After the short presentation
here, let’s start using R seriously, i.e. with every day data.
Being a frequent flyer, I often search the web to book flights and organise my trip. Being a data analyst, it’s natural to look at price data with interest, especially the most convenient, most expensive and “average” flights. Being a PhD student in software engineering the (study) programme includes some on the structure of applications, client-server data flows and the web languages running the processes.
Nothing like Google flight API
QPX express would have been better to combine all these three. I discovered it by chance delving into the first results of my flight searches on Google and it is perfect for some web scraping and analysis. As described in the manual, QPX Express is part of the Google suite of publicly-available
REST APIs, designed for easy integration, fast response and high reliability. QPX Express searches combinations of airline schedules, fares and seat availability and includes search parameters such as origin, destination, dates and travel features such as maximum price and earliest departure. The API returns up to 500 itineraries for each request, including all data elements needed for customer display and a booking process. Moreover, it also allows to clearly see the structure of the data in #json both in input (JSON request) and output (Unformatted Response). For a simple test, use the
Demo with a Google account.
Before start using the QPX Express API, you need to get a Google API key. To get a key, follow these steps: 1. Go to the
Google Developers Console / 2. Create or select a project / 3. Click Continue to enable the API and any related services / 4. On the Credentials page, get an
API key. With a single API key, it is possible to make 50 free requests per day (then the cost per single query is $ 0.035.)
The first thing I tried before writing the code in #R for data acquisition, manipulation and analysis was to test the
client-server connection through a command line instruction using the cURL library (you can download
here – add the certificate in the same directory otherwise the server will deny you access).
Let’s play a bit with the command line (Windows 10) before running the request:
# open the command prompt and the default folder should be system32 of the OS
C:\WINDOWS\system32>
# set a convenient current directory (cd) for storing data - \ (enter) and / (exit) the path
cd C:\Users\Roberto\Desktop
# your new position should be in
C:\Users\Roberto\Desktop>
# I prefer using a partition of the HD dedicated to data instead of a messy desktop
cd /D D:\
# create a new working directory (use "" for separated names otherwise two folders will be created)
mkdir "flight data"
# set the current directory to the newly created folder
cd "flight data"
# make sub-folders of the cd
mkdir "curl test 1"
mkdir "curl test 2"
# check the cd, its features and its new sub-folders
cd
dir
# finally, check the proper installation of curl using help
# the list of the function parameters should appear with some description
curl -help
After the creation of a repository, cURL can be used for testing the connection to QPX express and the collection of data in json using cURL parameters for HTTP requests and the structure of the JSON request the API proposes:
# Parameters
# -X POST: parameter for POST request -> see: https://en.wikipedia.org/wiki/POST_(HTTP)
# -H: Pass custom header LINE to server (H) -> see: https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
# -d: HTTP POST data, i.e. the input data in JSON structure
# >: "send to" destination file
curl -X POST "https://www.googleapis.com/qpxExpress/v1/trips/search?key={SERVER_KEY}&alt=json" -H "Content-Type: application/json; charset=UTF-8" -d "{ \"request\": { \"slice\": [ { \"origin\": \"{ORIGIN_CODE}\", \"destination\": \"{DESTINATION_CODE}\", \"date\": \"{DATE_YYYY-MM-DD}\" } ], \"passengers\": { \"adultCount\": 1, \"infantInLapCount\": 0, \"infantInSeatCount\": 0, \"childCount\": 0, \"seniorCount\": 0 }, \"solutions\": 500, \"refundable\": false }}" > "{RESULT_FILE}.json"
# Mac syntax
curl -X POST 'https://www.googleapis.com/qpxExpress/v1/trips/search?key={SERVER_KEY}&alt=json' -H 'Content-Type: application/json; charset=UTF-8' -d '{ "request": { "slice": [ { "origin": "{ORIGIN_CODE}", "destination": "{DESTINATION_CODE}", "date": "{DATE_YYYY-MM-DD}" } ], "passengers": { "adultCount": 1, "infantInLapCount": 0, "infantInSeatCount": 0, "childCount": 0, "seniorCount": 0 }, "solutions": 500, "refundable": false }}'> '{RESULT_FILE}.json'
After a second, the prompt should show the downloading process stats and a new json file should appear in the cd “flight data” close to the previously created subfolders.
The connection works!
Next up – a post with code to
translate the same commands in R – to manipulate the data comfortably after acquisition from the API.
#R #rstats #maRche #json #curl #qpxexpress #Rbloggers
This post is also shared in www.r-bloggers.com and LinkedIn 

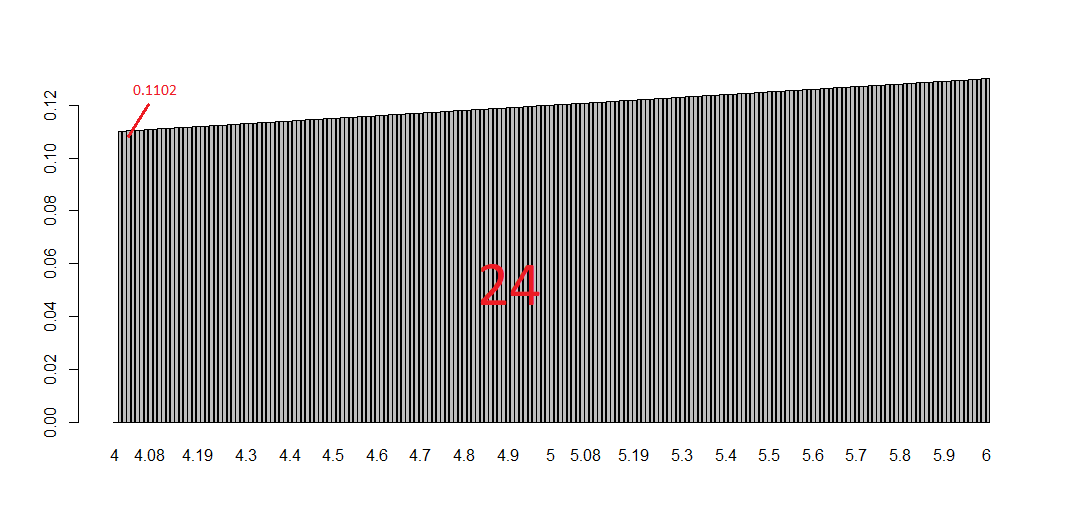

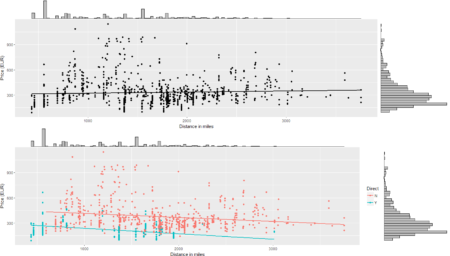 To conclude the 4-step (flight) trip from data acquisition to data analysis, let's recap the most important concepts described in each of the post:
1)
To conclude the 4-step (flight) trip from data acquisition to data analysis, let's recap the most important concepts described in each of the post:
1) 
 The collection of example flight data in json format available in
The collection of example flight data in json format available in 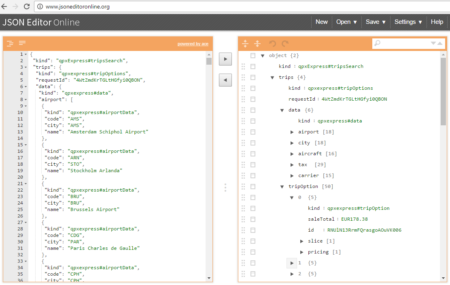 However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions:
However, looking deeply into the object, several other elements are provided as the distance in mile, the segment, the duration, the carrier, etc. The R parser to transform the json structure in a usable dataframe requires the dplyr library for using the pipe operator (%>%) to streamline the code and make the parser more readable. Nevertheless, the library actually wrangling through the lines is tidyjson and its powerful functions: