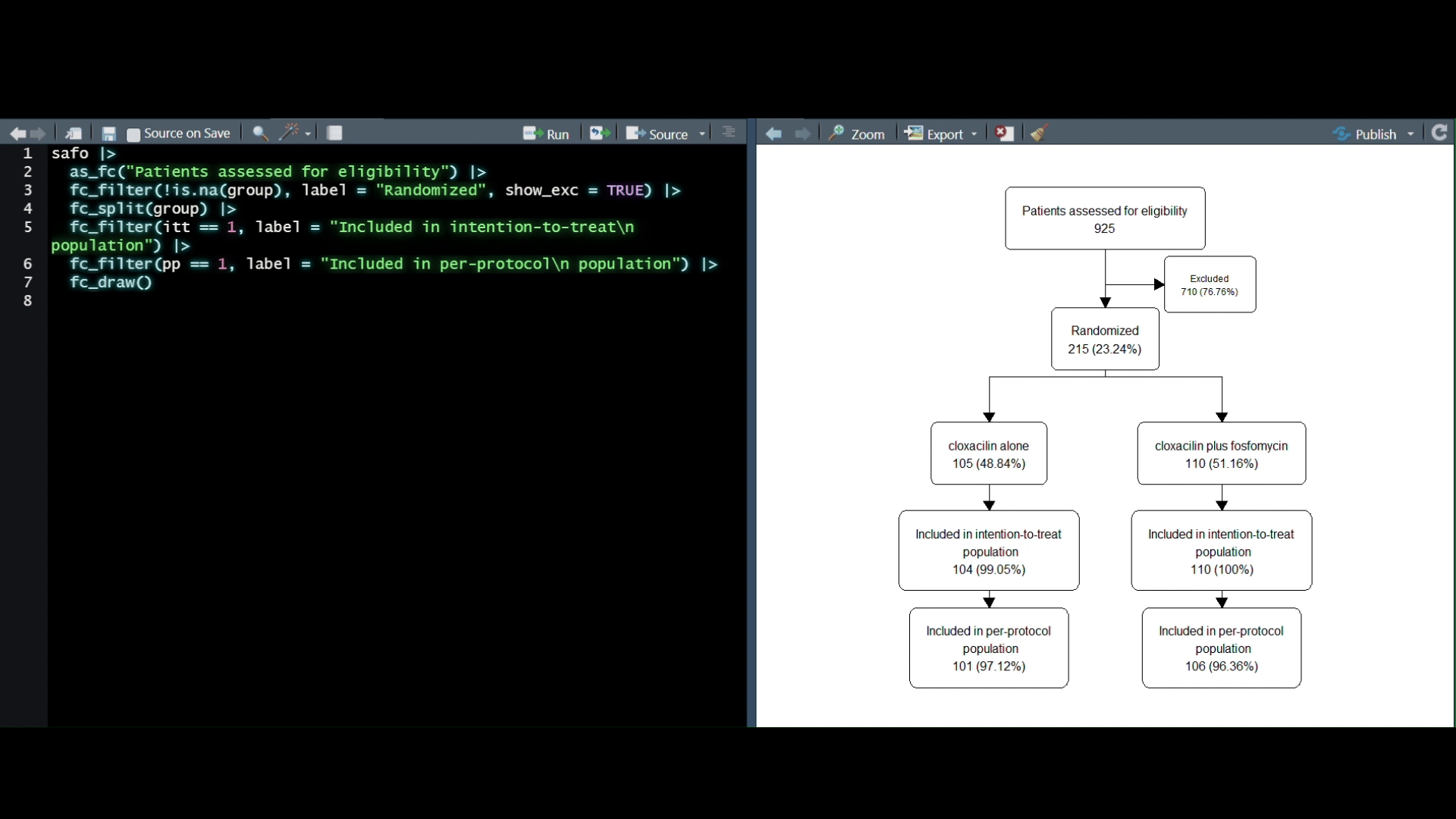
Description: In this workshop, we will 1) discuss what we mean by tabular ml in R, 2) why it’s important, 3) when can it be applicable, and 4) how to setup a robust pipeline for iterative machine learning workflows. We will start off by defining and discussing the prevalence of tabular data across sectors. Followed by data exploration to understand and interpret any known relationships with our example dataset. Lastly, we will establish key practices within the
tidymodels ecosystem to create a predictive framework and benchmark various ML engines.
Minimal registration fee: 20 euro (or 20 USD or 800 UAH)
How can I register?
- Go to https://bit.ly/3wvwMA6 or https://bit.ly/4aD5LMC or https://bit.ly/3PFxtNA and donate at least 20 euro. Feel free to donate more if you can, all proceeds go directly to support Ukraine.
- Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
- Fill in the registration form, attaching a screenshot of a donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after donation).
If you are not personally interested in attending, you can also contribute by sponsoring a participation of a student, who will then be able to participate for free. If you choose to sponsor a student, all proceeds will also go directly to organisations working in Ukraine. You can either sponsor a particular student or you can leave it up to us so that we can allocate the sponsored place to students who have signed up for the waiting list.
How can I sponsor a student?
- Go to https://bit.ly/3wvwMA6 or https://bit.ly/4aD5LMC or https://bit.ly/3PFxtNA and donate at least 20 euro (or 17 GBP or 20 USD or 800 UAH). Feel free to donate more if you can, all proceeds go to support Ukraine!
- Save your donation receipt (after the donation is processed, there is an option to enter your email address on the website to which the donation receipt is sent)
- Fill in the sponsorship form, attaching the screenshot of the donation receipt (please attach the screenshot of the donation receipt that was emailed to you rather than the page you see after the donation). You can indicate whether you want to sponsor a particular student or we can allocate this spot ourselves to the students from the waiting list. You can also indicate whether you prefer us to prioritize students from developing countries when assigning place(s) that you sponsored.
If you are a university student and cannot afford the registration fee, you can also sign up for the waiting list here. (Note that you are not guaranteed to participate by signing up for the waiting list).
You can also find more information about this workshop series, a schedule of our future workshops as well as a list of our past workshops which you can get the recordings & materials here.
Looking forward to seeing you during the workshop!