Why & how automl package
- automl package provides:
- Deep Learning last tricks (those who have taken Andrew NG’s MOOC on Coursera will be in familiar territory)
- hyperparameters autotune with metaheuristic (PSO)
- experimental stuff and more to come (you’re welcome as coauthor!)
Deep Learning existing frameworks, disadvantages
Deploying and maintaining most Deep Learning frameworks means: Python…
R language is so simple to install and maintain in production environments that it is obvious to use a pure R based package for deep learning !
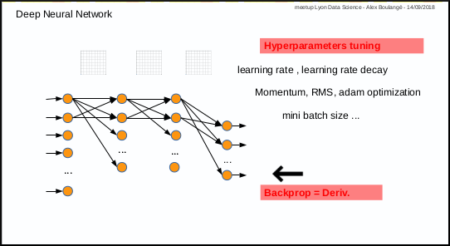
Neural Network – Deep Learning, disadvantages
- Disadvantages:
- 1st disadvantage: you have to test manually different combinations of parameters (number of layers, nodes, activation function, etc …) and then also tune manually hyper parameters for training (learning rate, momentum, mini batch size, etc …)
- 2nd disadvantage: only for those who are not mathematicians, calculating derivative in case of new cost or activation function, may by an issue.
Metaheuristic – PSO, benefits
The Particle Swarm Optimization algorithm is a great and simple one.
In a few words, the first step consists in throwing randomly a set of particles in a space and the next steps consist in discovering the best solution while converging.
video tutorial from Yarpiz is a great ressource
Birth of automl package
automl package was born from the idea to use metaheuristic PSO to address the identified disadvantages above.
And last but not the least reason: use R and R only 🙂
- 3 functions are available:
- automl train manual: the manual mode to train a model
- automl train: the automatic mode to train model
- automl predict: the prediction function to apply a trained model on datas
Mix 1: hyperparameters tuning with PSO
Mix 1 consists in using PSO algorithm to optimize the hyperparameters: each particle corresponds to a set of hyperparameters.
The automl train function was made to do that.
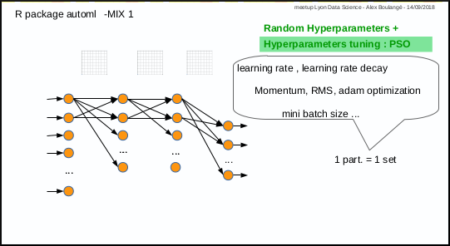
nb: parameters (nodes number, activation functions, etc…) are not automatically tuned for the moment, but why not in the futur
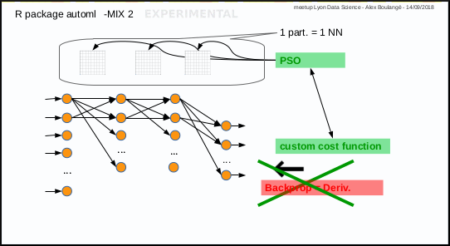
Mix 2: PSO instead of gradient descent
Mix 2 is experimental, it consists in using PSO algorithm to optimize the weights of Neural Network in place of gradient descent: each particle corresponds to a set of neural network weights matrices.
The automl train manual function do that too.
Next post
We will see how to use it in the next post.
Feel free to comment or join the team being formed
Excellent.. can’t wait for more details. I’ve already read the vignette and hoping to get a more detailed or meaty example. Maybe a kaggle data set?
Very good point Ankur, I’ve just join the ‘two sigma’ Kaggle’s competition. I hope data preparation won’t be to costy: if you’ve already prepared something in R let’s share our Kernel and test automl in real life
Hi Ankur, ‘two sigma’ Kaggle’s competition was only for Python kernel …
The ‘Google Analytics Customer Revenue Prediction’ one wasn’t and I get a bronze medal, top 10% with pure automl 😉
Awesome initiative!! Waiting for the 2nd part to test it. Thanks to incredible people like you for sharing their valuable work 🙂
Thanks Bernardo