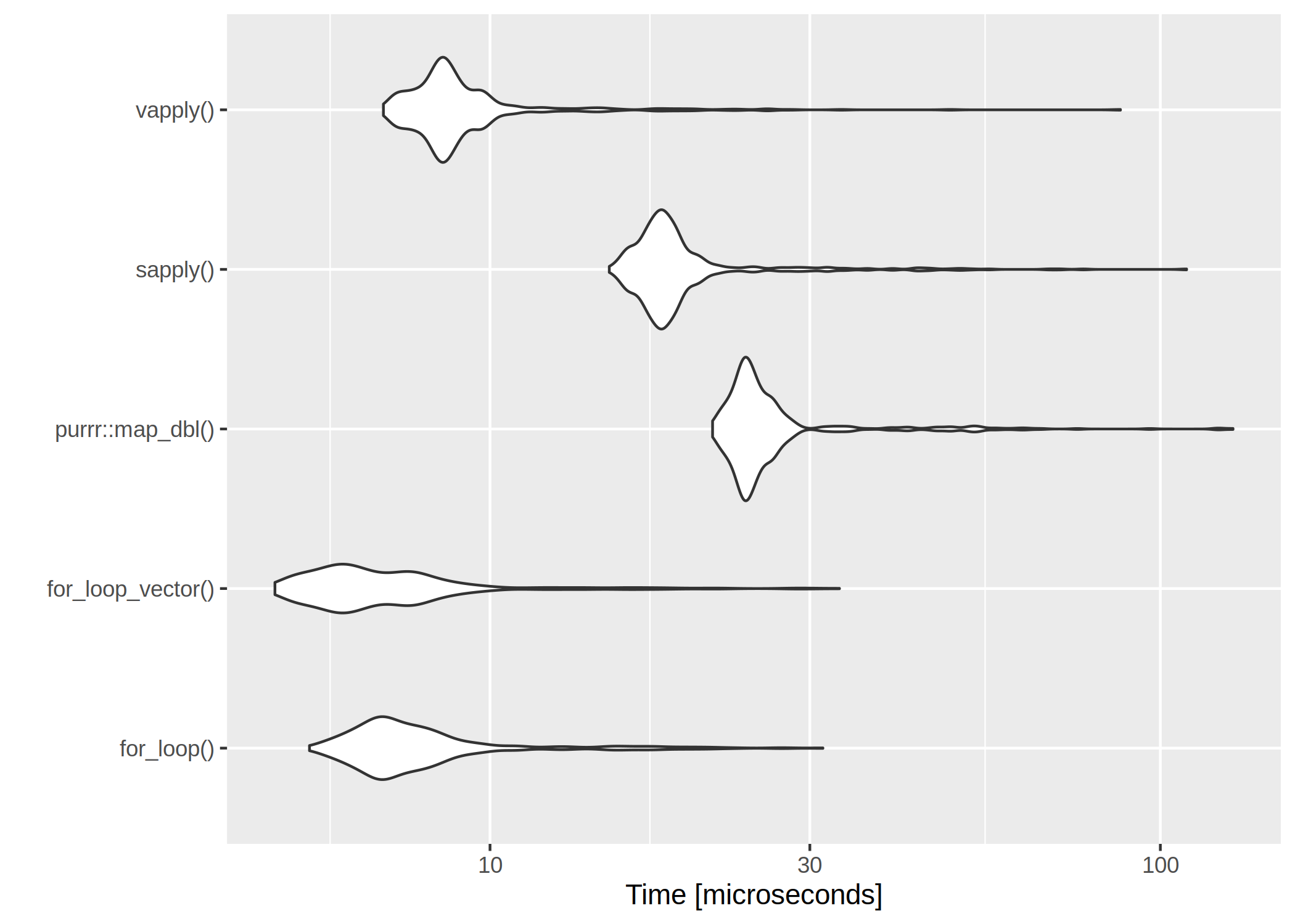
It is usually said, that for– and while-loops should be avoided in R. I was curious about just how the different alternatives compare in terms of speed.
The first loop is perhaps the worst I can think of – the return vector is initialized without type and length so that the memory is constantly being allocated.
use_for_loop <- function(x){
y <- c()
for(i in x){
y <- c(y, x[i] * 100)
}
return(y)
}
The second for loop is with preallocated size of the return vector.
The clear winner is vapply() and for-loops are rather slow. However, if we have a very low number of iterations, even the worst for-loop isn’t too bad:
In my daily work I often have to transform a long table to a wide matrix so accommodate some function. At some stage in my life I came across the reshape2 package, and I have been with that philosophy ever since – I find it makes data wrangling easy and straight forward. I particularly like the tidyverse philosophy where data should be in a long table, where one row is an observation, and a column a parameter. It just makes sense.
However, I quite often have to transform the data into another format, a wide matrix especially for functions of the vegan package, and one day I wondering how to do that in the fastest way.
The code to create the test sets and benchmark the functions is in section ‘Settings and script’ at the end of this document.
I created several data sets that mimic the data I usually work with in terms of size and values. The data sets have 2 to 10 groups, where each group can have up to 50000, 100000, 150000, or 200000 samples. The methods xtabs() from base R, dcast() from data.table, dMcast() from Matrix.utils, and spread() from tidyr were benchmarked using microbenchmark() from the package microbenchmark. Each method was evaluated 10 times on the same data set, which was repeated for 10 randomly generated data sets.
After the 10 x 10 repetitions of casting from long to wide it is clear the spread() is the worst. This is clear when we focus on the size (figure 1). Figure 1. Runtime for 100 repetitions of data sets of different size and complexity.
And the complexity (figure 2). Figure 2. Runtime for 100 repetitions of data sets of different complexity and size.
Close up on the top three methods
Casting from a long table to a wide matrix is clearly slowest with spread(), where as the remaining look somewhat similar. A direct comparison of the methods show a similarity in their performance, with dMcast() from the package Matrix.utils being better — especially with the large and more complex tables (figure 3). Figure 3. Direct comparison of set size.
I am aware, that it might be to much to assume linearity, between the computation times at different set sizes, but I do believe it captures the point – dMcast() and dcast() are similar, with advantage to dMcast() for large data sets with large number of groups. It does, however, look like dcast() scales better with the complexity (figure 4). Figure 4. Direct comparison of number groups.
— A basic R-phile introduction to continuous integration on GitLab
I have been using the GitLab repository for some time for mainly two reasons: I can have private projects at no monetary costs (I later came to realise that I as an academic can have the same on GitHub), and most importantly GitLab has so far gone under the radar of our IT department, meaning I can access it from my work computer. GitHub on the other hand is flagged as file sharing.
A simple CI config
Most of my time with R is spend trying to make heads and tails of various kinds of data, and I have so far just authored one R-package. While I can see the benefits of a continuous integration (CI) work flow, I just never bothered to actually set it up. Now where I am putting together code in smaller packages for internal use, it seemed like the right time to learn a little.
The Internet gives a few pointers on how to go about setting up CI on GitLab; one of the resources is the blog post Docker, GitLab CI and Developing R Packages by Mustafa Hasanbulli, who gives a simple .gitlab-ci.yml for testing packages. Mustafa’s solution make use of the rocker/tidyverse Docker image and install the dependency packages before running check() from devtools. It’s a good solution and combining with the .gitlab-ci.yml shared as a gist on Github by Artem Klevtsov, I managed to get the coverage badge I though nice to have. The .gitlab-ci.yml for a smaller package can be along the lines of:
image: rocker/tidyverse
stages:
- check
- coverage
check_pkg:
stage: check
script:
- R -e 'install.packages(c())'
- R -e 'devtools::check()'
coverage:
stage: coverage
script:
- R -e 'covr::package_coverage(type = c("tests", "examples"))'
To extract the coverage to the coverage badge, add Coverage: \d+.\d+%$ to the section ‘Test coverage parsing’ in Settings -> CI/CD -> General pipelines.
Introducing cache
For my package, each of the two stages took about 45 minutes to complete, and I realized that the wast majority of the time was spent on downloading and especially installing packages. This was mainly do to the Bioconductor packages I rely on.
If only there would be a way to pass the installed packages between the stages, or even between runs of the CI pipeline. There is – GitLab 9.0 saw the option to specify a cache. The next problem is that the cache must be a directory of the cloned project directory. Since R prefers to install packages in /usr/lib/R/library in the Docker images, the .libpaths() must be changed. In addition you would have to remember to add any new package to the .gitlab-ci.yml. Which I for one would always forget, and therefore painstakingly have to figure out which packages to add.
A much simpler solution is to use packrat – something you anyway should consider to use. It also allows you to use the rocker/r-base image and just the packages actually required for your CI. How much of a win in terms of traffic rocker/r-base is over rocker/tidyverse probably depends on the packages you have to add. The .gitlab-ci.yml caching packages could look like this:
image: rocker/r-base
stages:
- setup
- test
cache:
# Ommit key to use the same cache across all pipelines and branches
key: "$CI_COMMIT_REF_SLUG"
paths:
- packrat/lib/
setup:
stage: setup
script:
- R -e 'source("ci.R"); ci_setup()'
check:
stage: test
dependencies:
- setup
when: on_success
script:
- R -e 'source("ci.R"); ci_check()'
coverage:
stage: test
dependencies:
- setup
when: on_success
only:
- master
script:
- R -e 'source("ci.R"); ci_coverage()'
The cache key $CI_COMMIT_REF_SLUG gives you the advantage of different cache for different branches. Using $CI_COMMIT_SHA will give you a separate cache for each commit.
Adding the packrat subdirectories src and lib* to the .gitignore will keep your repository small – and I find it quite useful to commit just the packrat.lock whenever I add or remove a package. But then again, I am the only one working with my repositories, and there might be advantages I don’t know of.
I have noticed that the stages after the setup stage sometimes fail in the first run. If this happens because of the cache, rerunning the failed stage makes everything well.
Using the above for my package, the first run of the pipeline took about 45 minutes, but the second run only about 8 minutes. A considerable reduction in time.
I hope .gitlab-ci.yml and ci.R outlined here will help you getting started on caching your R-packages in your CI. The two modules are quite simple, and if you are loking for something more sophisticated, I can recommend looking Matt Dowle works on data.table and of course the GitLab Runner help pages.
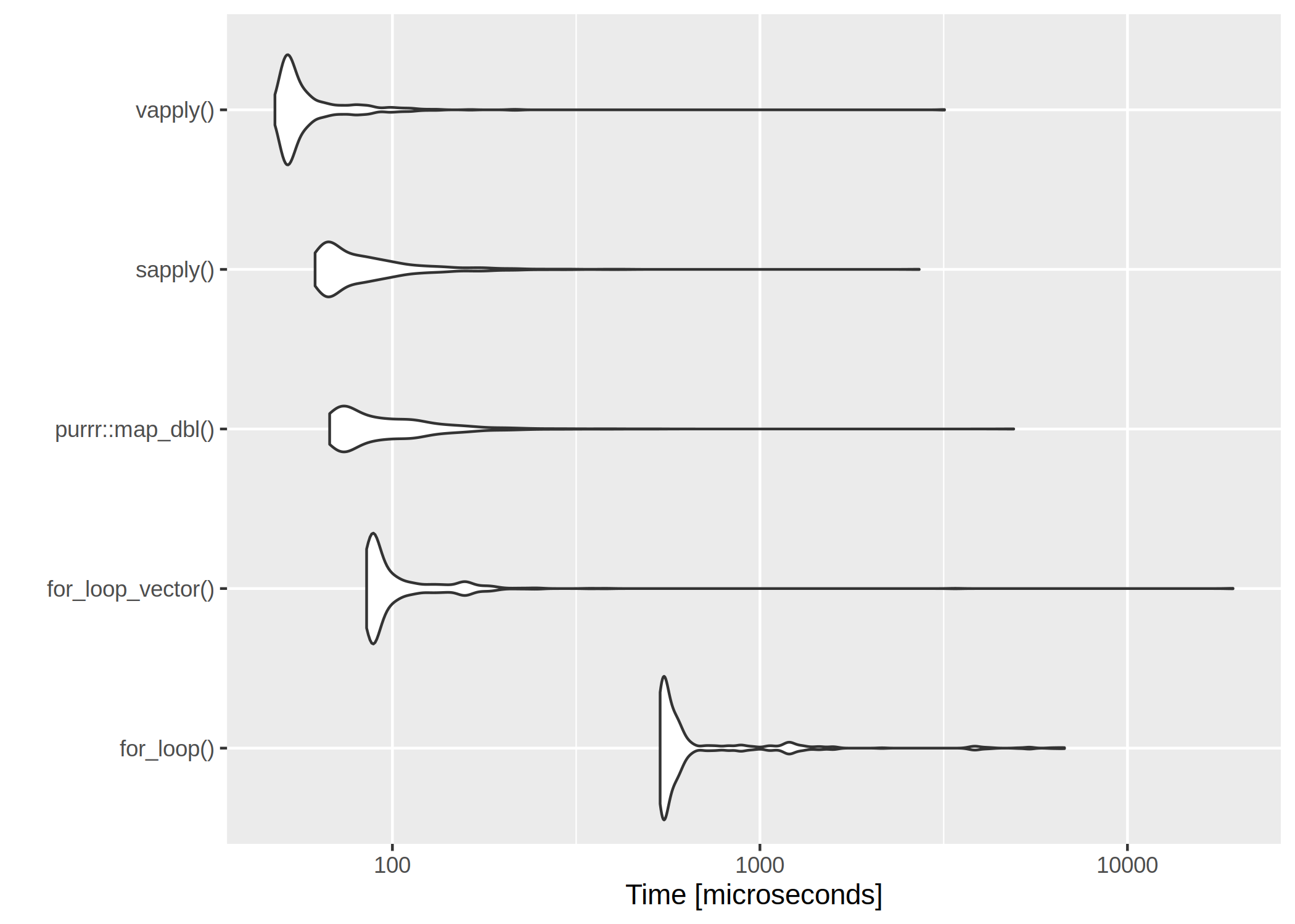 The clear winner is vapply() and for-loops are rather slow. However, if we have a very low number of iterations, even the worst for-loop isn’t too bad:
The clear winner is vapply() and for-loops are rather slow. However, if we have a very low number of iterations, even the worst for-loop isn’t too bad: